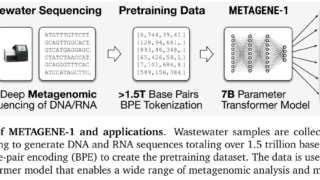
 データセット
データセット 【METAGENE-1】ウイルス検出や感染症の監視を強化するTransformer
新しいTransformerモデル「METAGENE-1」を提案し、ウイルス検出や感染症監視を強化。独自のトークン化と7億パラメータで効率的な遺伝子データ分析を実現、他モデルを上回る精度で未知の病原体も検出可能。
データセット  データセット
データセット 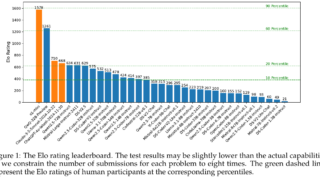 データセット
データセット 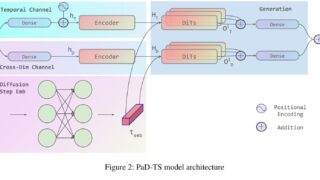 データセット
データセット  データセット
データセット 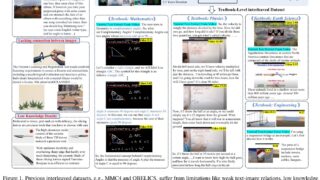 データセット
データセット  オープンソース
オープンソース