- 新しいフレームワーク「Dispider」が動画とLLMを統合してリアルタイム対話を実現
- 動画解析と応答生成を非同期で並行処理し、効率性を向上させた構造
- Dispiderが既存モデルよりも高い正確さと処理速度を達成した実験結果
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
本論文では、新しいフレームワーク「Dispider」を提案し、動画とLLMを統合してリアルタイムでの対話を可能にする仕組みについて説明しています。従来、動画とLLMを組み合わせたモデルは、処理速度の遅さやタイムリーな応答の欠如が課題でしたが、Dispiderではこれらの問題を解決するため、処理を分離して効率的に動作させる方法を採用しています。
Dispiderは、大きく分けて3つのモジュールで構成されており、それぞれが知覚、決定、応答生成を担当します。まず「知覚モジュール」が動画の入力を分析して重要な特徴を抽出します。次に「決定モジュール」がユーザーの質問に最も適した応答方法を選び出します。最後に「応答生成モジュール」がリアルタイムで適切な返答を生成します。また、非同期処理を可能にすることで、動画の分析と応答生成を並列的に行い、効率性を大幅に向上させています。
実験では、Dispiderの性能を定量的に評価しました。その結果、既存のモデルと比較して、動画理解、時系列の質問応答、映像の因果関係把握といった課題において優れた性能を示しました。特に、公開データセット「StreamingQA」や「Ego4D」などを用いたテストでは、他のアプローチよりも高い正確さと処理速度を達成しました。また、Dispiderは時間的に動的な質問や複雑な動画の文脈を理解する能力が強化されており、実時間での応答生成が可能である点が大きな利点となっています。
図表の解説
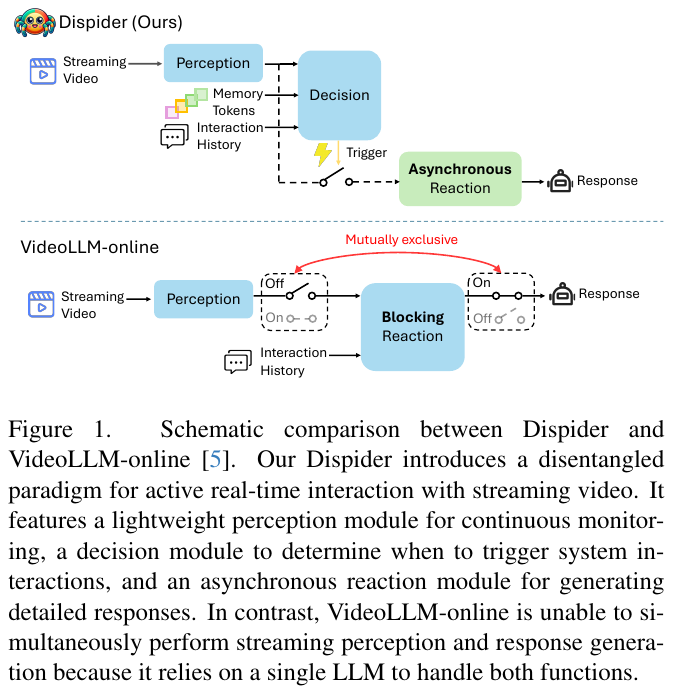
この図は、DispiderとVideoLLM-onlineという2つのシステムの比較を示しています。Dispiderは、ストリーミングビデオとリアルタイムで対話するための新しいシステムで、ペースを簡潔に知覚、判断、反応に分けています。具体的には、Dispiderは、連続的なビデオ監視を行う軽量の知覚モジュール、適切なタイミングで対話を開始するための判断モジュール、そして詳細な応答を生成する非同期の反応モジュールを備えています。一方で、VideoLLM-onlineは、ビデオの処理と応答生成を同時に行うことができず、反応が遅れることがあります。これにより、Dispiderは、長時間のビデオにおいても迅速かつ正確な応答が可能になります。
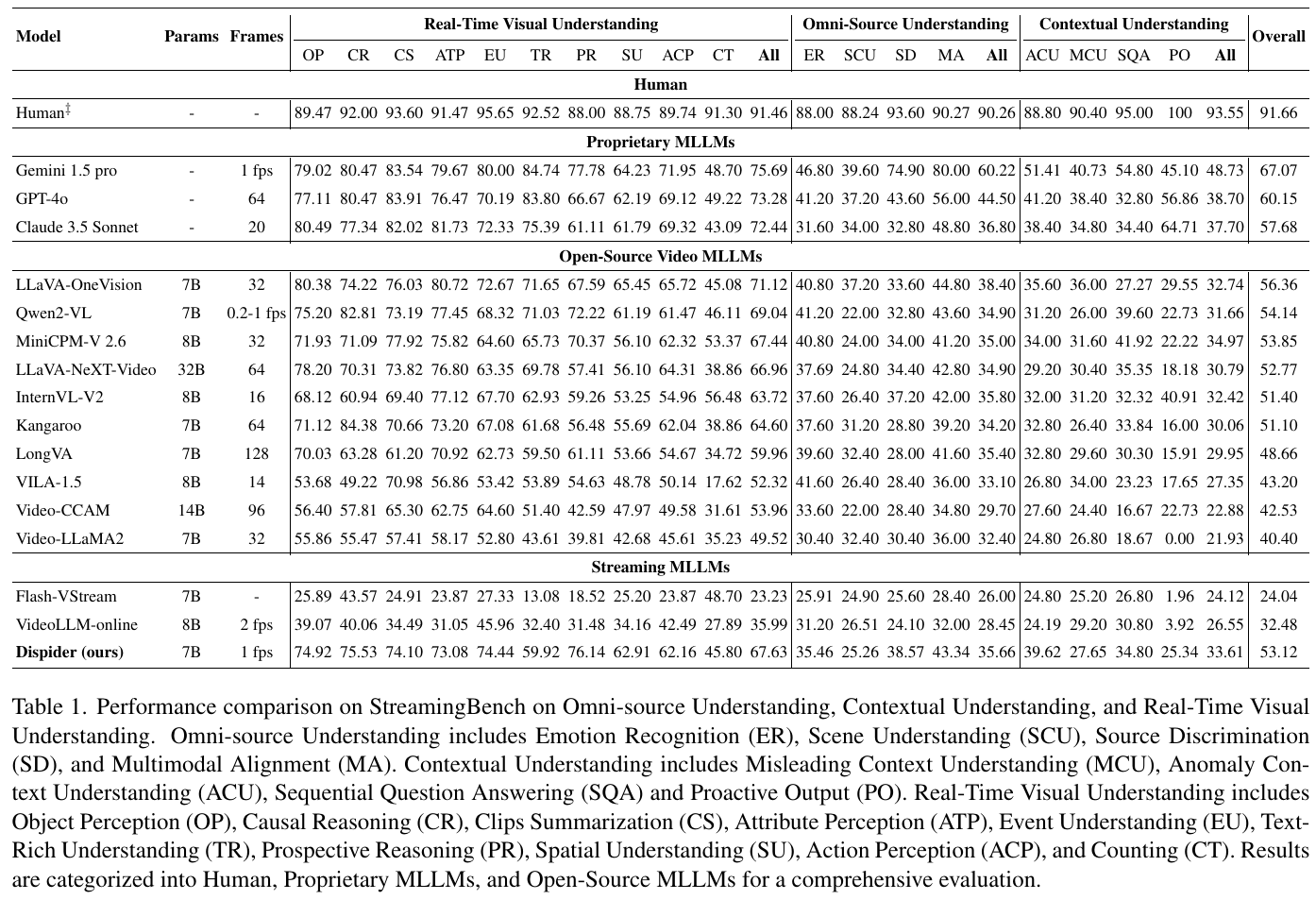
この表は、異なる動画大規模言語モデル(MLLMs)の性能を比較しています。評価はリアルタイムの視覚理解、オムニ・ソース理解、文脈理解の3つのカテゴリに分かれています。評価項目には、オブジェクトの認識や因果推論、クリップ要約、アトリビュート認識などが含まれています。 「Human」が最高のスコアを示しており、続いて独自開発のMLLMsとオープンソースのMLLMsが比較されています。「Dispider」はリアルタイムでの応答能力や文脈対応力で特に優れており、他のオンラインモデルと比較して高いスコアを獲得しています。これによってDispiderが様々な文脈で効果的に機能することが示されています。
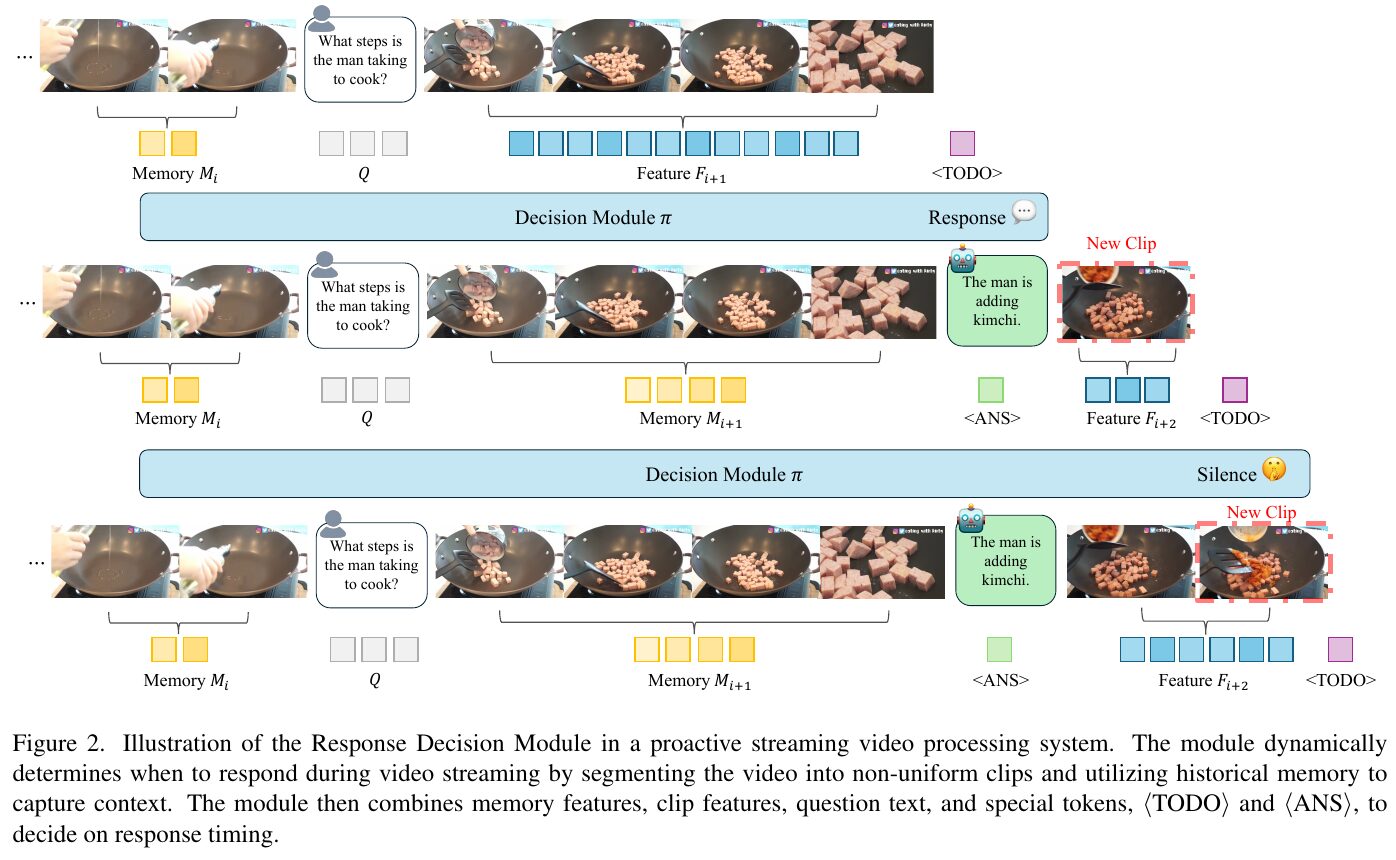
この図は、プロアクティブなストリーミング映像処理システムにおける「応答決定モジュール」を示しています。このモジュールは、ビデオを非均一なクリップに分割し、過去のメモリーを利用してコンテキストを把握することで、どのタイミングで応答するかを動的に判断します。図では、まずビデオクリップの特徴と質問が入力され、決定モジュールが応答するか継続処理するかを決定します。応答が必要と判断された場合、「
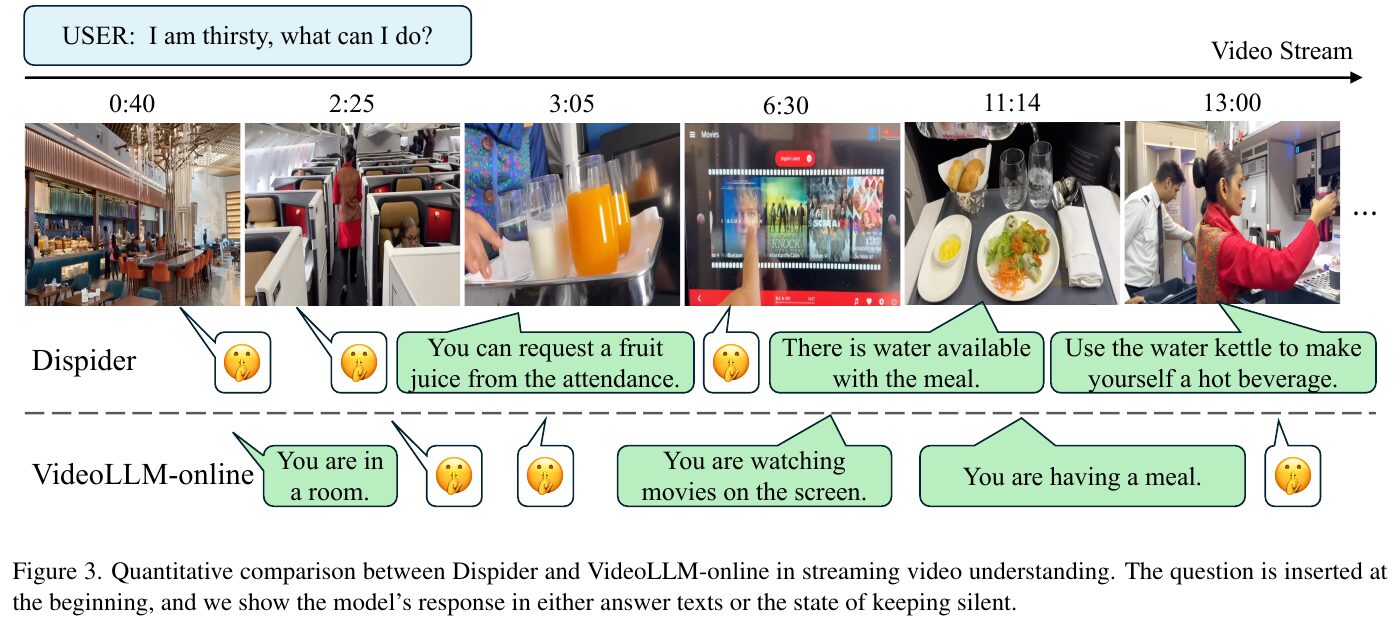
この図は、ストリーミングビデオ理解におけるDispiderとVideoLLM-onlineの比較を示しています。ユーザーが「喉が渇いた、どうしたらいい?」と尋ねた際の対応が描かれています。ビデオ時間ラインに沿って、各時点での画像が示され、DispiderとVideoLLM-onlineの応答が比較されています。 Dispiderは、具体的な状況に応じた回答を提示しており、たとえば、飲み物をリクエストする、食事と一緒に水が提供される、湯沸かしポットで温かい飲み物を作るなどの提案をしています。一方、VideoLLM-onlineは、主に状況の説明にとどまり、例えば「部屋にいる」「画面で映画を見ている」といった回答に留まっており、具体的な提案は少ないです。 この図から、Dispiderの方が文脈理解と反応の適切さにおいて優れていることが示されています。
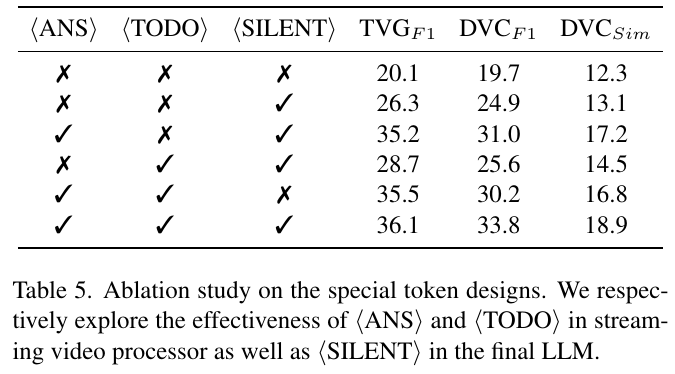
この画像は、特別なトークン設計に関するアブレーションスタディを示しています。表では、3つの特別なトークン「⟨ANS⟩」、「⟨TODO⟩」、「⟨SILENT⟩」を使用した場合の効果を検証しています。これらのトークンは、動画ストリーミングプロセッサや最終的な大規模言語モデル(LLM)での反応性や精度に影響を与えます。 各行は、異なる組み合わせのトークンの使用を示し、それによって得られるTVG_F1、DVC_F1、DVC_Simの評価指数が示されています。結果として、すべてのトークンを用いる組み合わせが最高のパフォーマンスを示しており、これによりトークンが有効に機能していることが確認されます。
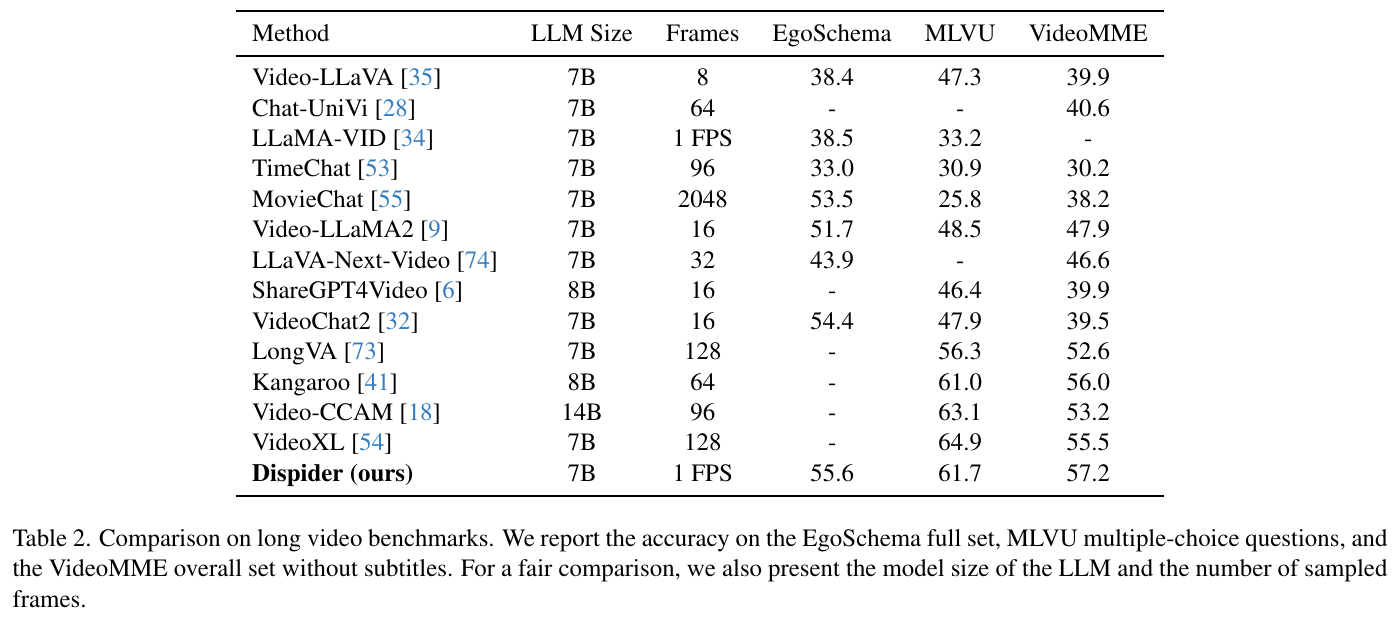
この表は、長時間のビデオに関するベンチマーク比較を示しています。さまざまな手法が、EgoSchema、MLVU、VideoMMEといった複数のビデオ理解タスクでの精度で評価されています。表には各手法の大規模言語モデル(LLM)のサイズやフレーム数も記載されています。Dispiderは、これらのベンチマークで特に高い精度を示しており、特に55.6(EgoSchema)、61.7(MLVU)、57.2(VideoMME)と優れたパフォーマンスを達成しています。これはDispiderのリアルタイムでの応答能力が他の手法よりも優れていることを証明しています。
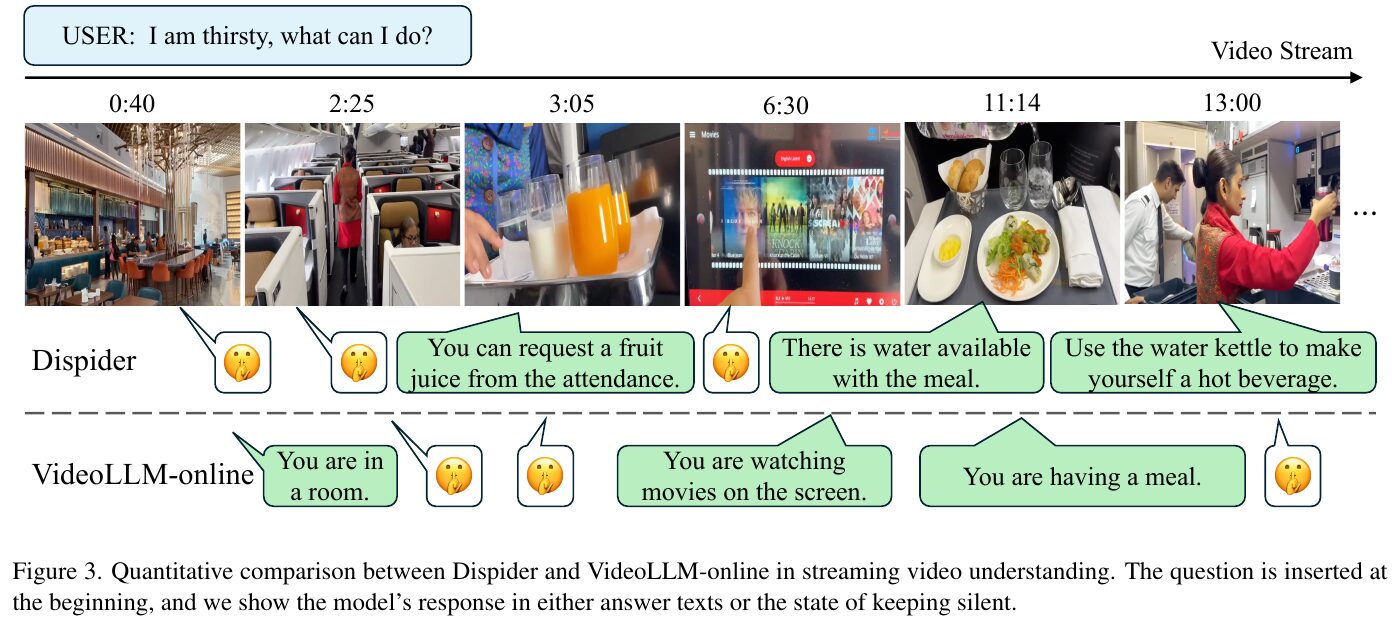
この画像は、DispiderとVideoLLM-onlineのストリーミングビデオ理解能力を比較しているものです。ユーザーは「のどが渇いたけど、どうしたらいい?」と質問し、ビデオが進行します。Dispiderはビデオストリームを分析して、その場に応じた有益な回答をします。例えば、飲み物が提供されている場面では「フルーツジュースをお願いできます」と回答しています。一方、VideoLLM-onlineはより単純なシーンの説明にとどまり、質問に対する対応が具体的ではありません。このように、Dispiderはリアルタイムでコンテキストを判断し、適切に反応することが可能です。
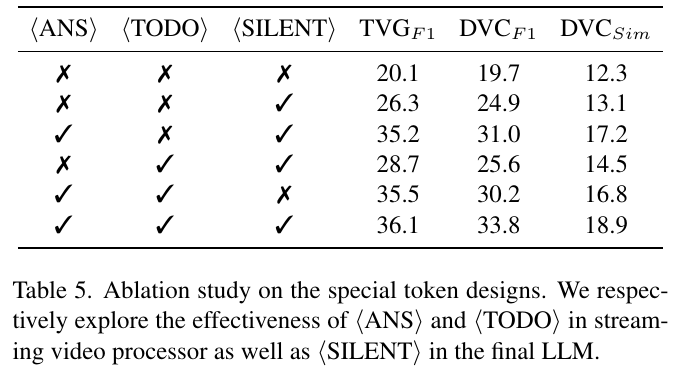
この表は、ディスピダーというシステムの特別なトークン設計の効果を示しています。具体的には、〈ANS〉、〈TODO〉、〈SILENT〉という3つのトークンがそれぞれ異なる役割を果たしています。 ディスピダーは、映像ストリーミングをリアルタイムで処理し、適切なタイミングで応答を生成するために、これらのトークンを使用します。表に示された結果では、〈ANS〉と〈TODO〉の両方を使用すると、TVG、DVC、Simの各評価で高いスコアが得られています。これは、これらのトークンが応答のタイミングを決定するのに重要であることを示しています。 〈SILENT〉トークンは、映像ストリームが処理中であっても、必要に応じて沈黙を保てるようにするためです。これにより、ディスピダーはリアルタイムでの応答生成と映像処理を効果的に分離できます。この仕組みにより、システムは常に最新のコンテキストに基づいた正確な応答を生成することができます。