
この論文では、多言語対応のテキスト埋め込みモデル「jina-embeddings-v3」を提案しています。特定のタスクに最適化されたLoRAアダプターを導入し、効率的に高品質な埋め込みを生成できるようになり、多言語データや長文検索タスクでのパフォーマンスが向上し、実用的な利用が可能となっています。
論文:jina-embeddings-v3: Multilingual Embeddings With Task LoRA
HuggingFace:https://huggingface.co/jinaai/jina-embeddings-v3
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
本論文は、「jina-embeddings-v3」という多言語対応のテキスト埋め込みモデルを提案しています。
本研究のポイントは以下の通りです。
つまり、多様なタスクに対応可能で効率的な埋め込み生成が実現し、AIの実用性を大きく向上させた研究です。
背景
従来の埋め込みモデルは、特定のタスクに対するファインチューニングが必要でした。また、パラメータ数が非常に大きいため、実際のアプリケーションでの運用には課題がありました。
提案手法
この論文で提案されている「jina-embeddings-v3」は、多言語対応のテキスト埋め込みモデルで、特定のタスクに適応するLoRA(Low-Rank Adaptation)アダプターを組み込んでいます。この手法は、クエリ・ドキュメント検索、クラスタリング、分類、テキストマッチングなど、異なるタスクに対して高品質な埋め込みを生成することを目的としています。
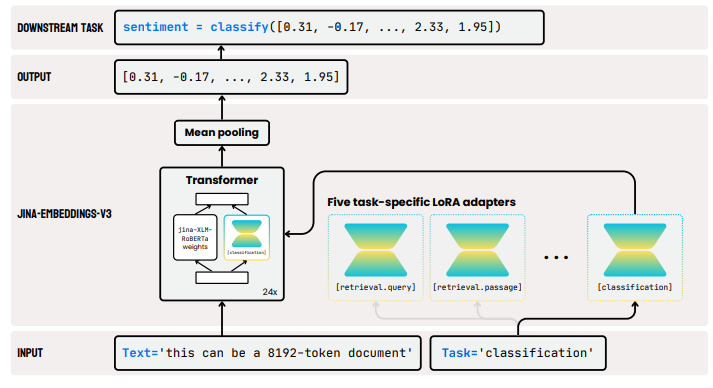
モデルの設計には、XLM-RoBERTaモデルをベースにしており、タスクごとの埋め込み最適化が可能なアダプターを追加しています。このアダプターは、元のモデルの重みを固定したまま、新たなタスクに適応する低ランクの行列を学習させる仕組みです。このため、モデル全体のメモリ消費を抑えながら、タスクごとの埋め込み生成が可能になります。
「jina-embeddings-v3」は、長い文脈に対応するために、通常の位置エンコーディングではなくRoPE(Rotary Position Embeddings)を採用しています。そのため、最大で8192トークンまでの長いシーケンスを処理でき、長文検索や複雑な文脈理解にも対応可能です。

また、Matryoshka Representation Learningを利用することで、埋め込みの次元を1024から32まで柔軟に調整でき、性能を維持しつつコンパクトな表現を実現しています。
実験
実験は大きく分けて、以下の3つのフェーズに分けられています。
- モデルの基盤となるXLM-RoBERTaの性能評価
- 埋め込みタスクでの比較評価
- リトリーバルタスク
まず、XLM-RoBERTaの評価では、英語と多言語のタスクに対して、既存のマルチリンガルモデルであるmBERTやXLM-RoBERTaと比較されました。その結果、「jina-embeddings-v3」は、特に英語のタスクで高いスコアを記録し、多言語対応力も向上していることが確認されました。
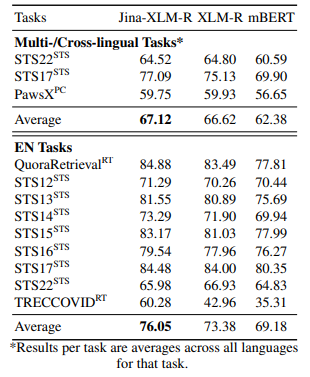
次に、埋め込みタスクでの性能評価では、さまざまなMTEB(Multilingual Text Embedding Benchmark)タスクにおいて、モデルの分類、クラスタリング、再ランク付けなどの性能が比較されました。「jina-embeddings-v3」は、特に英語の分類と文の類似性タスクで最も高いスコアを達成し、他の最新のモデルよりも安定して高い性能を示しました。
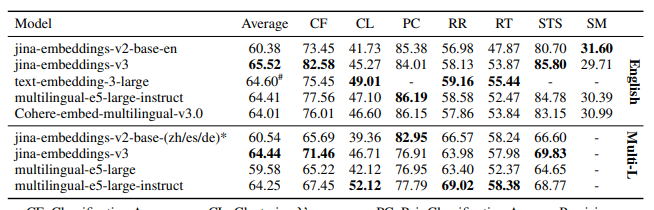

リトリーバルタスクでは、従来の埋め込みモデルが抱える障害ケースの特定とその改善が行われました。具体的には、合成データを用いた訓練によって、名前付きエンティティの誤認識や、文法的に似ているが意味的には異なるドキュメントの誤ったランク付けの改善が確認されています。
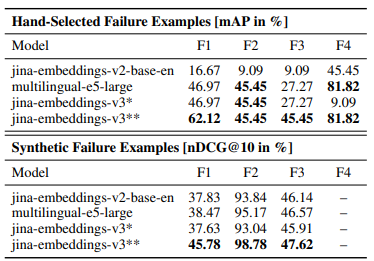
また、LoRAアダプターを用いることで、クエリとドキュメントの埋め込みをそれぞれ最適化する手法が有効であることが示されました。
結論
この論文の結論では、「jina-embeddings-v3」が多言語対応の埋め込みモデルとして非常に優れたパフォーマンスを発揮し、特定のタスク向けに最適化されたLoRAアダプターがモデルの性能を大幅に向上させることが確認されました。
特に、長文検索や多言語対応が求められるタスクにおいて、従来のLLMに匹敵する性能を維持しながら、計算資源の効率性とコスト面での優位性を実現しています。
今後の課題としては、低リソース言語での性能向上や、データの少ないタスクに対するモデルの強化が挙げられています。