 言語・LLM
言語・LLM Transformer高速化「Lightning Attention」導入
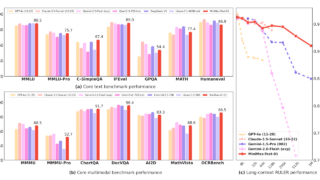
新しいTransformerアプローチ「Lightning Attention」により計算効率が大幅向上。MiniMax-01シリーズは膨大なトークンを処理し、RLHF学習によりモデルの応答品質と一貫性が向上することが判明。
言語・LLM  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース