
- AIモデルの推論をSystem-1とSystem-2に分ける新たな視点の提案
- System-1でのタスク適応とSystem-2での強力な理由づけを統合する枠組み
- 実験で柔軟かつ高精度な回答生成を確認し、多領域への適用可能性を示す
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この研究論文では、AIモデルの推論プロセスを「System-1」と「System-2」の思考に分類し、それらを統合した「テスト時計算(test-time computing)」という新たな視点を提案しています。System-1は迅速かつ自動的な処理を特徴とし、誤差が含まれやすい一方で、System-2はより深い推論と論理的思考を伴うが計算負荷が高いです。この統合アプローチにより、高精度で効率的なモデル推論を目指します。
この枠組みの中心にあるのは、System-1ではタスクの適応性を向上させる「テスト時適応法(test-time adaptation)」そして、System-2では強力な推論能力を実現する「理由づけ(reasoning)」です。具体的な手法として、System-1では、補助損失関数や不確実性推定に基づくモデルの微調整が行われ、System-2では、強化学習や自己修正型のトレーニングが行われます。また「フィードバックモデル」や「思考過程の探索」などを用いて、生成モデルの出力を評価および校正するメソッドも詳細に議論されています。
実験では、従来の方法と比較して、より柔軟かつ高精度な回答を生成する能力が確認され、多要素の音声や画像処理にも適用可能であることが示されました。このアプローチは、さまざまな課題の解決において、LLMの認知的能力をさらに高めるポテンシャルをもつものと期待されます。
図表の解説
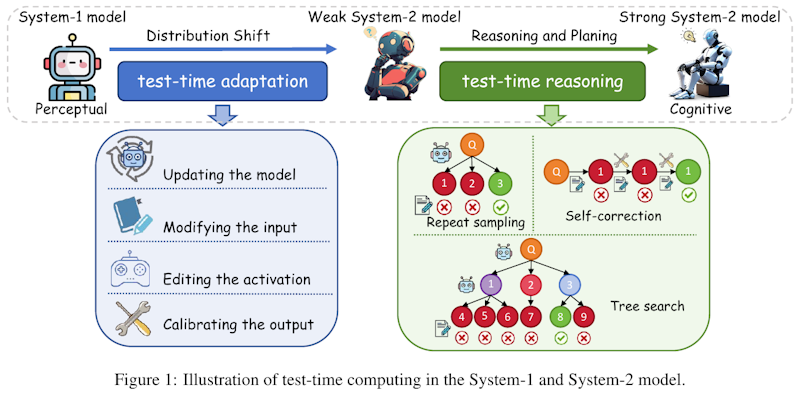
この図は、テスト時の計算方法が「システム1」と「システム2」の思考にどのように関係するかを示しています。 「システム1モデル」は、主に感覚に基づく直感的で自動的な思考を行います。図の左側は、外部からの変化に対応するための「テスト時の適応」を表しています。これは、モデルの更新、入力の変更、活性化の編集、出力の調整を含みます。 「システム2モデル」は、より深く考え、計画する能力を持つモデルです。図の右側では、「テスト時の推論」を通じて、この強力なシステム2思考への移行が示されています。ここでは、繰り返しサンプルを取る、自己修正、ツリー探索といった手法を用いて、モデルが複雑な問題を解決します。 これにより、モデルはより人間らしい認知能力を持つように進化していきます。
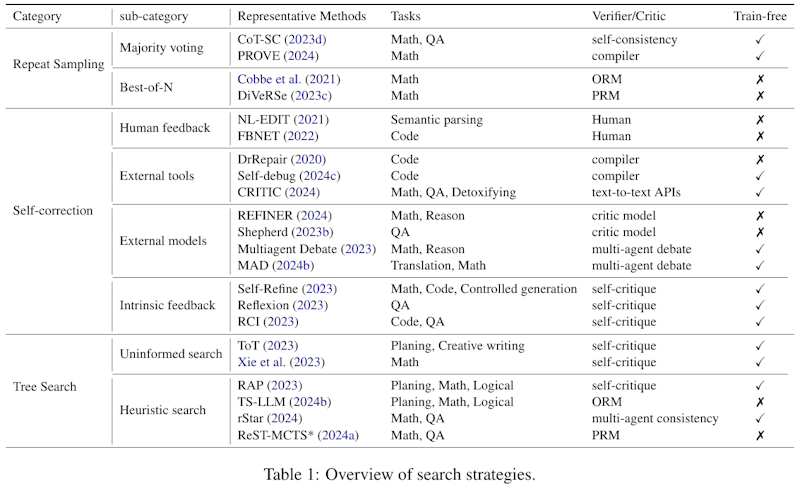
この画像は、論文で説明されている検索戦略の概要を示しています。検索戦略は、「リピートサンプリング」「セルフコレクション」「ツリーサーチ」の3つのカテゴリーに分けられ、おのおのが異なるタスクと手法に関連付けられています。「リピートサンプリング」は多数決投票やベストオブNという方法を用いて、複数のサンプルを生成し、その中から最も適したものを選ぶ戦略です。「セルフコレクション」は外部ツールやモデルからのフィードバックを活用し、生成結果を修正する方法です。「ツリーサーチ」は木構造を使って問題解決の道筋を探索する方法で、より深い理由付けを可能にします。これらの戦略は、モデルの推論精度を高めるための異なるアプローチを示しています。
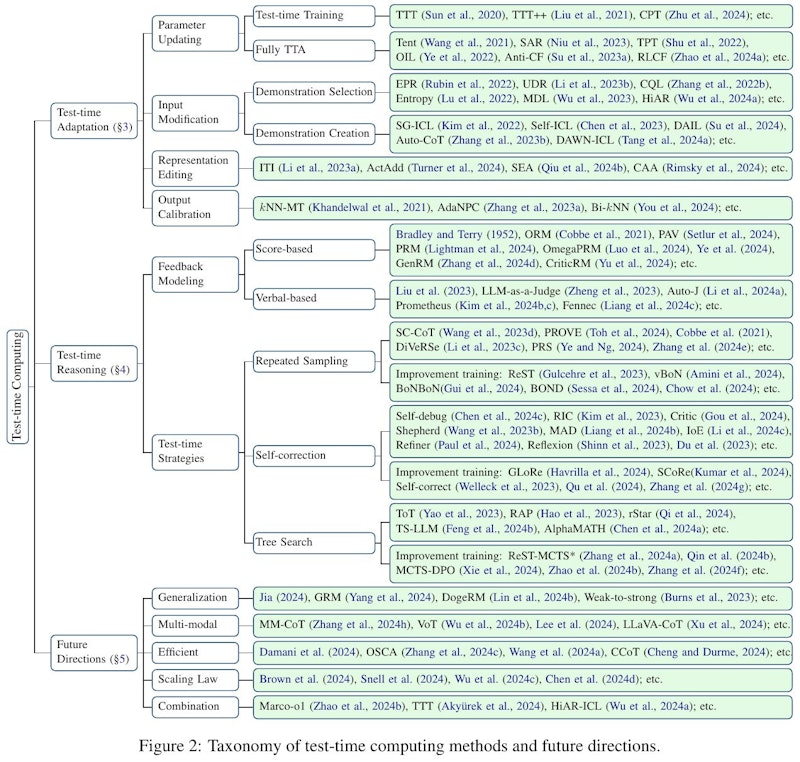
この画像は、論文におけるテスト時コンピューティング(Test-time Computing)手法の分類と今後の方向性を示しています。テスト時コンピューティングは、モデルが推論中に適応や修正を行う能力を指します。図では、テスト時適応とテスト時推論に分けられ、それぞれの手法が細かく分類されています。テスト時適応は、パラメータ更新や入力の修正などによってモデルを適応させる方法を含みます。テスト時推論は、モデルの推論能力を強化するためのフィードバックモデリングや再サンプリング、自己修正などの戦略を含んでいます。さらに、将来の方向性として、一般化やマルチモーダルの利用、効率化などが挙げられています。
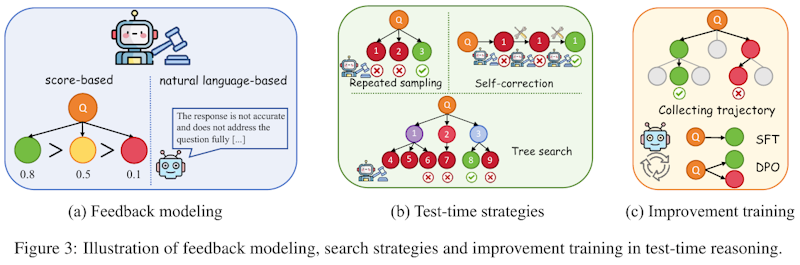
この図は、テスト時間推論におけるフィードバック、検索戦略、および改善トレーニングのプロセスを示しています。(a)のフィードバックモデリングでは、スコアベースと自然言語ベースの2種類のフィードバックがあり、質問への回答の正確性を評価します。(b)のテスト時間戦略は、繰り返しサンプリング、自己修正、そして木探索の3つの方法を示しており、回答の深さと精度を向上させるために使用されます。(c)の改善トレーニングでは、収集した軌跡を使用してモデルを訓練することで、システムの性能をさらに向上させる方法を示しています。これらの方法は、モデルの応答能力を強化し、より複雑な問題を解決するためのものです。
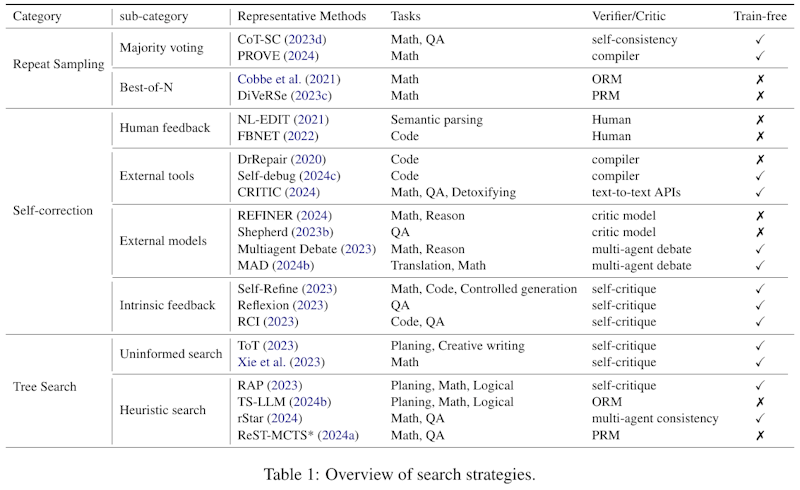
この画像は、論文の中で「検索戦略の概要」を示す表で、テスト時コンピューティングの異なる方法を整理しています。表は、繰り返しサンプリング、自己修正、木探索の3つの主要なカテゴリに分け、各々のサブカテゴリと代表的な方法を列挙しています。 例えば、繰り返しサンプリングには「多数決」や「Best-of-N」などが含まれ、数学や質問応答(QA)などのタスクで使用されます。自己修正のカテゴリには、人間のフィードバックや外部ツールの利用法があり、コードエラーの修正や毒性緩和を目的とした手法が紹介されています。 また、木探索のカテゴリではヒューリスティック検索が含まれ、計画や数理的な推論に応用されています。各手法について、検証や批評の方法、訓練の要否も説明されており、総合的な情報を提供しています。
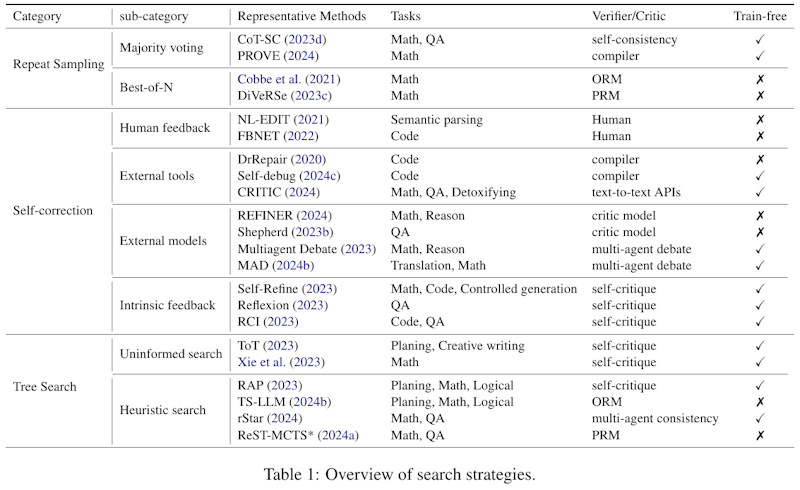
この表は、テスト時コンピューティングにおける様々な検索戦略を三つのカテゴリに分類したものです。これには、繰り返しサンプリング、自己修正、及び木探索が含まれています。 繰り返しサンプリングは、複数回のサンプリングを通じて最良の結果を求める手法です。自己修正は、モデルが自分の出力を評価し、改善するためのフィードバックを得る方法です。木探索は、解を見つけるために様々なルートを探索するプロセスを指します。 表には、代表的な方法と対象タスクの例が挙げられ、各方法の検証者や批評者が示されています。また、特定の方法が訓練を必要としない場合はチェックマークが表示されています。
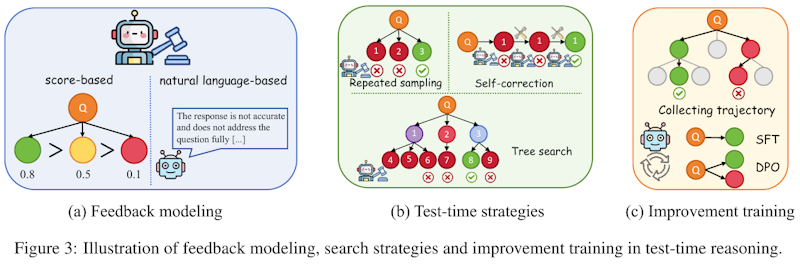
この図は、論文でのテスト時推論におけるフィードバックモデリング、探索戦略、改善トレーニングを示しています。 (a) フィードバックモデリングでは、モデルの回答に対するフィードバックを点数で評価する方法と自然言語で評価する方法が表されています。点数ベースでは回答の正しさを数値で評価し、自然言語ベースでは具体的な指摘や改善方法を自然言語で提供します。 (b) テスト時戦略では、反復サンプリング、自己修正、木探索の3つの方法が説明されています。これらは複雑な問題を解決するためのテスト時戦略として、モデルの推論能力を向上させます。 (c) 改善トレーニングは、モデルのトレーニング時に推論のトラジェクトリを収集し、これを活用してモデルを改善するプロセスを示しています。これらの方法全体が、モデルの性能向上を支える重要な工程として描かれています。
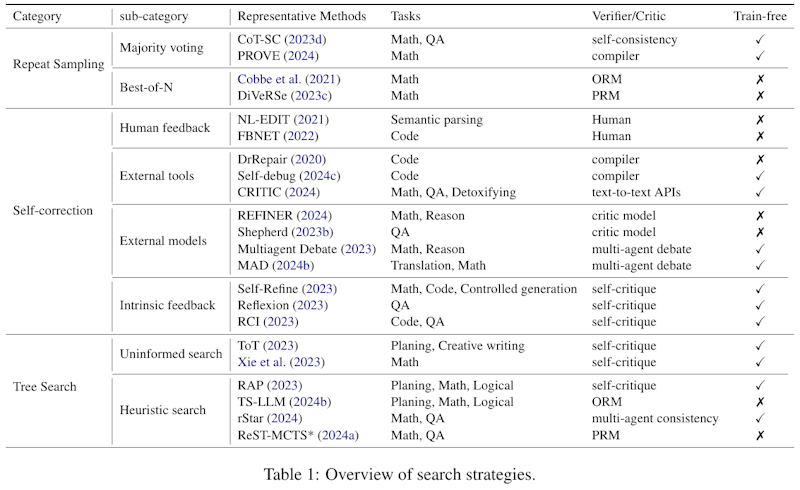
この表は論文内で使われている検索戦略の概要を示しています。表は「繰り返しサンプリング」「自己修正」「木探索」という三つの大カテゴリーに分類されています。それぞれのカテゴリには、代表的な手法やそれが適用されるタスク、検証者や批評者の情報が含まれています。 「繰り返しサンプリング」では、多数決やBest-of-Nといった手法が数学やQAに使われ、自己チェックやコンパイラーを利用して結果の整合性を確認します。 「自己修正」カテゴリでは、人間のフィードバックや外部ツール、外部モデルなどが数学やコードといった領域で使用されます。自己批評を活用してフィードバックを得て修正を行います。 最後に「木探索」では、無情報探索やヒューリスティック探索が行われ、創作文や数学的推論に使われます。







