- 数学的推論に強いマルチモーダルモデルURSAを導入
- 新しいデータ拡張と誤答例の活用による推論能力の向上
- URSAが他モデルを超える精度を持つことを実証
論文:URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この論文では、数学的推論が必要なマルチモーダルな問題解決において、モデルが適切かつ信頼性の高い「思考の連鎖(Chain-of-Thought, CoT)」を生成できるかを理解し、検証するための手法を提案しています。具体的には、URSA-8Bと呼ばれる新しいモデルを開発し、その強化版であるURSA-RM-8Bを導入しました。
まず、従来の大規模マルチモーダルLLMが数学的推論で課題を抱えている背景を踏まえ、URSAは次のような独自のアプローチを採用しています。まず、CoT形式でデータを拡張し、段階的な推論の質を向上させる仕組みを導入した点です。また、誤解釈による誤答例を利用してモデルの出力を精査し、推論能力を向上させるプロセスを追加しています。これにより、画像データとテキストの両方を確実に理解して処理する性能が強化されています。
実験では、URSA-8BおよびURSA-RM-8Bを使用し、数学関連のさまざまなベンチマーク(MathVIS、MathVerveなど)で評価を実施しました。その結果、これらのモデルはマルチモーダルなタスクにおいて、既存のオープンソースモデル(例えばLLaVA、GTP-4など)やクローズドソースモデルを上回る高い精度を示しました。特に、URSA-RM-8Bは数式処理や幾何学的問題といった厳密さが求められる分野で優れた性能を発揮しています。
さらに、データ合成や応答検証のフレームワークを用いることで、モデル出力に一貫性と信頼性を付与することに成功しています。
図表の解説
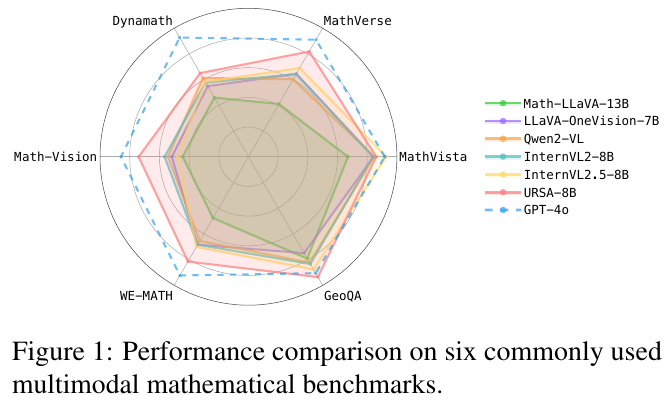
この図は、複数のマルチモーダル数学ベンチマークでのモデルの性能を比較したものです。図の中で、多角形の各頂点はそれぞれ異なるベンチマークを表しています。線でつながれたデータは、さまざまなモデルの性能を示しています。緑色の線で表されているのが「Math-LLaVA-13B」というモデルで、その他複数のモデルも比較されています。この図では、「URSA-8B」と「GPT-4o」が破線で示されています。「URSA-8B」は、多くのベンチマークで他のモデルより優れた性能を示し、「GPT-4o」を超えています。この比較は、マルチモーダル数学的思考を評価するための重要な手段です。
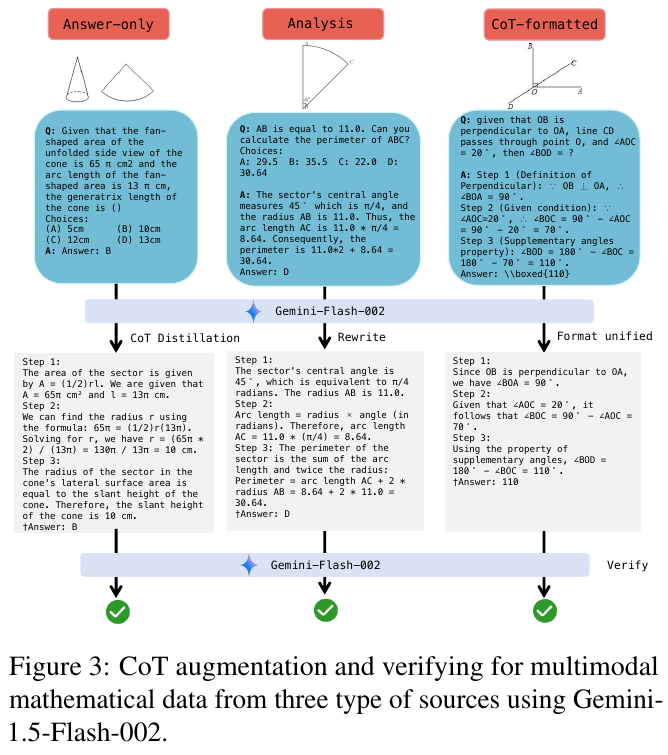
この図は、数学の問題における「チェーン・オブ・ソート」(CoT)推論の強化と検証プロセスを示しています。図は3つの異なるソースからの数学データのCoT拡充と検証の流れを描いています。左から右に、「Answer-only」(答えだけの形式)、「Analysis」(分析形式)、および「CoT-formatted」(CoT形式)が示されています。それぞれの例題は問題文、選択肢、解答が記載され、下方にGemini-Flash-002を用いて、「CoT Distillation」(CoT抽出)、「Rewrite」(書き換え)、「Format unified」(形式統一)が行われ、最終的に推論と検証が行われます。この手法により、複数のデータ形式を統一的に処理し、数式推論の精度を向上させることを目的としています。
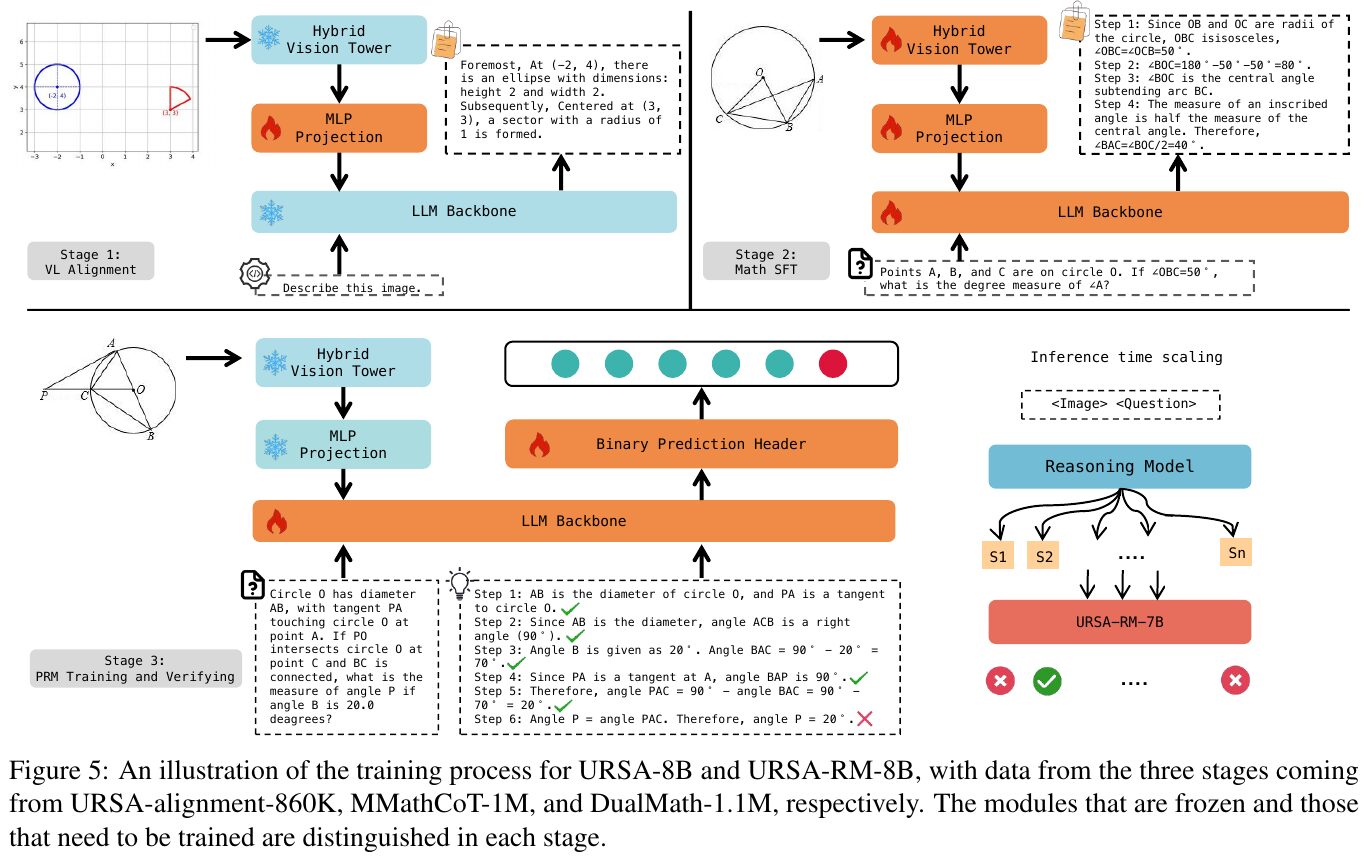
この図は、URSA-8BとURSA-RM-8Bのトレーニングプロセスの概要を示しています。プロセスは三つのステージに分かれ、異なるデータセットを使用します。第一段階の「視覚と言語のアライメント」では画像とテキストの関連性を調整します。第二段階の「数学ドメインの監督下での洗練」は、MMathCoT-1Mを使用して数学領域での推論能力を向上させます。最後の段階「PRMトレーニングと検証」は、誤りの検出と修正を通じてモデルの精度を高める役割を果たします。各モジュールは凍結または再トレーニングされています。最終的に、これらのステージがモデルの効果的な推論能力の強化に繋がります。
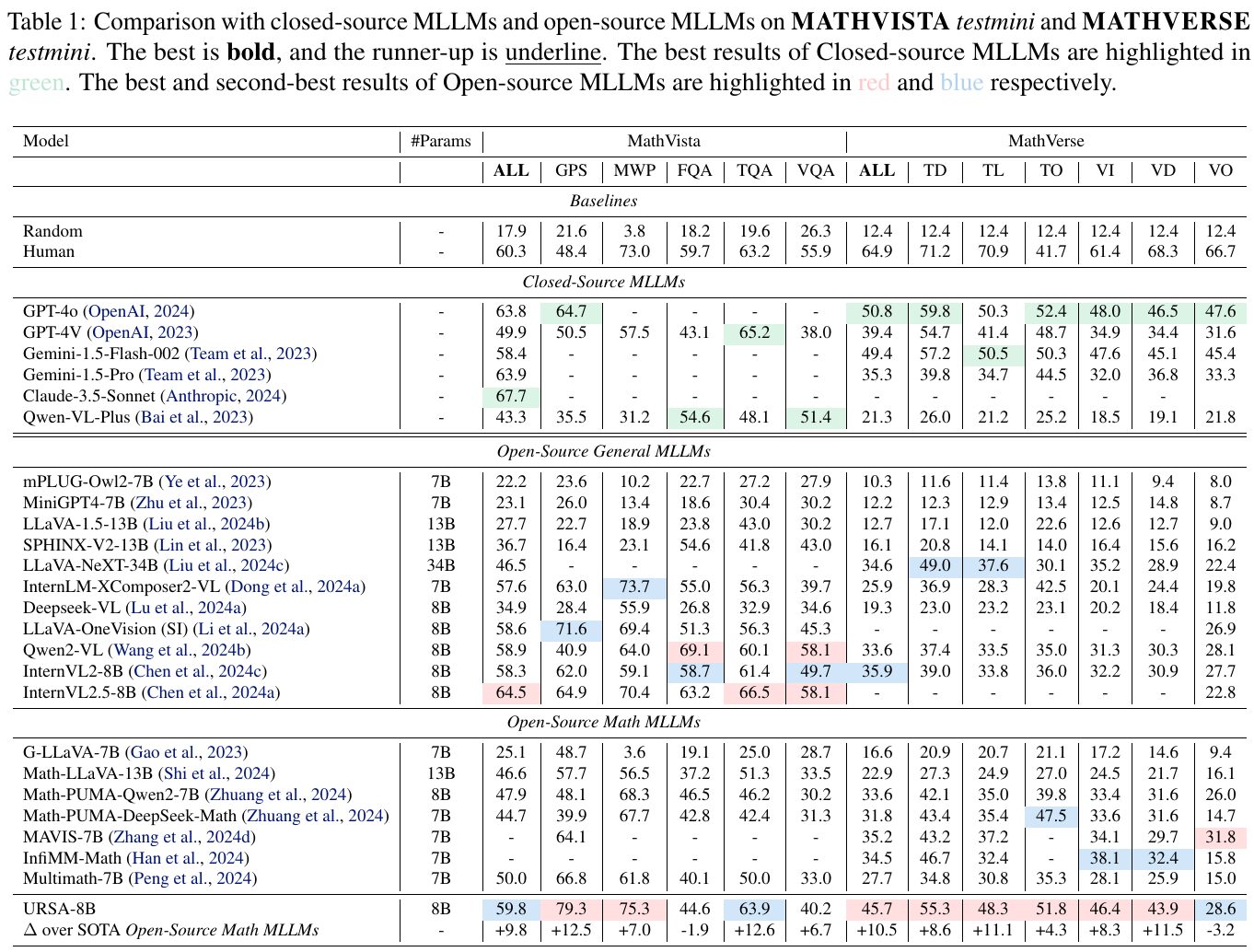
画像の表は、閉鎖型とオープンソースの多言語数学モデル(MLLMs)の性能を比較しています。MathVistaとMathVerseというベンチマークで評価した結果が示されており、最も良い結果は太字で、次に良い結果は下線で表現されています。緑色は閉鎖型モデルの最良結果を、赤と青はオープンソースモデルの最良および次に良い結果を示しています。URSA-8BはMathVistaの全体で79.3%、MathVerseでは63.9%のスコアを達成し、オープンソースの他の数学モデルを上回る新たなベンチマークを設定しています。このことから、このモデルが数学的推論において高い性能を発揮していることがわかります。
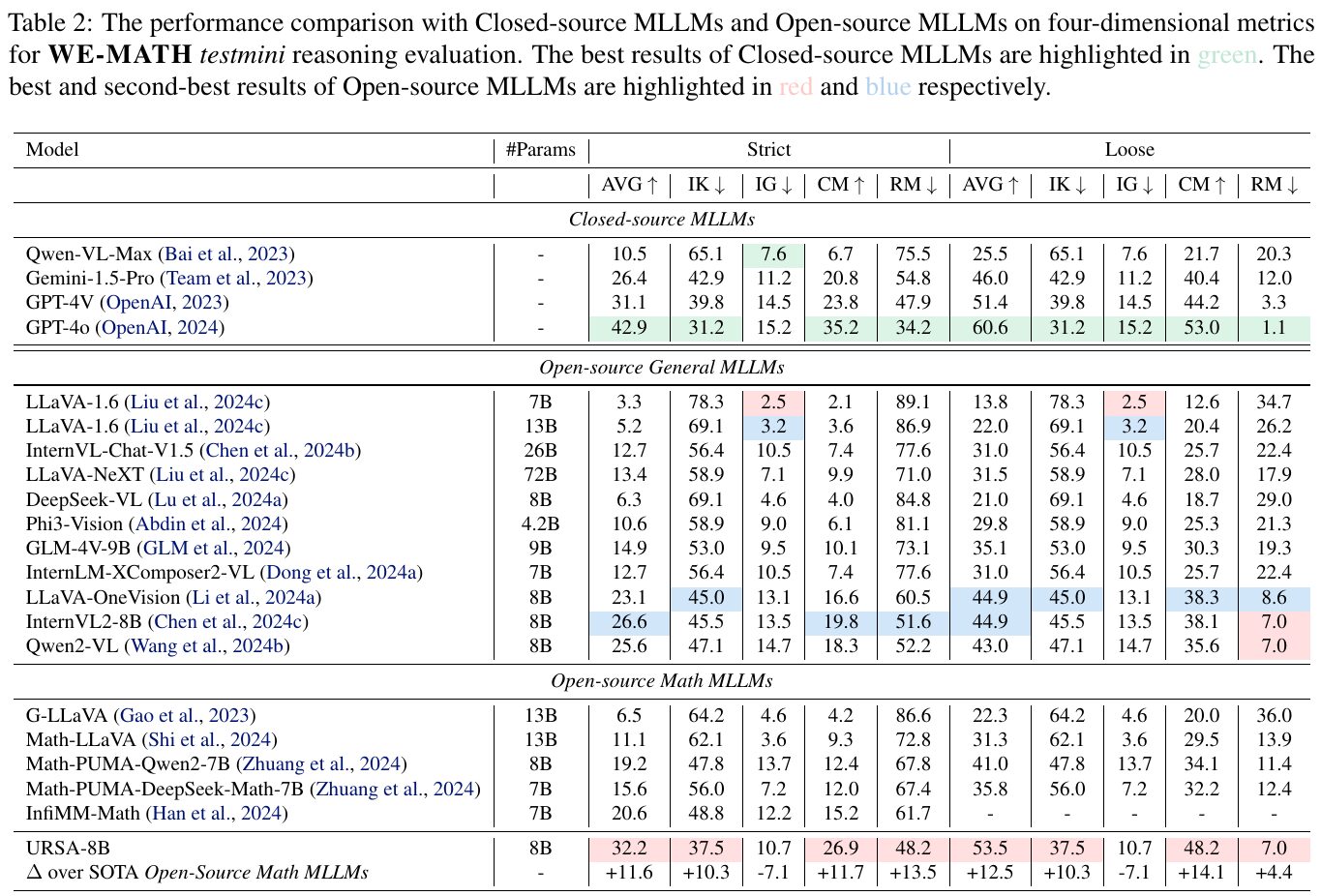
この画像は、閉じたソースとオープンソースのマルチモーダル大規模言語モデル(MLLM)の性能を、WE-MATHのテスト評価で比較したものです。表では、異なるモデルが特定の指標でどう評価されるかが示されています。閉じたソースのモデルの最高値は緑色で示され、オープンソースのモデルの一番良い結果と次に良い結果は、それぞれ赤色と青色で示されています。 具体的には、URSA-8Bはオープンソースモデルの中で特に優れた結果を示し、最先端のオープンソースの数学モデルと比較しても高い性能を発揮しています。これにより、URSA-8Bはその推論能力において、大幅な優位性を持つことが示されています。
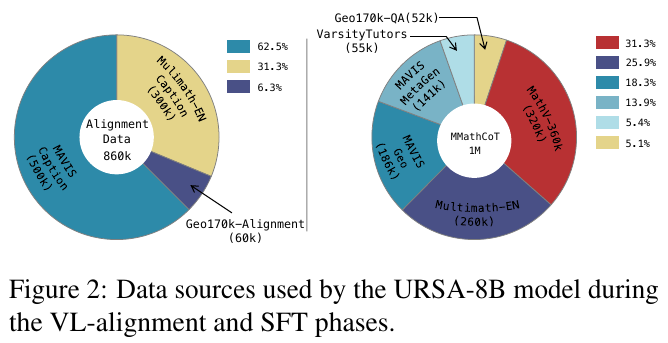
画像は、URSA-8Bモデルが用いたデータソースを示しています。左の円グラフは、視覚と言語の整合性アルゴリズムにおけるデータの比率を示しています。例えば、MAVISキャプションやMultimath-ENが主要なデータソースであり、それぞれ62.5%および31.3%の割合を占めています。右の円グラフでは、SFT (Supervised Fine-Tuning)フェーズのデータソースが示されており、Multimath-ENとMMathCoTが主要な構成要素として含まれています。これらのデータは、URSA-8Bのモデル強化に大きく寄与していることがわかります。
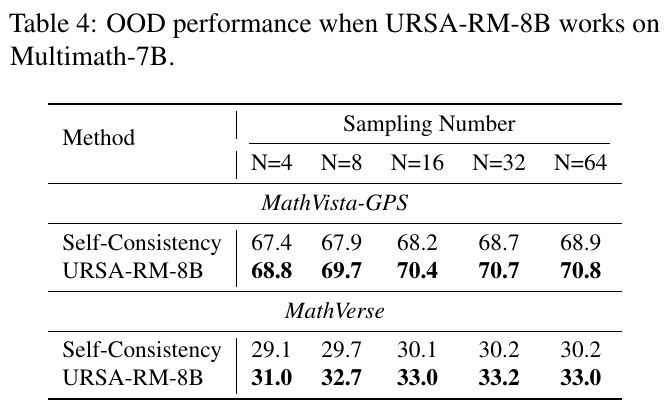
この表は、URSA-RM-8BがMultimath-7Bで動作した際のOOD(アウト・オブ・ディストリビューション)性能を示しています。表は、異なるサンプリング数(N=4, N=8, N=16, N=32, N=64)の下で、MathVista-GPSとMathVerseの2つの手法「自己一貫性」と「URSA-RM-8B」の結果を記録しています。 結果を見ると、URSA-RM-8Bはどのサンプリング数でも「自己一貫性」を上回る性能を示しています。特に、サンプリング数が増えるにつれて精度が向上する傾向が見られます。MathVista-GPSでは最高70.8、MathVerseでは最高33.3の性能を達成しています。これは、URSA-RM-8Bがより正確かつ信頼できる数学的推論を提供できることを示唆しています。
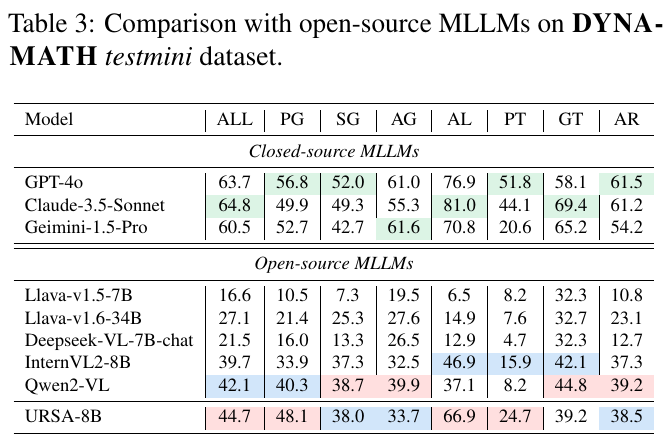
この表は、DYNAMATH testminiデータセットを用いて、閉じたソースのMLLMsとオープンソースのMLLMsを比較しています。各モデルの成績は、様々な数学分野の評価として示されています。表に含まれる項目は、例えばPG(平面幾何学)、SG(立体幾何学)、AL(代数)などです。 閉じたソースのモデル、例えばGPT-4oやClaude-3.5-Sonnetは、全体的に高い成績を示しています。特にALやARの項目で優れた性能を発揮しています。一方、オープンソースモデルのURSA-8Bも健闘しており、66.9%の成績を示しています。これは、ALなどの特定の分野での強みを示しています。表を通じて、URSA-8Bは、特にオープンソースの文脈で競争力のある性能を示していることがわかります。