 言語・LLM
言語・LLM 長文タスクに優れたエンコーディング「TAPE」で頑健性と効率性を向上
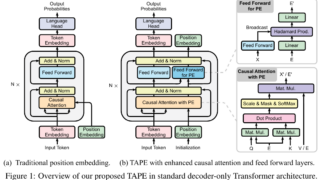
新しい位置エンコーディングフレームワーク「TAPE」を提案。モデルの頑健性と効率性を向上させ、長文タスクにおいて優れた性能を示す実験結果。効率的な処理で強力なパフォーマンスを実現。
言語・LLM 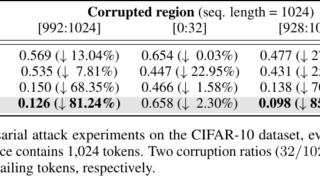 言語・LLM
言語・LLM  言語・LLM
言語・LLM  言語・LLM
言語・LLM 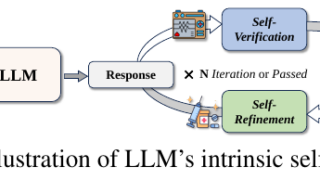 言語・LLM
言語・LLM 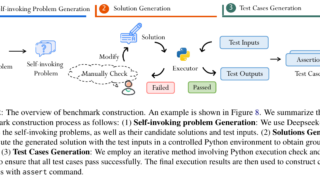 言語・LLM
言語・LLM  言語・LLM
言語・LLM 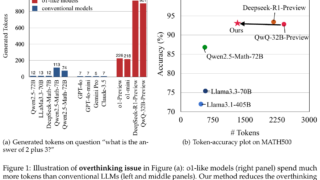 言語・LLM
言語・LLM  言語・LLM
言語・LLM  言語・LLM
言語・LLM