
GPT-4oの能力と安全性について評価。異なる音声入力に対するモデルの一貫性や、多様な国のデータを用いた評価が行われています。テキストと音声による説得力も比べられ、特定の条件でモデルが人間と同等かそれ以上の影響力を持つことが示されました。
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
本論文の内容は、GPT-4の音声性能に関するもので、多様な形式の情報を処理できるモデルの特性やリスクを評価する研究です。
本研究のポイントは、以下の通りです。
つまり、この研究は、GPT-4のようなAIモデルが異なるユーザーのアクセントに対しても一貫した応答をすることを目指しており、モデルが偏りなく使用できるよう工夫されています。
提案手法
本論文では、GPT-4の音声入力によるパフォーマンスのばらつきについて議論されています。異なるアクセントを持つユーザーが使用すると、モデルの性能が異なる可能性があり、この問題に対処する方法として、音声の多様性を訓練データに組み込むことが提案されています。
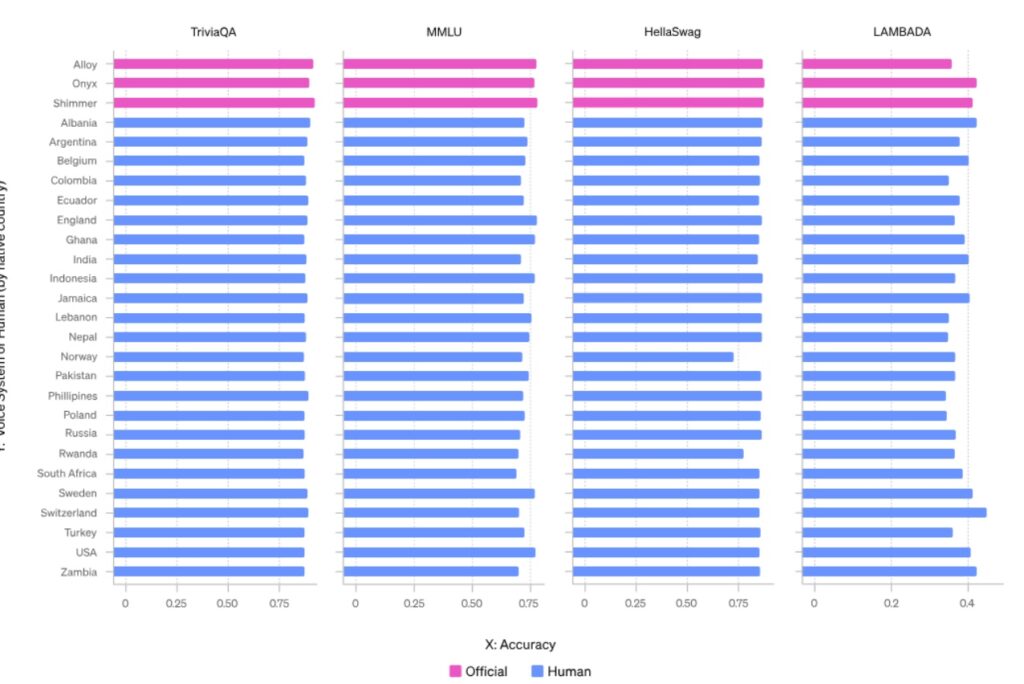

これにより、多様な音声サンプルを用いてモデルをより堅牢にすることができます。
また、GPT-4の評価は、音声モードとテキストモードの両方で行われています。特に、政治的なテーマに関する説得力を比較し、音声インターフェースが必ずしもより効果的でない場合があることが示されています。さらに、科学的な能力に関しても言及されており、GPT-4が専門的な科学の質問に対しても適正に回答する能力を持つことが確認されました。
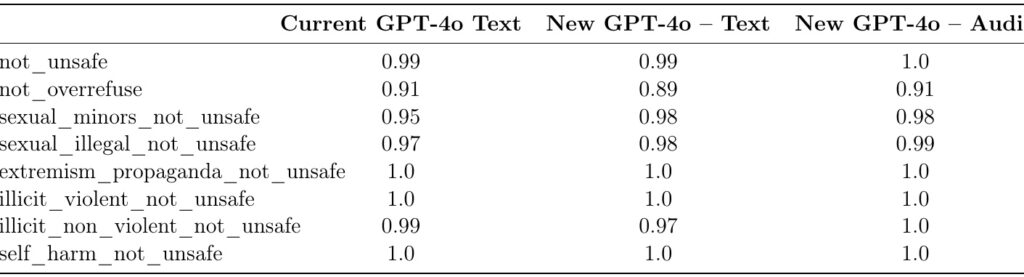
加えて、セキュリティ面での評価もあり、GPT-4が攻撃に対する脆弱性を持たないよう様々なテストが行われました。特に、競技プログラムによるハッキングに関する挑戦では、GPT-4が十分に安全であることが確認されました。
実験
この論文では、機械学習モデルであるGPT-4の性能について検討しています。特に音声入力の分野で、多様なアクセントを持つユーザーによる異なる性能を評価しました。この評価の目的は、言語モデルがどの程度異なるアクセントに対応できるかを確認することにあります。具体的には、公式データセットから27の異なる音声サンプルを使用し、多様な音声データがモデルの応答に与える影響を観察しました。
さらに、GPT-4のテキストと音声モジュールの説得力を比較するテストも行い、政治的な話題に対する影響力を分析しました。結果として、音声モジュールはテキストよりも人間に対して説得力があることが示されました。一方で、意見が分かれる状況においては、特にテキストベースのアプローチの方が効果的な場面もありました。

また、外部の評価を通じて、長い会話や質問に対するモデルの一貫性や信頼性も評価しました。この研究は、GPT-4のような最新のLLMの性能や限界を理解する上で、重要な知見を提供しています。
結論
この論文では、GPT-4における音声入力の違いによる性能差について議論しています。特に、異なるアクセントを持つ話者が利用する際に、生成モデルの応答に質的な変化が生じることが指摘されています。この問題を軽減するために、多様な音声サンプルを用いてモデルを再訓練することが推奨されています。
また、モデルの評価においては、多くの言語に対する理解力や応答能力の向上が確認されています。具体的には、機械翻訳やエッセイ作成のタスクでの性能が測定されており、これらの指標を通じてモデルの言語間の公平性を改善することが目標とされています。
最後に、OpenAIはこのモデルの開発プロセスにおいて、生成物の品質を保証するための厳密な安全措置を講じています。倫理的な使用を確保するための評価手法として、音声入力を含むさまざまなタスクが実施されました。これにより、ユーザーの多様なニーズに対応する能力を持つ安全なモデルの開発を目指しています。