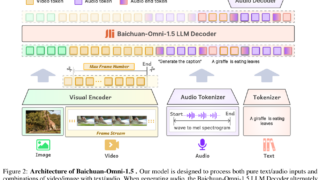
 マルチモーダル
マルチモーダル 【Baichuan-Omni-1.5】画像・音声・テキストを統合するマルチモーダルモデル
Baichuan-Omni-1.5は画像・音声・テキストを統合的に扱うマルチモーダルモデル。Visual BranchとAudio Branchを活用し、多様なデータを高精度に処理。実験では従来モデルを上回る性能を多数のベンチマークで示した。
マルチモーダル 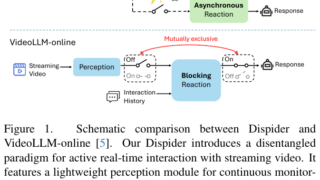 マルチモーダル
マルチモーダル  マルチモーダル
マルチモーダル  マルチモーダル
マルチモーダル 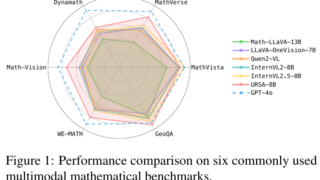 マルチモーダル
マルチモーダル 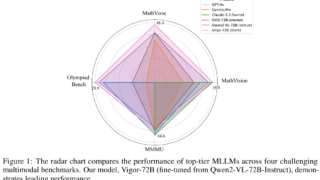 マルチモーダル
マルチモーダル  マルチモーダル
マルチモーダル  マルチモーダル
マルチモーダル 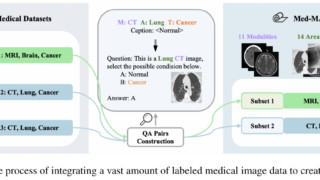 マルチモーダル
マルチモーダル  マルチモーダル
マルチモーダル