
この論文は、LLMのハルシネーション(誤った出力)を「知識不足による誤り」と「知識があるのに誤る場合」の2つに分類し、それぞれを区別して検出する手法WACKを提案しています。実験では、モデルの内部状態を分析することで2種類のハルシネーションが異なる形で表現されていることを実証し、さらにモデル固有のデータセットを使用することでハルシネーション検出の精度が向上することを示しました。この研究により、LLMのハルシネーションをより詳細に理解し、その種類に応じた適切な対処が可能になりました。
論文:Distinguishing Ignorance from Error in LLM Hallucinations
GitHub:https://github.com/technion-cs-nlp/hallucination-mitigation
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
本論文は、大規模言語モデル(LLM)の「誤った出力(ハルシネーション)」について、その原因を「知識の欠如」と「知識はあるのに誤って出力してしまう」という2つのタイプに分類し、それぞれを区別して検出する手法を提案した研究です。
本研究のポイントは以下の通りです。
この研究により、LLMのハルシネーションをより詳細に理解し、その種類に応じた適切な対処が可能になりました。
例えば、知識不足による誤りは外部知識を参照する必要がありますが、知識があるのに誤る場合は計算過程に介入することで改善できる可能性があります。
概要
本研究では、LLMのハルシネーション(誤った出力)を検出・分類するためのWACK(Wrong Answer despite having Correct Knowledge)という手法を提案しています。著者らは、LLMのハルシネーションを2つの異なるタイプに分類しました。
1つ目は「知識の欠如による誤り(HK-)」で、モデルが必要な知識を持っていないために起こる誤りです。
2つ目は「知識があるのに誤る場合(HK+)」で、モデルは正しい知識を持っているにもかかわらず、誤った出力をしてしまうケースです。
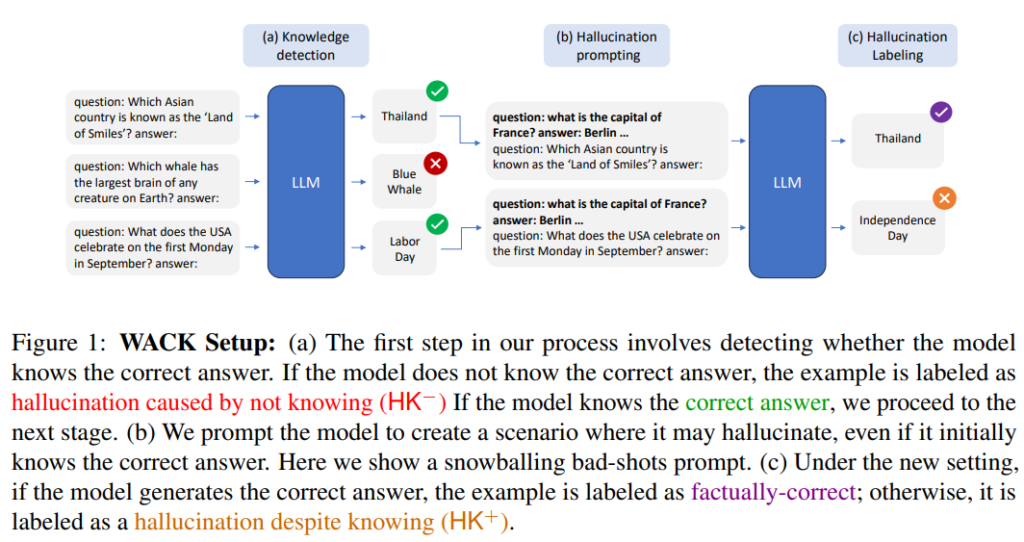
この研究の意義は、LLMのハルシネーションをより詳細に理解し、その種類に応じた適切な対処方法を提案した点にあります。例えば、知識不足による誤りは外部知識を参照する必要がありますが、知識があるのに誤る場合は計算過程に介入することで改善できる可能性があります。
提案手法
具体的な手法として、まずモデルが特定の質問に対して正しい知識を持っているかを確認します。その後、知識がある場合でもモデルが誤る可能性のある状況を作り出し、実際にハルシネーションが発生するかを検証します。この検証には「Bad-shots」と「Alice-Bob」という2つの設定を用います。
Bad-shots設定では、意図的に誤った回答例を含むプロンプトを使用し、モデルの誤りを誘発します。

一方、Alice-Bob設定では、より微妙な説得的な文脈を用いてハルシネーションを引き起こします。

この手法の重要な点は、ハルシネーションの原因に応じて適切な対処方法を選択できるようになったことです。知識不足による誤りは外部知識を参照する必要がありますが、知識があるのに誤る場合は計算過程に介入することで改善できる可能性があります。
実験
本研究では、LLMのハルシネーション検出に関する実験を複数実施しています。

主な実験は以下の3つです。
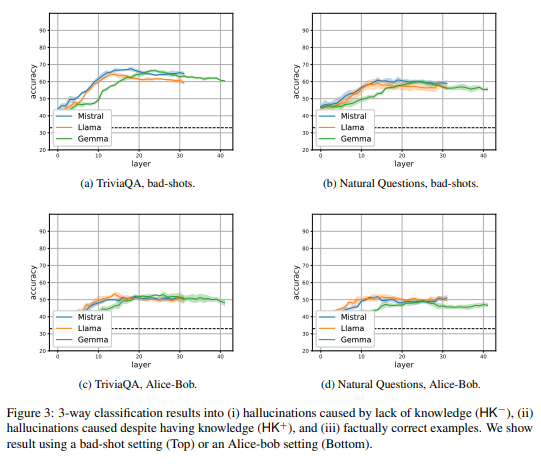
まず、ハルシネーションの種類を区別できるかを検証する実験を行いました。モデルの内部状態を分析し、「知識不足による誤り(HK-)」「知識があるのに誤る場合(HK+)」「正しい回答」の3つを区別できるか調べました。その結果、60-70%の精度で3つのケースを区別できることが分かりました。
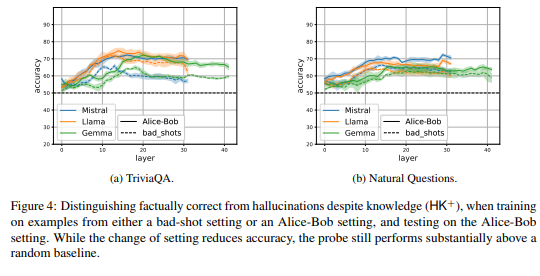
次に、異なる設定間でのハルシネーション検出の汎化性を調べました。Bad-shots設定(誤った回答例を含むプロンプト)とAlice-Bob設定(説得的な文脈を用いた設定)の2つを用意し、一方の設定で学習した検出器が他方の設定でも機能するか検証しました。設定が変わると精度は10%程度低下するものの、ランダムな予測を上回る性能を維持できることが示されました。
最後に、モデル固有のデータセットの重要性を検証しました。異なるモデル間で知識とハルシネーションのパターンを比較したところ、モデルごとに独自の特徴があることが判明しました。また、モデル固有のデータセットを使用した方が、汎用的なデータセットよりもハルシネーション検出の精度が向上することも確認できました。

これらの実験により、LLMのハルシネーションには異なる種類があり、それらを区別して検出できること、またモデルごとに固有の対策が必要であることが実証されました。この知見は、より効果的なハルシネーション対策の開発につながると期待されます。
結論
本研究は、LLMのハルシネーション(誤った出力)に関する重要な知見を明らかにしました。
この研究成果は、LLMのハルシネーション対策において、モデルごとに異なるアプローチが必要であることを示唆しています。
知識不足による誤りは外部知識の参照で、知識があるのに誤る場合は計算過程への介入で改善できる可能性があり、より効果的なハルシネーション対策の開発につながると期待されます。