- ユーザーの履歴情報をグラフ構造で利用して、カスタマイズされた応答を生成する手法「PGraphRAG」を提案
- 12種類のタスクを使ってPGraphRAGの性能を評価し、多くのタスクで高いパフォーマンスを示す結果を獲得
- アブレーションスタディを通じて、リトリーバル範囲やデータ量がモデル性能に及ぼす影響を分析
論文:Personalized Graph-Based Retrieval for Large Language Models
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この論文では、LLM(大規模言語モデル)のパーソナライゼーション性能を向上させるための手法「Personalized Graph-based Retrieval-Augmented Generation(PGraphRAG)」を提案しています。この手法は、レビューや評価データなどの構造化情報を基に、ユーザーの文脈や好みに応じたカスタマイズされた応答を生成することを目的としています。
PGraphRAGは、ユーザーの履歴情報をノードおよびエッジとして扱うグラフ構造を活用し、関連する情報を効率的にモデルに供給します。具体的には、ユーザーごとにピアグラフを構築し、それをLLMによる生成プロセスに統合します。グラフのリトリーバル方法には、ユーザー履歴のみを活用する「User-Only」、近接ユーザーの履歴も考慮する「Neighbors Only」、全ての履歴情報を利用する「All」などの設定が試されています。
また、本研究ではPGraphRAGの性能を評価するため、「ユーザーレビュー生成」「マルチリンガルレビュータイトル生成」など12種類のタスクを設計した専用のデータベンチマークを作成しました。結果として、PGraphRAGは従来モデルより言語生成や感情分析タスクで顕著に性能を向上させ、特に「ユーザーに密接した文脈情報を必要とするタスク」で大きな優位性を示しました。これは、ユーザーの履歴から最も関連性の高い情報を効果的に抽出し、それを生成に結びつける能力が寄与しているとしています。
図表の解説
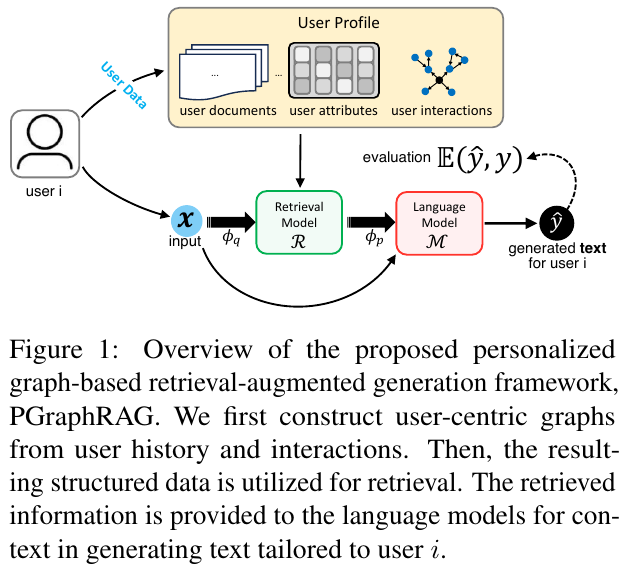
図1は、提案された個別化グラフベースの情報検索・生成フレームワーク「PGraphRAG」の概要を示しています。まず、ユーザーの履歴やインタラクションからユーザー中心のグラフを構築し、その結果得られた構造化データが情報検索に活用されます。この情報は言語モデルに提供され、ユーザーiに合わせたテキスト生成のためのコンテキストとして利用されます。これにより、より個別化された、コンテクストに基づく適切な応答が可能になります。このアプローチは、特にデータが少ない状況でも効果的です。
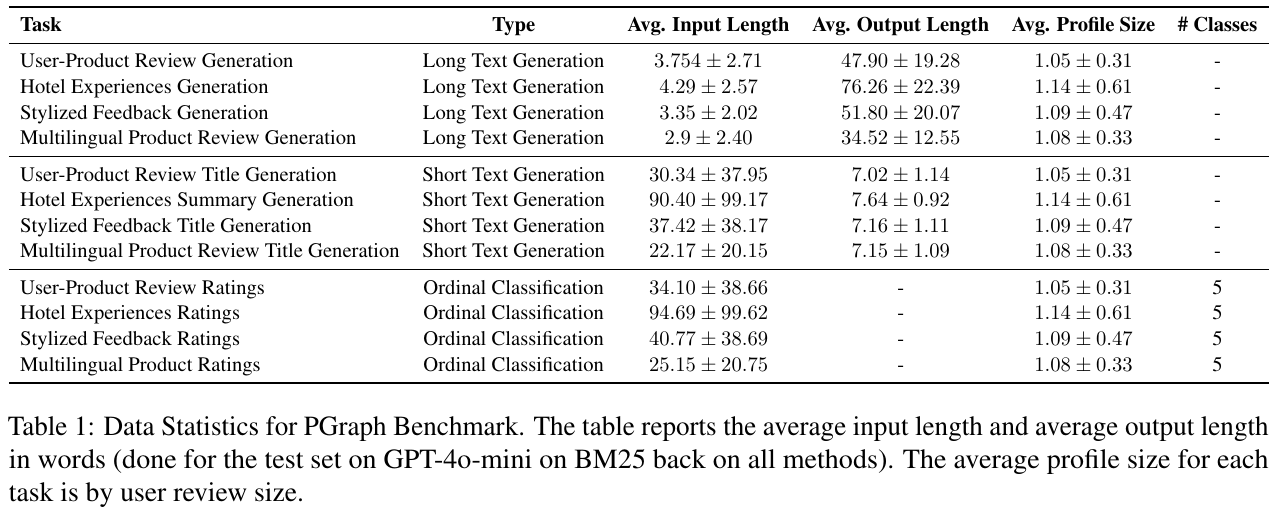
この画像は、データベンチマーク「PGraph」の統計情報を示しています。表には、さまざまなタスクの入力と出力の平均長さ、プロフィールサイズ、そして分類タスクのクラス数が記載されています。具体的には、「長文生成」や「短文生成」、「序数分類」に関するタスクが並べられています。それぞれのタスクで入力と出力の長さが異なり、たとえば「ホテル体験生成」の平均出力長さは他と比較して長いです。これらの統計は、ユーザーレビューのサイズに基づいており、研究の基盤として使用されるサンプルデータを特徴付けています。たとえば、序数分類タスクでは、5つのクラスに渡って評価が行われています。
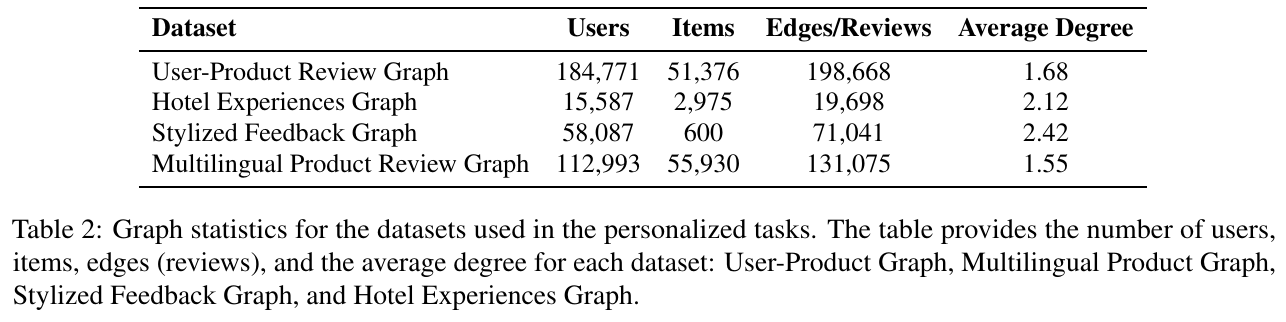
この表は、さまざまなグラフベースのデータセットにおけるデータ統計を示しています。具体的には、ユーザー数、アイテム数、エッジ(レビュー)数、そして各グラフにおける平均次数が記載されています。主な対象となるデータセットには、「User-Product Review Graph」、「Hotel Experiences Graph」、「Stylized Feedback Graph」、「Multilingual Product Review Graph」があります。 「User-Product Review Graph」には最も多くのユーザー(約18万4771人)がおり、エッジ数は19万8668です。一方、「Hotel Experiences Graph」はユーザー数が1万5587人でエッジは1万9698と少なめです。平均次数は「Stylized Feedback Graph」が2.42と最も高く、他のグラフよりもユーザーとアイテムの関係性が密接であることを示しています。この統計は、パーソナライズされたタスクでのデータセットの特性を理解するのに役立ちます。

図2は、Amazonのユーザープロダクトデータセットにおけるユーザープロフィールの分布を示しており、多くのユーザが少ないレビュー数で非常に小さなプロフィールサイズを持っていることを強調しています。ユーザのレビュー数に対する分布が対数スケールで表示されており、曲線はレビューが少ないユーザが圧倒的に多いことを示しています。赤い垂直線は、他のベンチマーク(例えば、LaMP、LongLaMP)での最小プロフィールサイズを示しています。この情報は、ユーザプロファイルが小さくても、個人化されたコンテンツ生成や情報検索におけるモデル評価において、データの制約を示す重要な指標となります。

この画像は、論文「Personalized Graph-Based Retrieval for Large Language Models」からのもので、4つのデータセットにおける訓練、検証、およびテストのデータ分割サイズを示しています。各データセット名と対応するデータサイズが表にまとめられています。「User-Product Review」や「Multilingual Product Review」では20,000の訓練例を持ち、検証とテストにはそれぞれ2,500の例があります。「Hotel Experiences」は訓練例が9,000で、検証とテストはやはり2,500ずつあります。これらのデータセットは、個別化されたテキスト生成モデルの開発と評価に使用されており、特にユーザ履歴が乏しい場合でも、モデルの性能を検証できるようになっています。
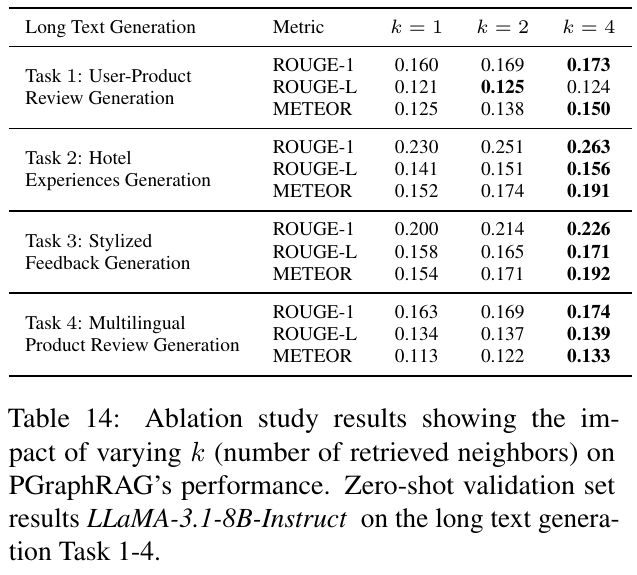
この図は、長文生成タスクでPGraphRAGモデルにおける取得数kの変化が性能に与える影響を示しています。具体的には、4つのタスク(ユーザープロダクトレビュー生成、ホテル体験生成、スタイライズフィードバック生成、多言語レビュー生成)について、kが1, 2, 4の異なる場合のROUGE-1、ROUGE-L、METEORのスコアを比較しています。 結果から、kの値が大きくなると総じてスコアが向上する傾向が見られます。特にホテル体験生成タスクでは、k=4で最も高いスコアを示し、文脈の多様性や関連性が向上することがパフォーマンス向上につながることを示しています。しかし、ユーザープロファイルのデータが少ない場合は、必ずしも多くのレビューを取得できないこともあります。このようなコールドスタートの状況においても意味のある個別化が提供できる点が、本研究の重要な貢献です。
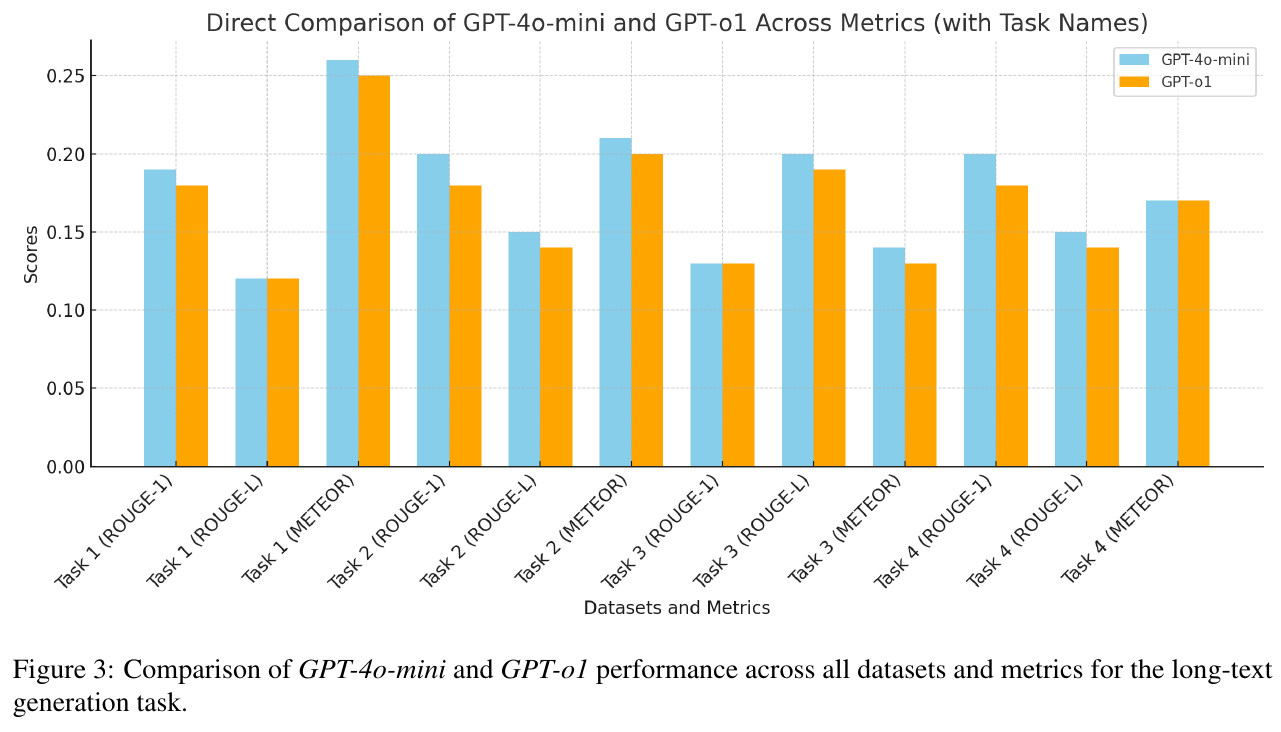
図3は、GPT-4o-miniとGPT-o1がさまざまなデータセットとメトリクスにおいてどのように性能を発揮するかを直接比較しています。各タスクに対して、ROUGE-1、ROUGE-L、METEORという測定基準を使用して評価されています。この図から、GPT-4o-miniがほとんどのタスクでGPT-o1を上回る傾向があることがわかります。特に、ROUGE-1とMETEORのスコアで顕著に優れたパフォーマンスを示しています。この結果は、GPT-4o-miniのほうが特定のタスクに適した長文生成能力を持っていることを示唆しています。この研究は、個別化されたテキスト生成の分野で、ユーザー中心の知識グラフを活用することで精度を向上させる可能性を探索する重要な一歩となります。
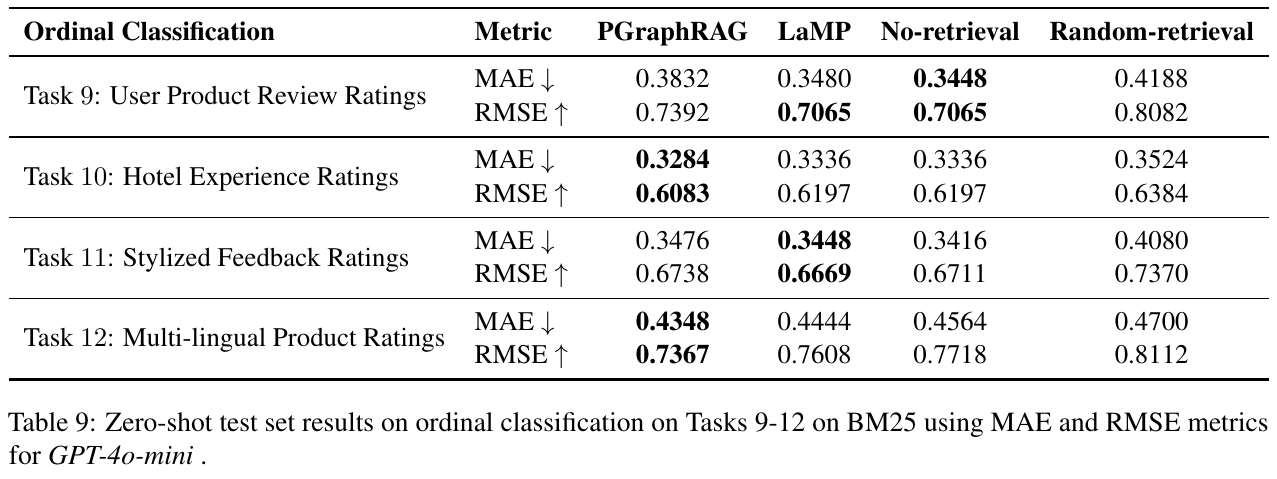
この表は、大規模言語モデル(LLMs)を用いた個別化されたテキスト生成のための手法「PGraphRAG」の評価結果を示しています。この方法は、ユーザープロダクトレビュー評価、ホテル体験評価、スタイライズされたフィードバック評価、多言語製品評価という4つの分類タスクについて、異なる手法の精度を比較しています。 特に、PGraphRAGは、多くのタスクで他の手法よりも優れた性能を示しています。例えば、ユーザープロダクトレビュー評価においては、MAE(平均絶対誤差)が低く、RMSE(平均平方二乗根誤差)が高いため、より精度の高い予測を行っています。これは、ユーザーに関連するコンテキストを活用することで、より正確な結果を出すことができることを強調しています。この方法は特に、ユーザーヒストリーが乏しい「コールドスタート」のシナリオで効果的です。