 画像
画像 拡散モデル効率化のアルゴリズムと評価手法
新しい検索アルゴリズムと評価フレームワークを提案し、拡散モデルの推論時間を効率化。Verifierモデルと3つの検索アルゴリズムを比較し、複数のベンチマークタスクで高品質な生成と計算時間の削減を確認。
画像  画像
画像  画像
画像 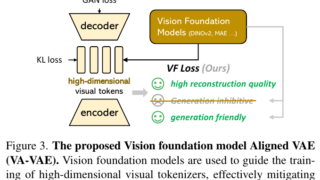 画像
画像 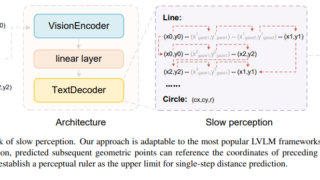 画像
画像  画像
画像  マルチモーダル
マルチモーダル  マルチモーダル
マルチモーダル  ニュース
ニュース  画像
画像