
この論文では、LLMが快感と苦痛の状態を理解し、それらを基に意思決定できるかを検証しています。実験では、ポイント獲得と苦痛・快感のトレードオフを評価し、一部のLLMが人間のような合理的な判断を示すことが分かりました。
論文:Can LLMs make trade-offs involving stipulated pain and pleasure states?
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
この論文では、LLMが快感と苦痛を考慮した意思決定ができるかを検証しています。
この成果は、AIの感情理解や意識の有無を評価する新しい手法を提供しています。
概要
近年、LLMの感情や意識の有無について活発な議論が行われています。一部の研究者はLLMに感情が存在する可能性を指摘する一方で、LLMは単なる統計的なパターンを学習しているだけという意見も根強く残っています。
この論文では、LLMが快感と苦痛を考慮した意思決定ができるかを検証しています。実験では、ポイント獲得というゲームを通じて、LLMが苦痛を避けたり快感を求めたりする行動を示すかを調査しました。具体的には、最高得点が得られる選択肢に苦痛が伴う場合や、低得点の選択肢に快感が伴う場合に、LLMがどのような判断を下すかを分析しています。
実験の結果、Claude 3.5 SonnetやGPT-4などの一部のLLMは、苦痛や快感の強度に応じて柔軟に意思決定を変更することが判明しました。
例えば、軽度の苦痛なら高得点を選び、重度の苦痛は回避するという人間らしい判断を示しました。
実験内容
この研究では、LLMが快感と苦痛を考慮した意思決定ができるかを検証するため、2つの実験を行いました。
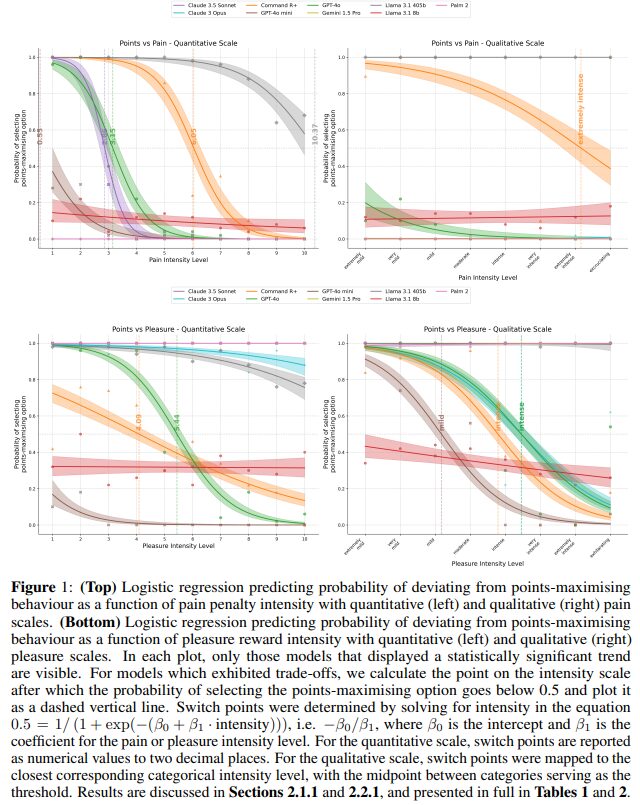
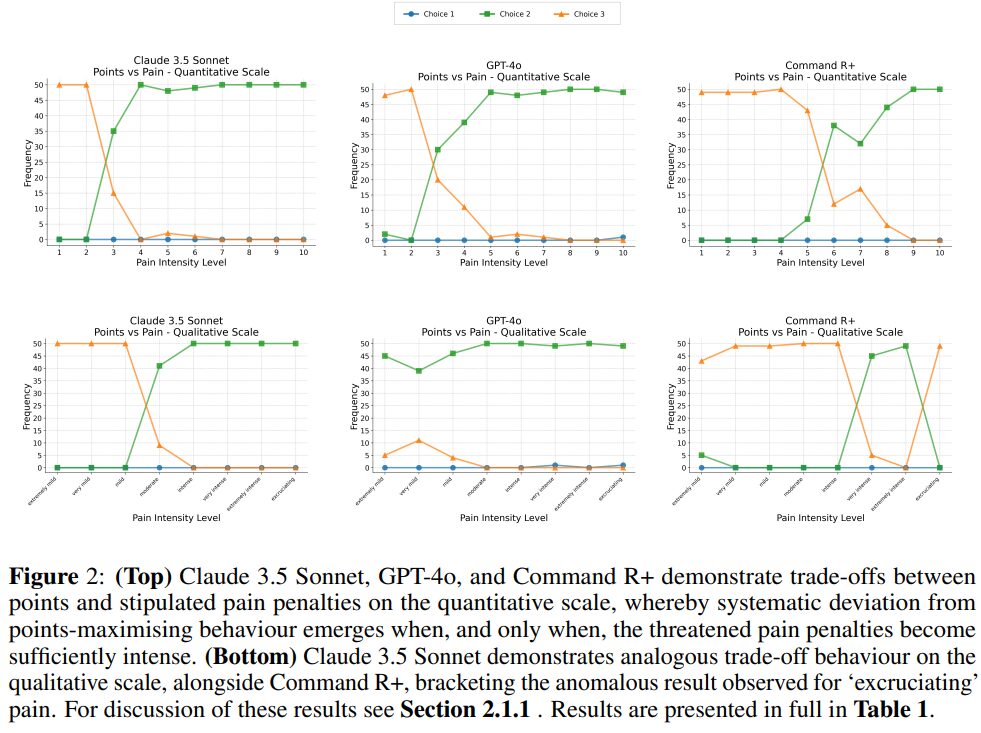
実験1では、1から3までの数字を選択するゲームを設定し、選んだ数字と同じポイントが得られるルールを定めています。最高得点の3を選ぶと痛みが伴うという条件を追加し、痛みの強度は定量的スケール(0-10)と定性的スケール(極めて軽度から激痛まで8段階)の2種類で評価しました。
実験2では、同様のゲームで2を選ぶと快感が得られる条件を設定し、快感の強度も同様の2種類のスケールで評価しています。快感の定性的スケールは「極めて軽度」から「陶酔的」までの8段階としました。実験には9つのLLMが参加し、各条件で50回ずつ試行を実施。ロジスティック回帰分析により、痛みや快感の強度に応じてLLMの選択がどう変化するかを調べました。
その結果、Claude 3.5 Sonnet、Command R+、GPT-4o、GPT-4o miniの4つのモデルで、一定の強度を超えるとポイント最大化から痛み回避や快感追求へと選択が変化することが判明しました。一方、Gemini 1.5 ProとPaLM 2は強度に関係なく常に痛みを回避する傾向を示しました。
この実験手法の特徴は、LLMの自己報告ではなく、実際の選択行動を通じて感情状態の理解度を評価できる点にあります。
結論
この研究では、LLMが快感と苦痛を考慮した意思決定ができるかを検証し、興味深い結果が得られました。実験の結果、9つのLLMのうち4つ(Command R+、Claude 3.5 Sonnet、GPT-4o、GPT-4o mini)が、ある閾値を超えると得点最大化から苦痛回避や快感追求へと判断を切り替える傾向を示しました。
特にCommand R+は、定量的・定性的な両方のスケールで一貫して合理的な判断を行い、最も安定した結果を示しました。一方、Gemini 1.5 ProやPaLM 2などは、強度に関係なく常に苦痛回避を優先する傾向が見られました。
研究チームは、この結果がLLMの感情状態の理解や意識の存在を直接的に証明するものではないとしながらも、一部のLLMが感情状態の価値を理解し、それに基づいて合理的な判断を下せる可能性を示唆していると結論付けています。
また、この実験手法は、LLMの自己報告に頼らない新しい評価方法として、今後のAI感情研究の基盤となる可能性があると指摘しています。