- REINFORCE++はLLMの性能を向上させるためのシンプルで効率的な手法
- トークンレベルのKL正則化と簡素な方策更新により安定した学習を実現するアプローチ
- 一般化性能やコスト効率でPPOと同等以上の結果を示す実験結果
論文:REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
論文「REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models」(REINFORCE++)は、LLMの性能調整において、シンプルかつ効率的な方法を提供する手法を提案しています。中心となるアプローチは、強化学習手法であるREINFORCEを改良し、新たな強化学習フレームワークとして実装することで、LLMのトレーニング安定性と収束効率を向上させるものです。特に、PPO(Proximal Policy Optimization)を用いる従来手法の制約を解消しつつ、計算効率性を高めています。
REINFORCE++の特徴的な改良点は以下の3つです。まず、トークンレベルのKL正則化を導入することで、強化学習モデルと教師あり学習モデル間の不一致を抑制します。次に、PPOではなく、より簡素で直接的な方策更新方式を採用することで、計算資源を節約しつつも安定した学習を実現します。最後に、小規模なバッチ処理や正規化(リワードのスケーリング)を採用し、外れ値対策や一般化性能の向上を図っています。
実験では、汎用領域と数学に特化した領域の2種類のデータセットを用いて評価を行いました。その結果、REINFORCE++は、特にブラッドリー・テリー報酬モデルを活用した際に、PPOや他の手法と同等以上のパフォーマンスを示し、トレーニングの安定性やコスト効率の面でも優位性を発揮しました。たとえば、PPOと比べて1エポックあたりの計算コストを大幅に削減しつつ、同等の全体的な性能を達成しています。また、LLMの学習中の報酬分布の変動を効果的に抑えることが確認されました。
図表の解説
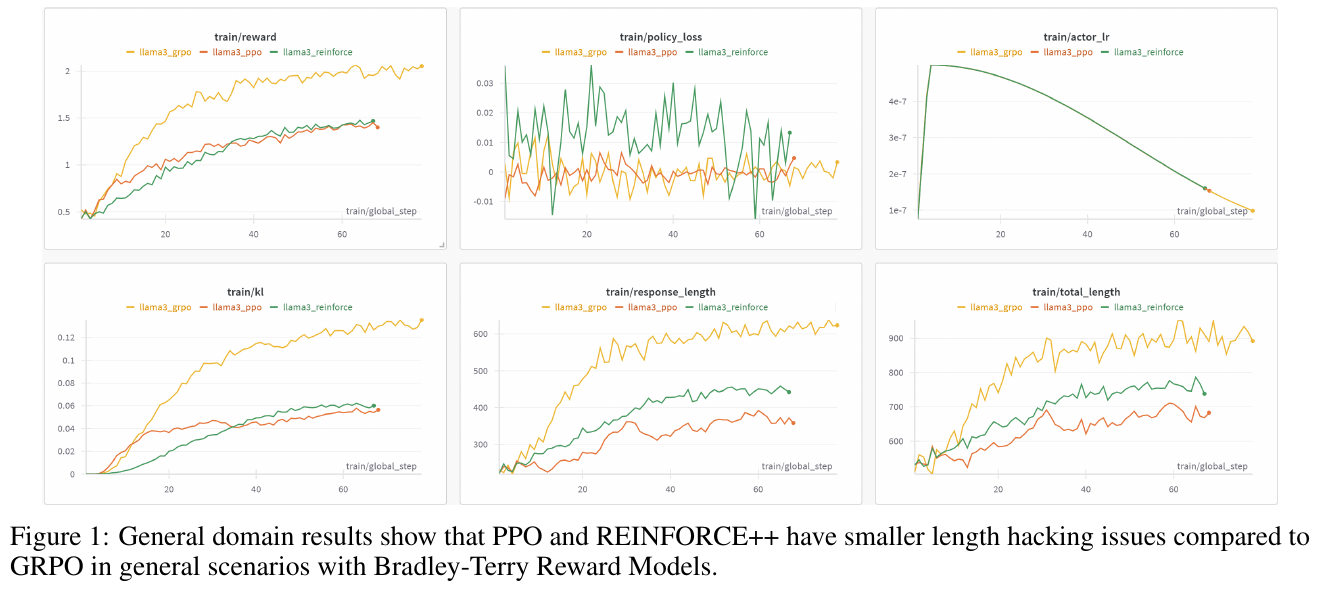
この図は、PPOとREINFORCE++が、一般的なシナリオでの出力長の最適化問題(「長さハッキング」)において、GRPOよりも優れていることを示しています。図の6つのグラフは、さまざまな学習指標の進行を示しています。例えば、「train/reward」は、時間とともに報酬がどのように変化するかを示し、PPOとREINFORCE++が安定した報酬の増加を示しています。「train/response_length」と「train/total_length」のグラフは、REINFORCE++とPPOが出力長を抑制していることを示しています。これらの結果から、REINFORCE++は計算の効率性を維持しつつ、PPOに匹敵する性能を示すことがわかります。
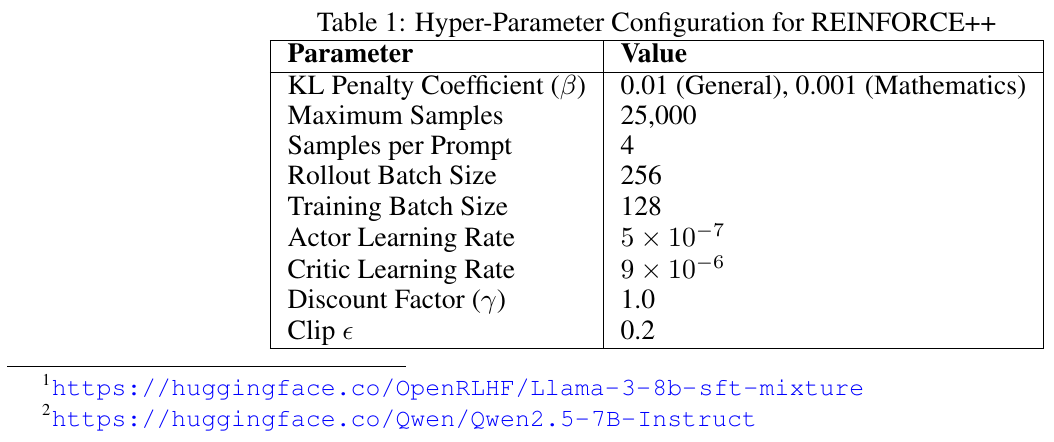
この図は、REINFORCE++のハイパーパラメータ設定を示しています。REINFORCE++は、従来のREINFORCEアルゴリズムを強化したもので、人間のフィードバックから学習する強化学習(RLHF)に用いられます。表には、KLペナルティ係数、最大サンプル数、プロンプトごとのサンプル数、ロールアウトとトレーニングのバッチサイズ、アクターとクリティックの学習率、割引係数、クリップ値といった具体的なパラメータが示されています。これらの設定は、モデルの安定したトレーニングを確保し、計算効率を向上させることを目的としています。特に、一般と数学のシナリオで異なるKLペナルティ係数が設定されています。
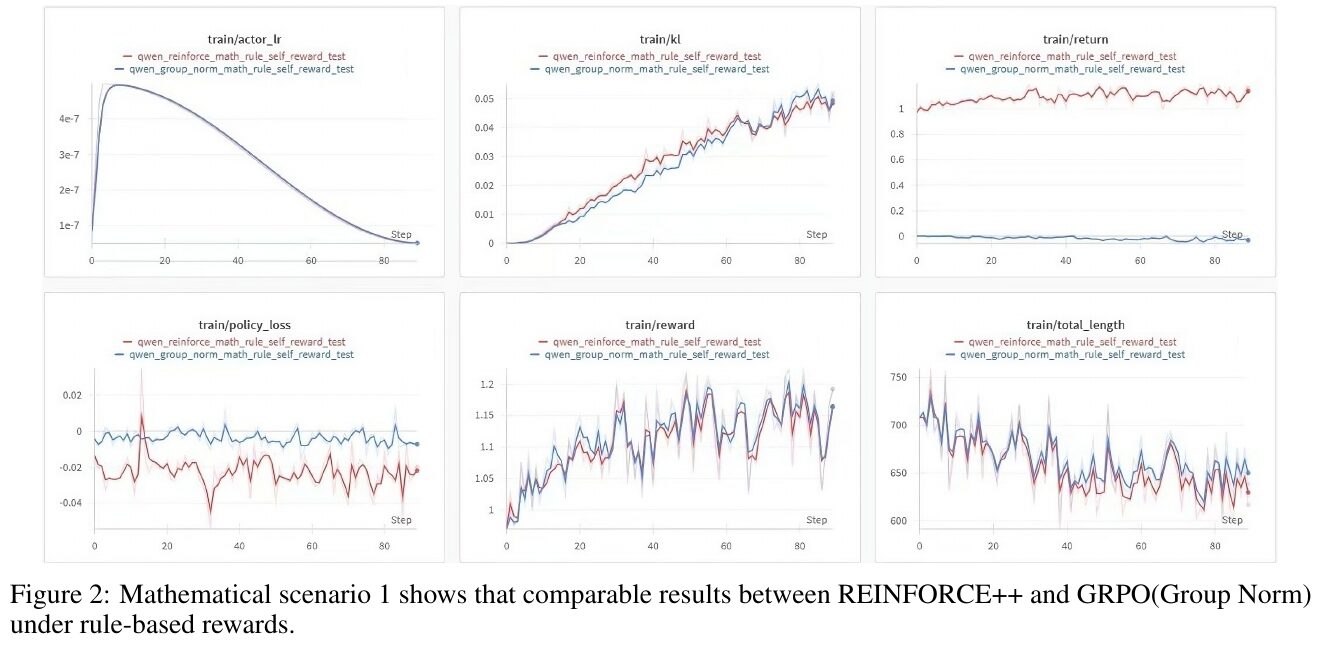
図2は、数学的シナリオにおけるREINFORCE++とGRPO(グループノルム)の比較を示しています。この図は6つの異なるメトリックに焦点を当てています。 「train/actor_lr」は、学習率が時間とともに減少する様子を示しており、両者のアプローチで同様のパターンが見られます。「train/kl」では、両手法ともにKLダイバージェンスが徐々に増加しています。「train/return」は、REINFORCE++が一貫して高いリターンを示し、GRPOに比べてパフォーマンスが高いことを示しています。 「train/policy_loss」と「train/reward」は、報酬の変動に関して両手法がほぼ同じ動きを示しています。「train/total_length」は、出力の長さに関するもので、ステップごとに変化が見られます。この結果から、REINFORCE++はGRPOと比較して対象のシナリオで同程度の性能を保ちながらも、より安定した訓練を実現していることがわかります。
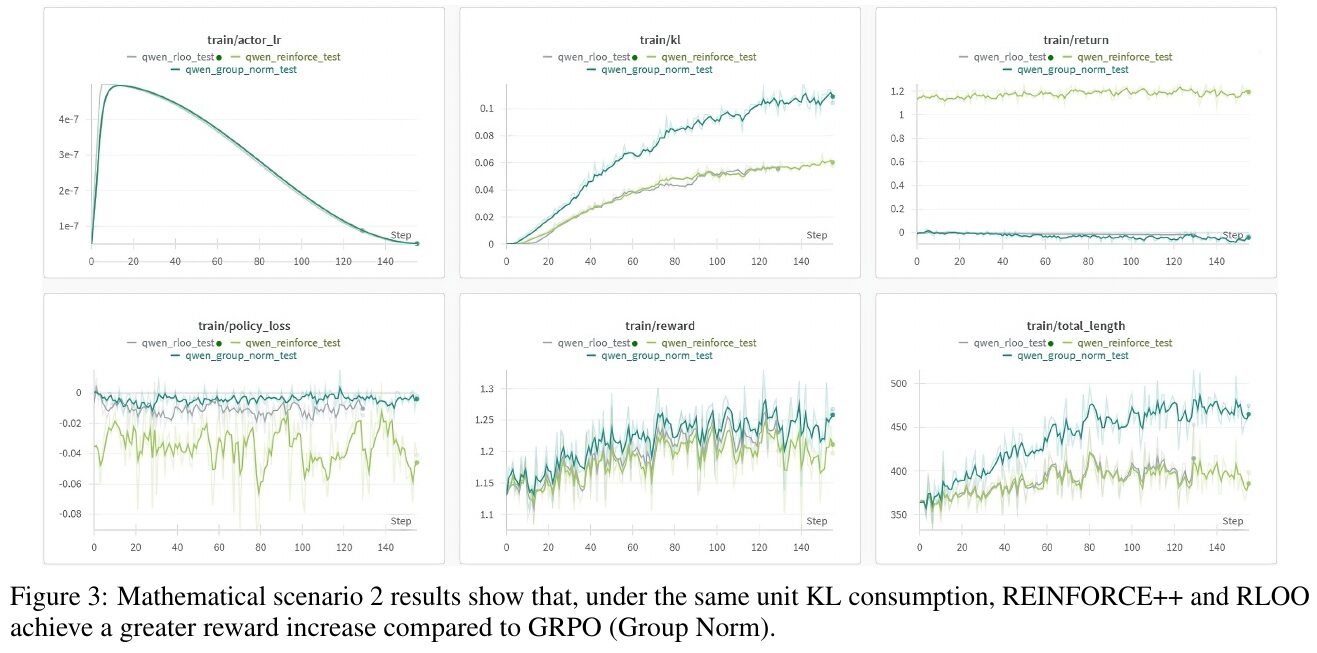
この図には、数学的シナリオ2における3つのグラフが示されています。説明では、REINFORCE++とRLOOが、GRPO(Group Norm)と比較して、同じKL消費単位当たりの報酬の増加を達成していることが報告されています。 左上のグラフ「train/actor_lr」は、トレーニング中の学習率の変化を示しています。中央上のグラフ「train/kl」はKLダイバージェンスの推移を示し、安定性を評価する指標となっています。右上の「train/return」は累積報酬の測定を表し、手法の効果を示します。下のグラフ群では、ポリシーロスや報酬の推移、トータルのエピソード長が示され、全般的にREINFORCE++とRLOOが良好なパフォーマンスを示していることがわかります。
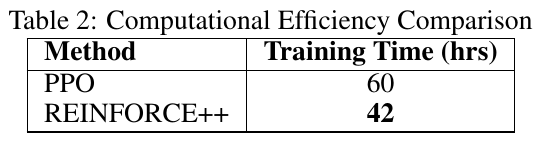
この画像は、PPOとREINFORCE++という2つの異なる強化学習アルゴリズムの計算効率を比較した表です。表によると、PPOのトレーニング時間は60時間であるのに対し、REINFORCE++は42時間で済んでいます。これにより、REINFORCE++がPPOと同等のパフォーマンスを維持しながら、より効率的にトレーニングできることが示されています。REINFORCE++は、PPOで必要な批判ネットワークを排除することによって計算の負担を軽減し、同時にトレーニングの安定性を向上させています。この研究は、大規模な言語モデルのトレーニングにおける簡素化と効率化を目的として進められています。
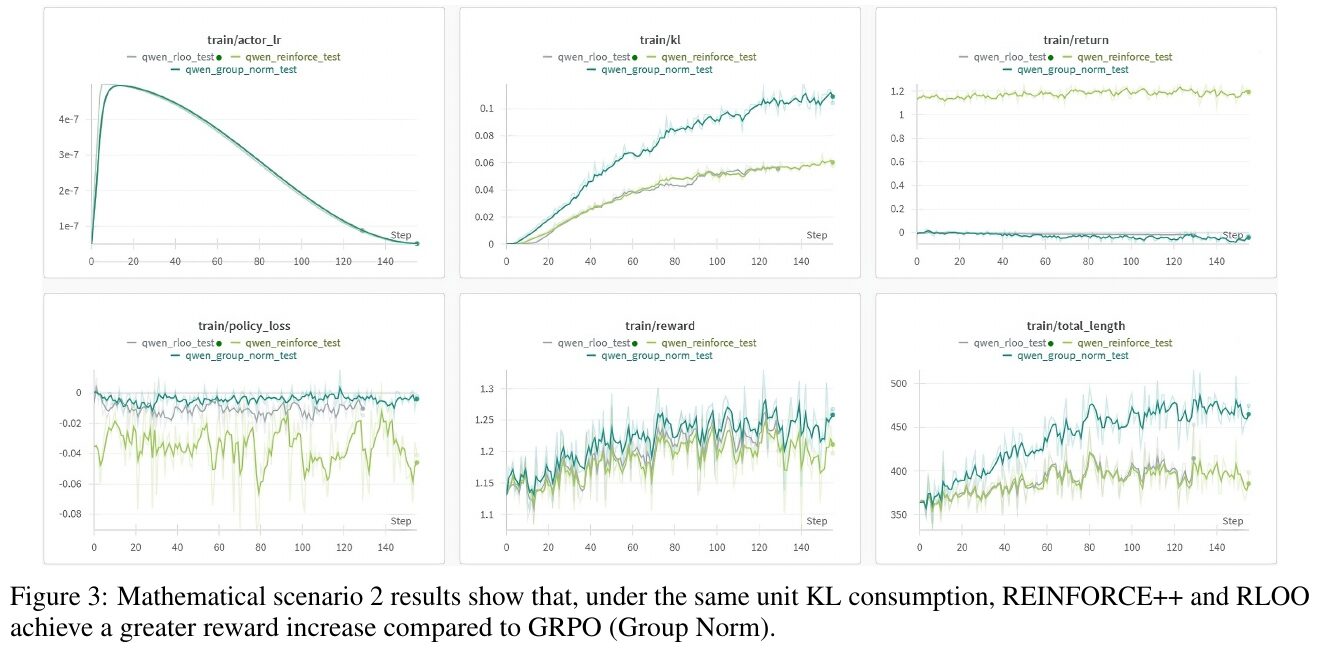
図3は、数学的シナリオ2における比較結果を示しています。この図では、REINFORCE++とRLOOが、同じ単位のKL消費のもとで、GRPO(グループノーム)よりも大きな報酬の増加を達成することが示されています。 各グラフは異なる測定項目を示しており、左上から順に、学習時のアクターの学習率、KLダイバージェンス、リターン、ポリシーロス、報酬、エピソードの全長を表しています。特に報酬のグラフでは、REINFORCE++とRLOOが優位性を示しており、これはデータ量を効率よく報酬増加に繋げた結果です。全体として、REINFORCE++とRLOOのアプローチが、より良いパフォーマンスを発揮していることが分かります。
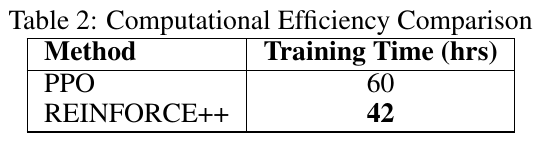
この表は、「REINFORCE++: A SIMPLE AND EFFICIENT APPROACH FOR ALIGNING LARGE LANGUAGE MODELS」という論文からのもので、PPO(Proximal Policy Optimization)と新たな手法であるREINFORCE++の訓練時間を比較しています。表からわかるように、PPOは60時間の訓練時間が必要であるのに対し、REINFORCE++は42時間と短縮されています。これは、REINFORCE++がPPOに比べて計算効率が高いことを示しています。これにより、モデル訓練におけるコストや時間を削減しつつ、同等の性能を維持できることが強調されています。
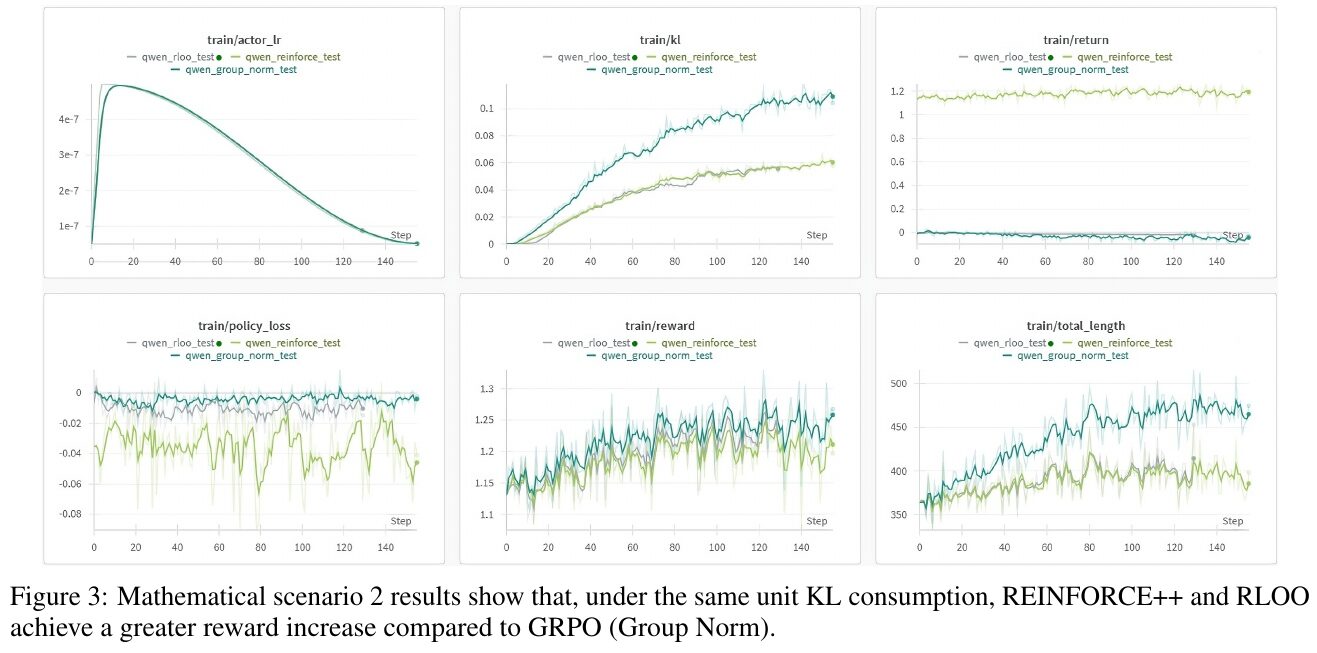
この画像は、論文の「数学シナリオ2」の結果を示しています。図は、REINFORCE++とRLOO(REINFORCE Leave One-Out)の2つのアルゴリズムが、特定の条件下でGRPO(Group Norm)よりも大きな報酬の増加を達成していることを示しています。6つのグラフは、さまざまなトレーニング指標(例えば、学習率、KLダイバージェンス、報酬、ポリシーロスなど)におけるパフォーマンスを比較しています。特に注目すべきは、REINFORCE++とRLOOが、同じKL消費量のもとで、より効果的に報酬を増やせている点です。これにより、これらのアルゴリズムが効率的で信頼性の高い手法であることが示唆されています。