
この論文は、ポーランド語専用の大規模言語モデル「Bielik 7B v0.1」の開発と評価について述べています。このモデルは13億のパラメータを持ち、ポーランド語の理解と生成に最適化されています。主なポイントは、高品質なポーランド語テキストの生成を可能にし、教育や自動翻訳、対話システムなど多様なアプリケーションでの利用が期待されています。
論文:Bielik 7B v0.1: A Polish Language Model – Development, Insights, and Evaluation
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
この論文は、ポーランド語に特化した言語モデル「Bielik 7B v0.1」の開発とその評価について述べています。
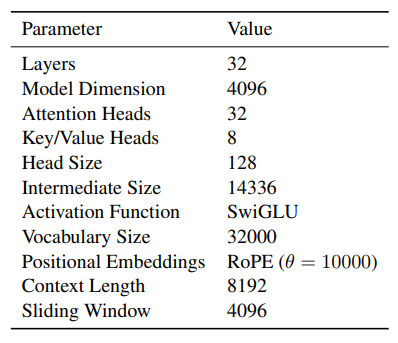
本研究のポイントは次の通りです。
つまり、この研究はポーランド語に対応した言語モデルの改善に貢献し、ポーランド語を用いた様々なアプリケーションを支える基盤を提供するものです。
提案手法
この論文では、ポーランド語の言語モデル「Bielik 7B v0.1」の開発と評価について説明しています。Bielikモデルは、17億トークンを使用して事前訓練され、Transformerアーキテクチャを基盤としています。このモデルは、マルチタスク学習を利用して、幅広いポーランド語の自然言語処理タスクに対応できるように設計されました。
具体的には、13種類の異なるタスクでモデルをテストし、それぞれのタスクで競争力のある性能を示しています。
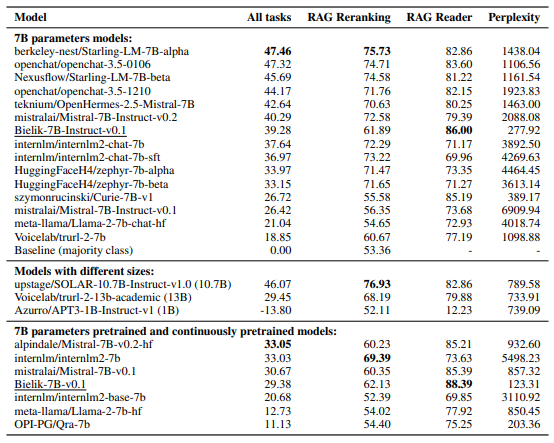
さらに、Adaptive Learning Rateや重み付きクロスエントロピーロスなどの技術を導入し、モデルの学習効率を向上させています。
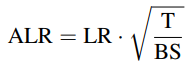
このモデルは、特にポーランド語でのタスクにおいて、人間のフィードバックによる評価で高い成績を収めました。
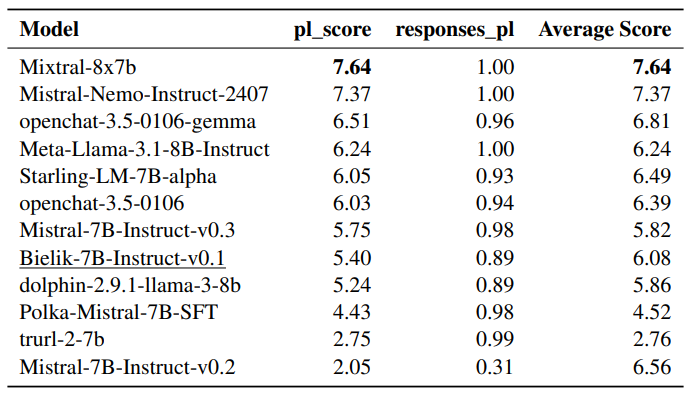
加えて、ポーランド語と英語のデータセットを組み合わせて評価を行い、異なる言語間でのモデルのパフォーマンスを比較しました。
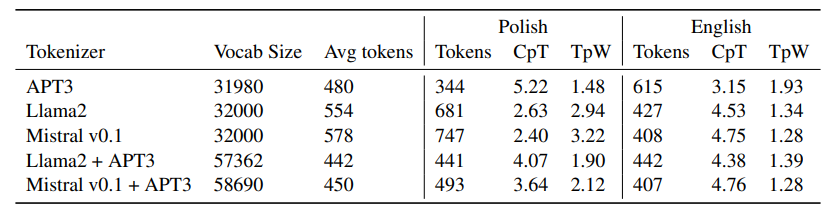
この研究は、ポーランド語におけるNLPの最前線を切り拓くものであり、他の言語への応用可能性も示唆しています。全体として、Bielikは、多様なタスクにおいて有望な結果を示し、ポーランド語圏での活用が期待されています。
結論
この論文は、ポーランド語のLLMである「Bielik 7B」の開発とその評価について述べています。Bielik 7Bは、7億パラメータを持ち、主にポーランド語のテキストから訓練されたモデルです。本研究では、モデルの性能だけでなく、偏見や誤情報の抑制にも注力しています。
Bielik 7Bの評価は、ポーランド語のMT-Benchを使用して行われ、他のよく知られたモデルと比較されました。その結果、このモデルは特にポーランド語のタスクにおいて優れた性能を示しました。また、音声認識や翻訳など、多岐にわたるタスクで有用性を確認しています。
さらに、量子化技術を利用することで、モデルの計算効率を高めつつ、品質をほぼ維持することに成功しています。このアプローチにより、計算資源が限られているシステムでも効率的に運用可能です。
今後も多言語対応や性能向上に向けた研究開発が続けられ、ポーランド語をはじめとする自然言語処理技術の進展が期待されています。このモデルは、特にポーランド語&英語混在環境での利用に貢献することが期待されています。