
MetaのMovie Genは、テキストから高品質な1080p HDビデオを生成できる画期的なAIモデルです。30Bパラメータの大規模モデルを採用し、最長16秒のビデオ生成が可能です。特筆すべきは、映像生成だけでなく、音声生成や動画編集、人物の特徴を反映した映像生成など、多彩な機能を1つのモデルで実現した点です。これにより、プロフェッショナルな映像制作の自動化が大きく前進しました。
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
Metaが発表したMovieGenは、テキストから高品質な動画生成を実現する画期的なAIモデルです。課題は、既存の動画生成AIが持つ「画質の低さ」「短い動画時間」「編集機能の欠如」でした。
これに対し、30Bパラメータの大規模モデルと独自の時空間圧縮技術を組み合わせることで解決を図りました。ポイントは以下の3つです:
これにより、プロフェッショナルな映像制作の自動化が大きく前進し、商用システムを含む既存の動画生成AIの性能を上回ることに成功しました
概要
Metaが発表したMovieGenは、テキストから高品質な動画を生成するAIモデルの研究です。現代のAI技術では、静止画の生成は高い完成度に達していますが、動画生成においては画質の低さや短い動画時間、編集機能の欠如などの課題がありました。
この研究では、30Bパラメータという大規模なTransformerモデルと時空間圧縮技術を組み合わせることで、フルHD(1080p)・16秒という高品質で長い動画生成を実現しました。さらに、音声生成から動画編集まで多彩な機能を1つのモデルに統合し、人物の特徴を反映した映像生成も可能にしています。
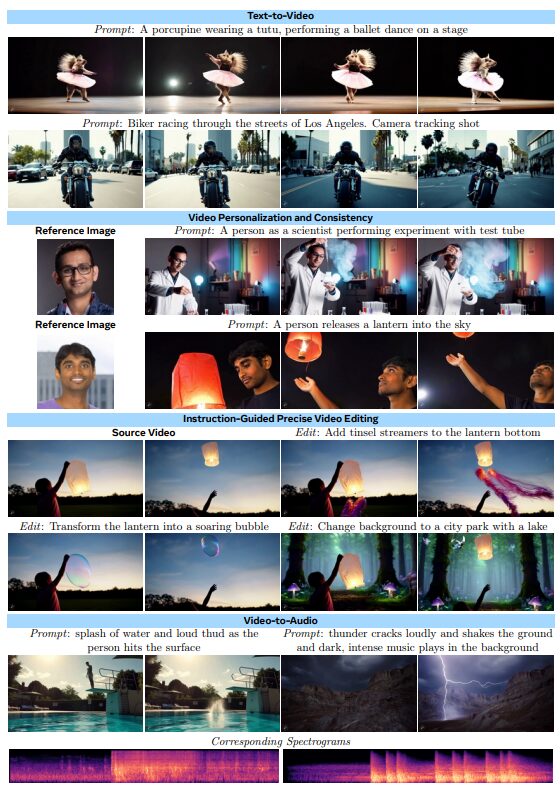
技術的な特徴として、Flow Matchingという学習手法を採用し、時空間オートエンコーダーを用いて効率的な学習を実現しました。また、複数のテキストエンコーダーを組み合わせることで、より豊かなテキスト理解を実現しています。
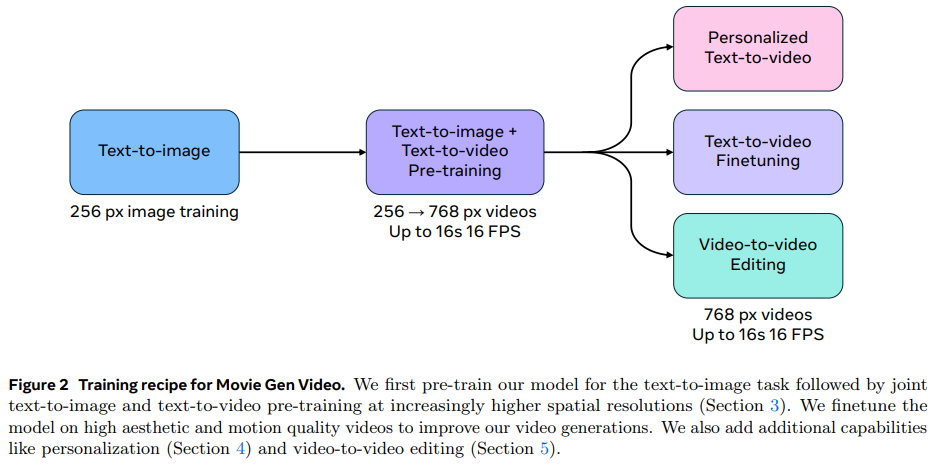
この研究の成果により、Runway Gen3やLumaLabsなどの商用システムを含む既存の動画生成AIの性能を上回り、プロフェッショナルな映像制作の自動化に向けて大きな一歩を記録しました。特に、パーソナライズされた動画生成や精密な動画編集など、従来のシステムにない機能を実装した点が画期的です。
提案手法
MovieGenの提案手法は、テキストから高品質な動画生成を実現する30BパラメータのTransformerモデルを中心に構成されています。
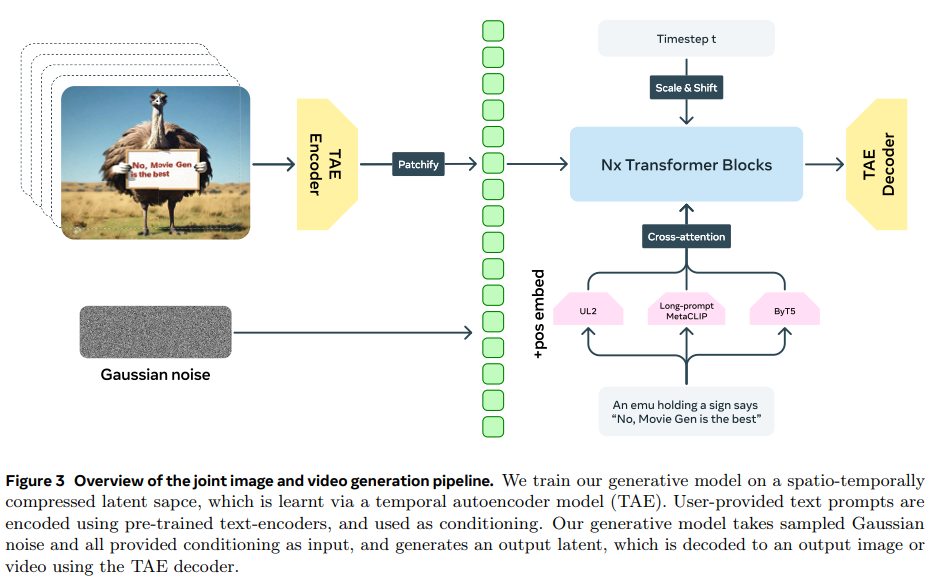
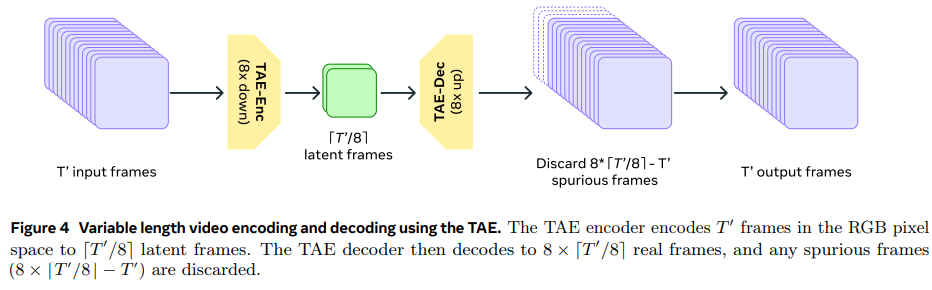
主要な技術的特徴として、時空間圧縮を行う時間的オートエンコーダー(TAE)を採用しています。TAEは入力動画を8倍圧縮し、効率的な学習を可能にしました。また、Flow Matchingという学習手法を用いることで、安定した動画生成を実現しています。
テキスト理解の面では、UL2、ByT5、Long-prompt MetaCLIPという3つの異なるテキストエンコーダーを組み合わせています。これにより、文字レベルと意味レベルの両方でテキストを理解できるようになりました。モデルの学習は段階的に行われ、まず256pxの低解像度画像で事前学習を行い、その後低解像度の画像と動画での同時学習、最後に高解像度での学習という順序で進められます。
さらに、高品質な動画でファインチューニングを行うことで生成品質を向上させています。音声生成については、13Bパラメータの専用モデルを用意し、48kHzの高品質な音声を生成可能です。また、パーソナライズ機能や動画編集機能は、事後学習によって実現されています。
実験
MovieGenの実験評価では、テキストから動画生成、動画の個人化、動画編集、音声生成など複数のタスクで最先端の性能を達成しています。主要な実験として、Runway Gen3やLumaLabs、OpenAI Soraなどの商用システムとの比較を行いました。
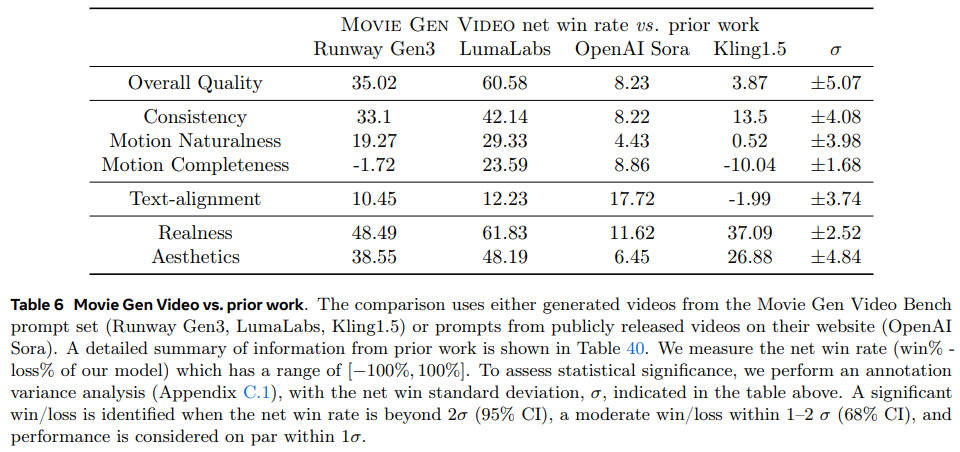
全体的な動画品質において、MovieGenは既存システムを上回る結果を示しています。動画の個人化機能では、ユーザーの顔写真から本人が登場する動画を生成できる能力を評価しました。実験の結果、人物の特徴を保ちながら自然な動作を生成できることが確認されました。動画編集タスクでは、TGVE+ベンチマークにおいて、EVEと比較して74%のケースで優れた評価を獲得しました。
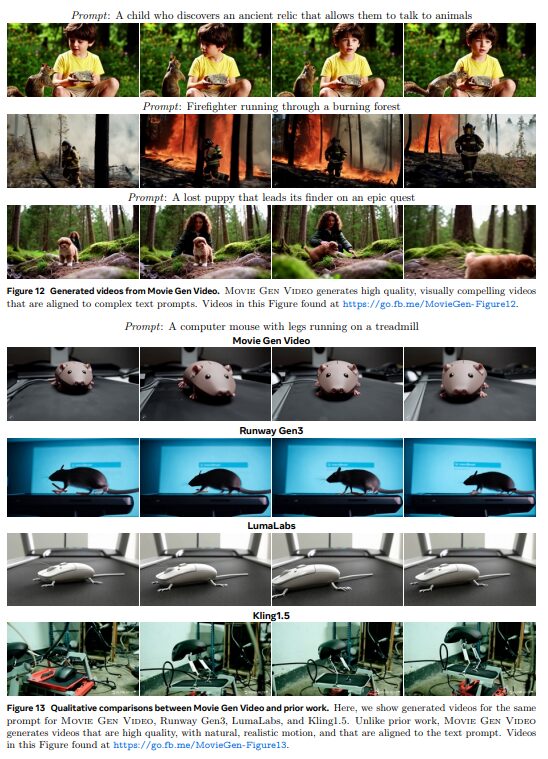
特に、動画の構造や細部の保持において高いパフォーマンスを示しています。音声生成に関しては、48kHzの高品質な音声を生成可能で、PikaLabsやElevenLabsなどの既存システムを上回る性能を達成しました。
実験では、30Bパラメータのモデルを用いて、1億本以上の動画とテキストのペア、10億以上の画像とテキストのペアでトレーニングを実施しました。この大規模なデータセットにより、様々なメディア生成タスクに対して高い汎用性を実現しています。
結論
MovieGenの研究は、テキストから高品質な動画生成を実現する画期的な成果を上げました。30Bパラメータの基盤モデルを用いて、1080p HDの高解像度動画を最長16秒間生成できることを実証しています。
研究の主な成果として、時空間圧縮技術とFlow Matchingを組み合わせた効率的な学習方法を確立し、複数のテキストエンコーダーを活用することで豊かなテキスト理解を実現しました。また、パーソナライズ機能や動画編集機能も実装し、既存の商用システムを上回る性能を達成しています。特筆すべき点は、動画生成だけでなく、48kHzの高品質な音声生成も可能な点です。音声生成モデルは13Bパラメータを持ち、映画のような臨場感のある音響効果や音楽を生成できます。
この研究は、1億本以上の動画とテキストのペア、10億以上の画像とテキストのペアでトレーニングを行い、様々なメディア生成タスクで最高水準の性能を実現しました。今後のメディア生成モデル研究の加速に貢献する重要な成果となっています。