
この論文では、Moshiというリアルタイム音声対話モデルを提案しています。Moshiは、音声から直接音声を生成する技術を用いることで、自然な会話体験を提供します。従来のモデルでは難しかった重複発話や割り込みへの対応が可能になり、遅延の少ない全二重の対話が実現。
論文:Moshi: a speech-text foundation model for real-time dialogue
GitHub:https://github.com/kyutai-labs/moshi
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
本論文は、音声対話システムの新しい手法「Moshi」を提案しています。
本研究のポイントは以下の通りです。
つまり、Moshiは高度な音声対話体験を提供し、自然な人間同士の会話に近いシステムを実現しています。
背景
従来の音声対話システムは、音声認識やテキスト生成、音声合成といった複数の独立したモジュールを組み合わせたパイプライン方式で構築されています。しかし、この方式にはいくつかの課題がありました。
例えば、各モジュール間の遅延が積み重なり、自然な会話とは程遠い数秒のラグが発生すること、またテキストベースの対話に依存するため、感情や環境音といった非言語的な情報が失われてしまうことです。
さらに、話者のターンが明確に区切られている前提のため、重複した発話や割り込みを自然に処理することが困難でした。
Moshiはこれらの問題を解決するために、ユーザーの音声とMoshi自身の音声を同時に処理できるように設計されています。そうすることで、話者のターンを明確に分ける必要がなく、重複する発話や割り込みといった自然な会話の動態をそのまま扱うことができます。
提案手法
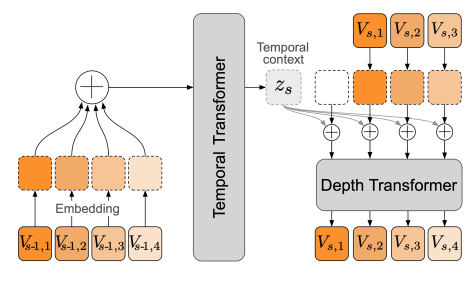
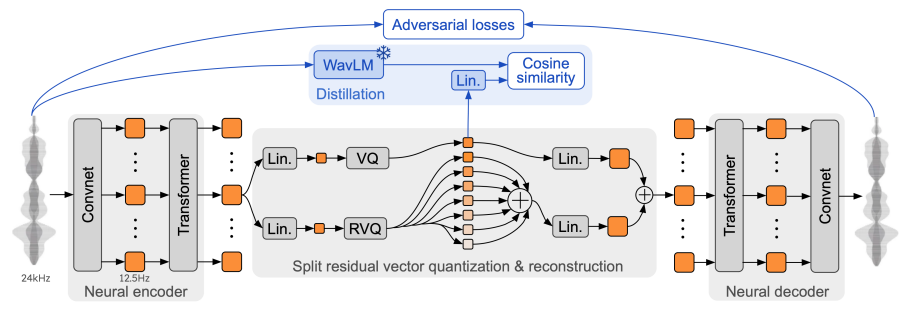
Moshiのシステムは、音声とテキストの両方を処理するためのTransformerベースのモデル「Helium」と、音声トークンを生成する「Mimi」という音声コーデックを組み合わせて動作します。
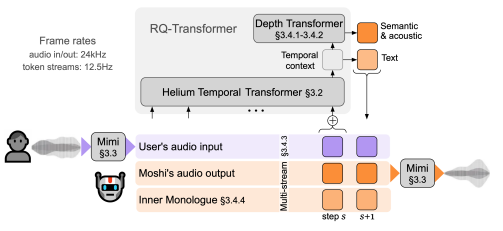
Mimiは、音声を「音声トークン」と「意味トークン」に分けて扱うことで、細かな音声情報を保持しつつ、リアルタイムでの生成を可能にしています。また、Moshiは「Inner Monologue」という手法を用いて、音声トークンを生成する前にテキストトークンを予測することで、音声の言語的な品質を高めています。
Moshiは、従来の音声対話システムと異なり、話者のターンを明確に区切る必要がなく、ユーザーとシステムが同時に話すことができる「全二重」の対話を実現しています。
対話中の重複発話や割り込みにも柔軟に対応でき、自然な会話の流れを維持します。さらに、Moshiは遅延を最小限に抑えるため、音声とテキストの予測を階層的に行い、ストリーミングでのリアルタイム生成をサポートしています。
Moshiのモデルアーキテクチャの詳細です。
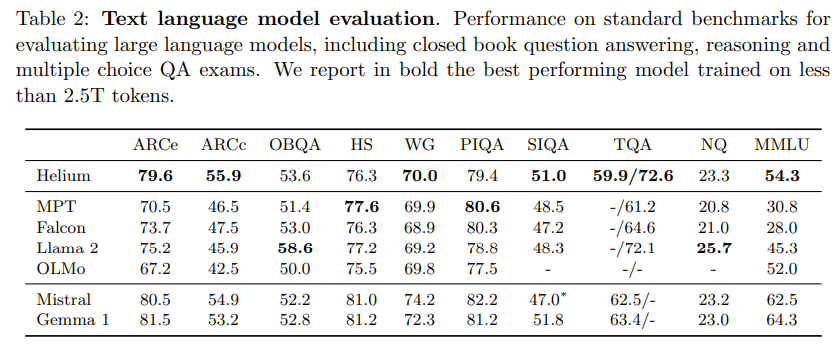
実験
Moshiの実験では、モデルの性能を検証するために、音声理解や生成、リアルタイム対話など多岐にわたる評価が行われました。
まず、Moshiの音声生成能力は、従来の音声対話システムと比較して、音声の一貫性と自然さがどれだけ向上しているかを検証しました。具体的には、Moshiは音声から直接音声を生成する手法を採用しているため、従来のテキスト経由のシステムでは捉えきれなかった感情やイントネーションの再現が優れています。この性能は、特にユーザーの発話が重なったり、割り込んだりする場面で顕著に現れました。
実験の一環として、Moshiは複数の音声タスクで評価されました。例えば、音声認識の精度や音声生成の品質について、既存の大規模モデルと比較されました。Moshiは、ユーザーの発話をリアルタイムで認識しつつ、同時に自然な応答を生成できることが確認されました。この評価では、特に音声の一貫性やユーザーが求める情報の正確さに焦点が当てられ、結果としてMoshiは他のモデルよりも高いパフォーマンスを示しました。
さらに、Moshiのリアルタイム性を評価するために、遅延時間が測定されました。一般的な会話の応答時間は数百ミリ秒とされますが、Moshiは理論的に160ミリ秒、実際には200ミリ秒程度の遅延で応答が可能であり、従来のシステムと比較しても非常に短い遅延で対話が可能であることが示されました。この低遅延は、Moshiがターン制を必要とせず、常に話しながら聞くことができる全二重の対話を実現しているためです。
結論
Moshiは、ユーザーと同時に話し、重複する発話や割り込みにも対応できる全二重の対話が可能で、遅延時間も従来のシステムより大幅に短縮されています。このため、リアルタイムで自然な会話を支援する音声アシスタントとしての可能性を広げています。