- 動画コンテンツに対応した応答生成手法「VideoRAG」を提案
- 動画とテキストの情報を統合し、質問に適した外部情報を活用するプロセスを採用
- 従来のRAGと比較して視覚情報の活用で応答の質が向上
論文:VideoRAG: Retrieval-Augmented Generation over Video Corpus
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
VideoRAGは、既存のRAG(Retrieval-Augmented Generation)フレームワークを動画コンテンツに拡張し、マルチモーダルな情報を活用した高度な応答生成を可能とする新しい手法を提案しています。この手法では、動画とテキストの特徴量を統一的に扱うため、テキストベースの情報に加え、動画から抽出される視覚的情報を活用する点が特徴です。
提案手法は以下の3段階で構成されています。まず、動画や関連するテキストデータから情報を取得するために、動画特徴量とテキスト特徴量を統合し、利用可能な情報を最大限引き出します。次に、それらの情報を基に、質問内容に最も適した外部情報を選定する「情報取得ステップ」を行います。そして最後に、LLMを用いて、取得した情報を参照しつつ応答を生成します。この過程において、視覚的およびテキスト的特徴が緊密に結合され、より多次元的な応答生成が行われます。
実験では、テキストのみを対象とする従来型RAG手法と比較し、VideoRAGが圧倒的に優れた性能を示すことが確認されました。具体的には、視覚情報を適切に利用することで、応答生成の質が大幅に向上し、特に手順や具体的な事例が必要とされる質問に対して効果が顕著でした。また、視覚的特徴の有効性を分析した結果、視覚情報単独よりも視覚的・テキスト的情報を組み合わせた方が精度が向上することが示されました。
図表の解説

この図は、Retrieval-Augmented Generation(RAG)の3つのシナリオを比較しています。(A)では、テキストRAGがテキストコーパスから関連文書を取得し、それを回答生成に組み込みます。(B)では、従来のマルチモーダルRAGが静的画像を追加します。(C)では、VideoRAGが動画を外部知識源として使います。質問「幅広の部分を狭い部分の上に交差させた後、ネクタイをどう結ぶか?」に対し、(A)は歴史的な文脈を、(B)は静的な情報を提供しました。(C)は動画を基に、具体的な動作手順を示しています。これは、VideoRAGが動的で具体的な情報提供を可能にすることを示しています。
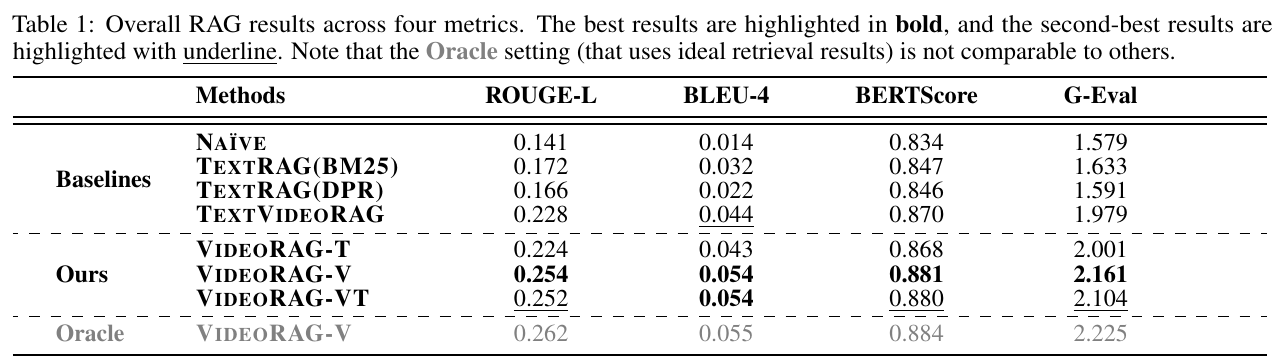
この表は、論文「VideoRAG: Retrieval-Augmented Generation over Video Corpus」から抜粋されており、新しいシステムVideoRAGの性能を示しています。表には、ROUGE-L、BLEU-4、BERTScore、G-Evalの四つの指標が含まれており、それに基づいてさまざまなモデルの結果が比較されています。 まず、基準ラインとなる「Naïve」や「TextRAG(BM25)」のような既存のテキストベースのRAGモデルと比較すると、VideoRAGは「Ours」としての結果が特に優れています。特に、VideoRAG-VTとVideoRAG-Vが高い性能を示しており、これはビデオを用いた情報の質がテキストベースのものを上回っていることを示唆します。また、「Oracle」のビデオRAGは、理想的な検索結果を使用したものであり、他の結果と直接比べることはできませんが、潜在的な性能向上の可能性を示しています。 全体として、この研究は、ビデオを用いた生成がテキストベースのアプローチよりも内容の豊かな出力を可能にすることを示しており、生成補強型AI(RAG)の新しい可能性を開くものとなっています。
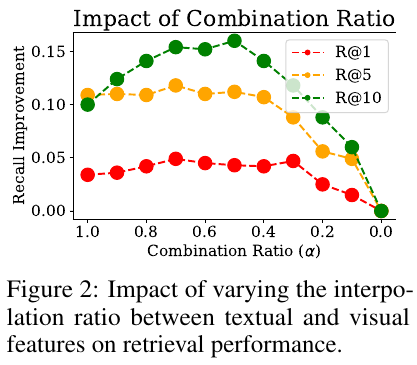
この図は、テキストとビジュアルの機能を組み合わせた際のリコール改善に対する影響を示しています。図2に示されるように、異なる組み合わせ比率(α)に基づいて、R@1、R@5、R@10の各リコールメトリックがどう変化するかをグラフで表現しています。 横軸は組み合わせ比率(α)を示しており、この値はテキストとビジュアル情報の比率を示します。R@1、R@5、R@10の各メトリックがそれぞれの色で表されており、αを1から0に変化させた場合のリコール改善を示しています。 図から分かるように、αが0.5から0.7の間のときに最も高いリコール改善が得られ、特にR@10で顕著です。このことは、テキストとビジュアルを組み合わせて使用することが効果的であることを示唆しています。同時に、ビジュアル情報はテキスト情報が持つセマンティクスと補完関係にあり、適切な比率で組み合わせることが重要です。

この表は、異なる動画セットを用いた生成結果を示しています。各動画セットは「ランダム」、クエリに基づいて動画を選ぶ「リトリーブド」、そしてデータで注釈された「オラクル」動画を使用しています。「ランダム」は無作為に動画をサンプリングし、「リトリーブド」はクエリとの関連性に基づいて動画を選択、「オラクル」はデータで注釈された真の動画を使用します。 表の指標には、生成されたテキストと参照テキスト間の類似性を測る「ROUGE-L」、生成テキストの正確性を評価する「BLEU-4」、そして文の意味的な一致度を示す「BERTScore」があります。 リトリーブドは「ランダム」よりも高いスコアを示し、これは関連性のある動画の選択が生成結果を改善することを示しています。また、オラクルのスコアが最も高く、理想的な動画が性能向上に寄与する可能性を示しています。
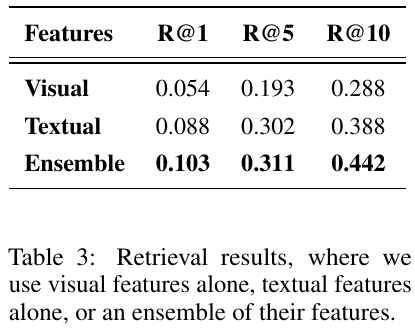
この表は、VideoRAGというフレームワークに関する研究における情報検索(リトリーバル)の結果を示しています。具体的には、視覚的特徴、テキスト的特徴、そしてその両方を組み合わせたEsemble(エンボディ)の3つの方法で動画情報を検索し、各方法での精度を示しています。R@1、R@5、R@10という指標は、それぞれ検索結果の上位1件、5件、10件における正確性(関連度が高いものをどれだけ正確に検索できたか)を示しています。テキスト的特徴が視覚的特徴よりも高い精度を示していますが、両者を組み合わせることで最も高い精度が得られていることがわかります。これは、視覚とテキストの両方の情報が補完的に作用して、より効果的な検索を可能にしていることを示しています。
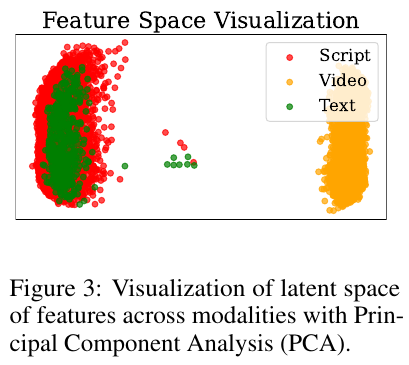
この図は、異なるモダリティー(スクリプト、ビデオ、テキスト)の特徴が主成分分析(PCA)を用いて視覚化されています。図中の色で示される赤、黄、緑の点はそれぞれスクリプト、ビデオ、テキストの特徴を表しています。この図は、「VideoRAG」という新しいフレームワークに関連しています。このフレームワークは、クエリに基づいて関連するビデオを動的に取得し、そのビジュアル情報とテキスト情報の両方を出力生成に活用します。この視覚化は、異なるモダリティーの特徴がどのように分布しているかを理解するのに役立ちます。
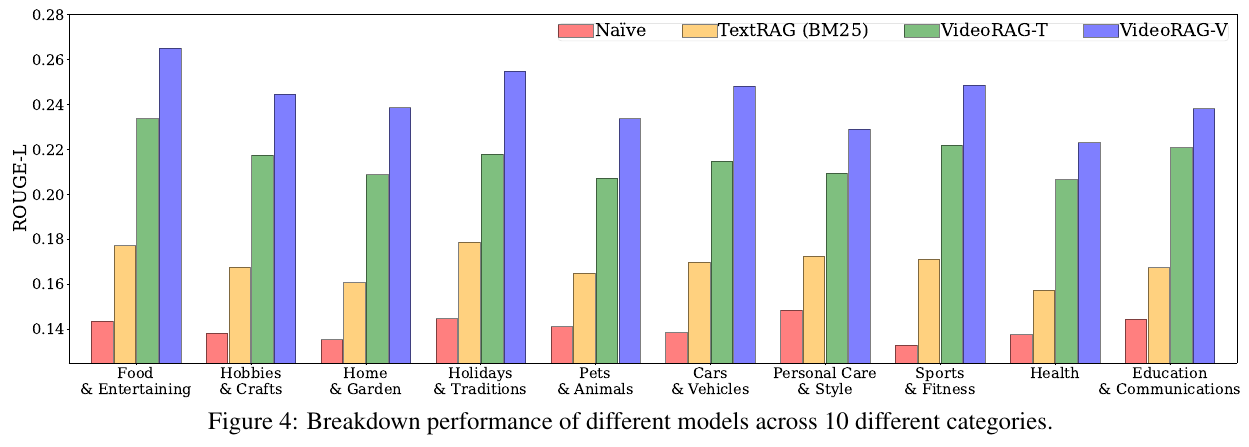
この図は、VideoRAGモデルと他のモデルのROUGE-Lスコアを10のカテゴリにわたって比較しています。このスコアは、生成された回答がどれくらい元の情報に忠実であるかを示します。図によると、VideoRAGモデル(特に、VideoRAG-TとVideoRAG-V)は、ほとんどのカテゴリで他のベースラインモデルを上回っています。これは、ビデオを活用することが回答生成に役立つことを示しています。特にビジュアル情報が重要な「食とエンターテイメント」などのカテゴリで、VideoRAGは優れたパフォーマンスを発揮しています。これは、ビデオが提供する視覚的な詳細が、テキストのみでは補えない部分を効果的にサポートできることを示しています。

表5は、異なるモダリティを用いたアブレーション研究を示しています。ここでは、テキストや動画、字幕の利用が異なる方法で検討されています。NaïveはWikipediaを利用せず、単に生成を行っていますが、ROUGE-Lスコアが0.141、G-Evalが1.579と低いです。TextRAGはWikipediaを活用し、0.172と1.633のスコアを得ています。VideoRAG-VTは動画と字幕を使い、ROUGE-Lで0.252、G-Evalで2.161と最良の成果を示しました。最後に、VideoRAG-VT + TextRAGはすべてのモダリティを使い、ROUGE-Lで0.243、G-Evalで2.048という結果です。これらの結果は、異なるモダリティが生成品質に与える影響を評価しています。