- 映像超解像を改善するための新しいフレームワーク「STAR」を提案
- T2Vモデルを活用し、リアルなテクスチャと時間的一貫性を強化する技術
- 実験評価で他の手法を上回る性能と視覚的品質を実現した成果
論文:STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
本論文は、現実世界における映像の超解像(Video Super-Resolution, VSR)を改良する新しいフレームワーク「STAR(Spatial-Temporal Augmentation with Text-to-Video Models)」を提案しています。従来のVSR手法は、空間的解像度の向上に特化してきましたが、時間的な一貫性の確保や現実的な外観の生成において課題がありました。この問題に対処するため、本研究では、Text-to-Videoモデル(T2Vモデル)を用い、高い画質の映像生成と過去のフレームとの調和を両立するアプローチを開発しました。
STARは、T2Vモデルの生成能力を活用し、リアルなテクスチャや時間的一貫性を向上させる仕組みです。提案手法では、まず入力映像から空間的および局所的な特徴を抽出し、それを大規模言語モデル(LLM)から得られるグローバルな文脈情報と統合します。さらに、Dynamic Frequency Loss(DF Loss)と呼ばれる新しい損失関数を導入し、高周波のテクスチャと低周波の平滑性を適切にバランスさせることで、再構築精度と視覚的品質を両立しています。
実験では、合成データセット(RED、VideoLQなど)と実世界のデータセットを用いて比較評価を行いました。STARはPSNR(ピーク信号対雑音比)、SSIM(構造類似性指数)、および時間的一貫性において他手法を上回る高い性能を示しました。また、主観評価でも、生成物の視覚的品質とテクスチャのリアルさにおいて優位性が確認されています。
図表の解説
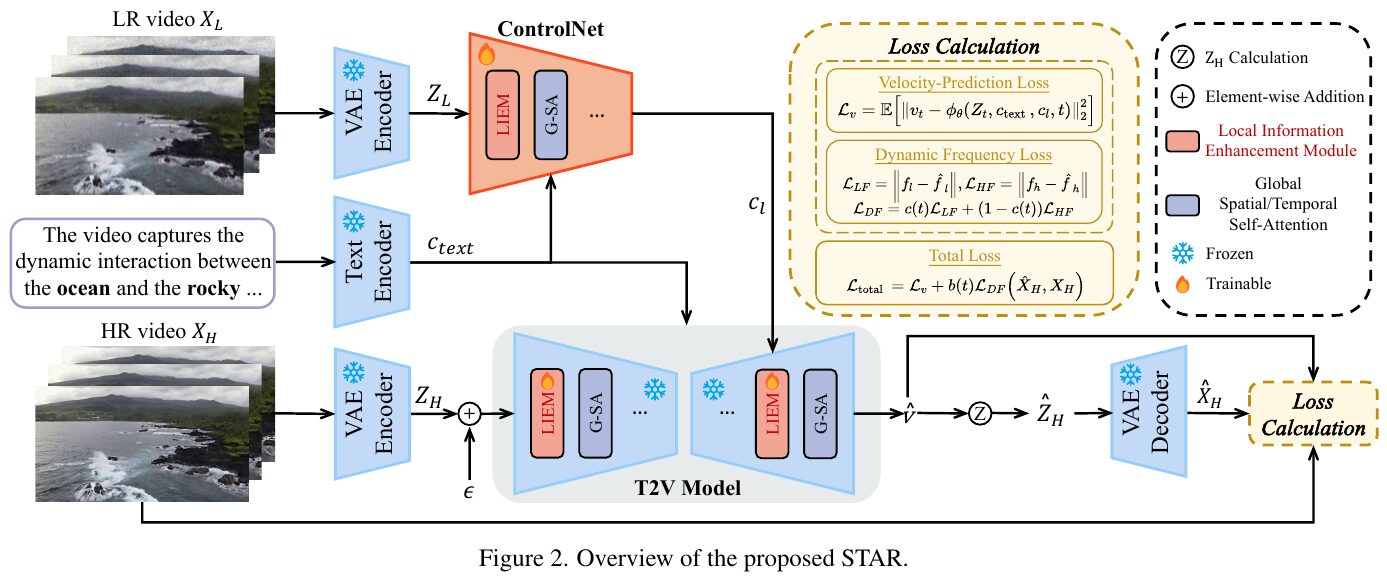
この図は、提案されたSTARモデルの概要を示しています。STARは、リアルな世界のビデオ超解像を実現するために、テキストからビデオへのモデルを用いた空間・時間的な増強を行う手法です。図では、低解像度(LR)と高解像度(HR)のビデオが入力され、VAEエンコーダーによって潜在テンソルが生成されます。これと、テキストエンコーダーによるテキスト埋め込みが、テキストからビデオ(T2V)モデルへの入力として利用されます。 特に、ローカル情報を強化するモジュール(LIEM)を導入し、グローバル注意機構に先立って局所的な詳細を強化し、劣化アーティファクトを軽減します。また、ダイナミック周波数(DF)損失を使用し、異なる拡散ステップで低・高周波情報に焦点を合わせ、忠実性を強化します。全体のロスは、速度予測と動的周波数損失で構成されています。
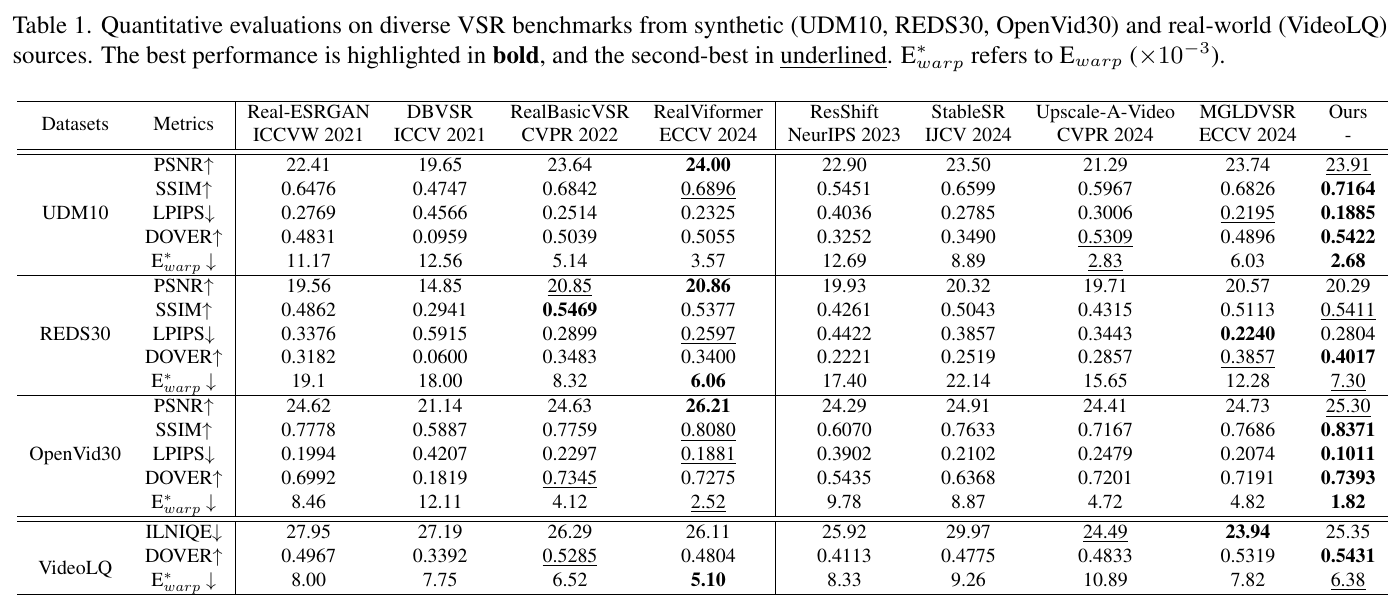
この表は、さまざまなビデオ超解像(VSR)モデルの評価結果を示しています。評価は合成データセット(UDM10、REDS30、OpenVid30)および実世界のデータセット(VideoLQ)に対して行われました。表には、PSNR(高いほど良い)、SSIM(高いほど良い)、LPIPS(低いほど良い)、DOVER(高いほど良い)、E_warp*(低いほど良い)の各指標が示されています。「Ours」と表記された列は、提案されたモデルSTARのパフォーマンスを表しており、ほとんどの指標で他のモデルを上回っています。特に、STARは高いPSNRとSSIMを達成し、LPIPSやE_warp*も低く抑えています。これは、STARが空間的な細部と時間的な一貫性の両方において優れた能力を持つことを示しています。
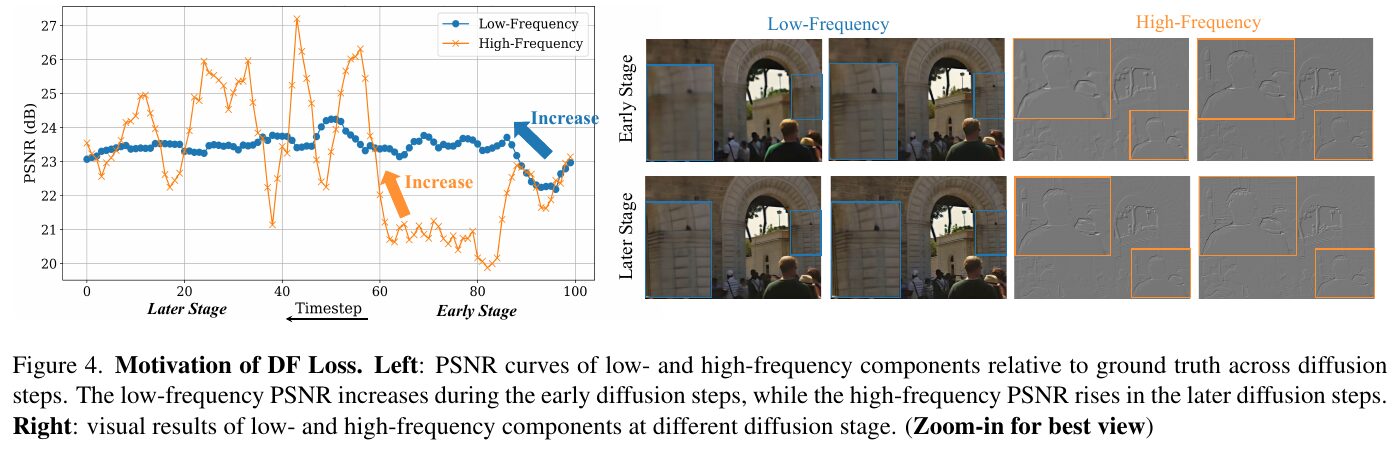
この図は、STARという手法がどのようにしてリアルなビデオ超解像を実現するかを示しています。左のグラフでは、PSNRという画像の鮮明さを示す指標が時間の経過を追って変化する様子を示しています。低周波成分は初期の段階で向上し、高周波成分は後半で向上します。右側の画像は、低周波と高周波成分が異なる拡散段階でどのように視覚的に表れるかを示しています。この図は、STARにおけるDF Loss(動的周波数ロス)の導入が、異なる周波数成分に対してうまく働くことを視覚的に説明しています。

この図は、提案されたLIEM(Local Information Enhancement Module)の効果を示しています。左側では、全体の構造だけを使うのと、局所的な情報を加えて使う場合の違いが示されています。右側では、実際の動画と合成動画での視覚的な比較がされています。上段は、LIEMを使用せずに世界とだけ情報を組み合わせた場合です。下段は、LIEMを使用し、局所的な詳細も考慮した場合です。LIEMを使用することで、細かい部分の復元がより鮮明になり、アーティファクトが軽減されていることが視覚的に確認できます。これは、より高品質な動画超解像を実現するためのポイントです。
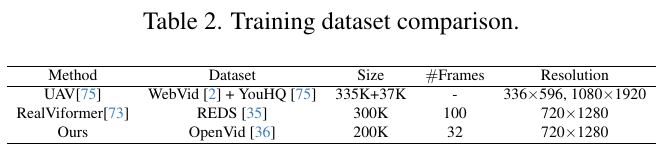
この図は、STAR(Spatial-Temporal Augmentation with Text-to-Video Models for Real-world Video Super-Resolution)という論文からのもので、トレーニングデータセットの比較を示しています。表には、3つの異なる方法(UAV、RealViformer、Ours)のデータセット、サイズ、フレーム数、解像度が記載されています。UAVはWebVidとYouHQのデータセットを使用し、サイズは約372Kです。RealViformerはREDSデータセットの300Kフレームを使い、OursはOpenVidデータセットの200Kフレームを利用しています。解像度を見ると、RealViformerとOursはどちらも720×1280の同じ解像度に統一されていますが、UAVは異なる解像度を持っています。これらの情報は、それぞれのデータセットの特性とトレーニングの違いを理解するのに役立ちます。
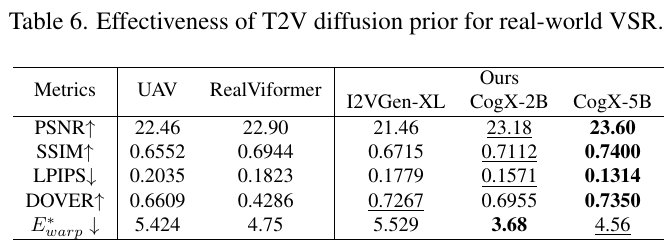
この表は、T2V(テキストからビデオ)拡散モデルを用いたビデオ超解像技術の効果を比較したものです。表に示されているのは、異なるモデルとその性能を評価するための指標で、各指標は映像の品質や一致度を示しています。 具体的には、PSNR(ピーク信号対雑音比)は数値が高いほど良く、画像品質の高さを示します。SSIM(構造類似度)も同様に値が高いほど画像の構造がよく保存されていることを示します。LPIPS(知覚画像パッチ類似度)は逆に、値が小さいほど良く、画像の見た目の違いが少ないことを示しています。DOVERは映像の鮮明さを示し、値が高いほど良いです。E*warpは動きのズレを示し、値が小さいほど時間的な一貫性が高いことを示しています。 この表から、CogX-5Bが他のモデルと比較してほとんどの指標で優れた性能を持っていることがわかります。これは、リアルな映像品質と時間的な一貫性を提供するための強力な拡散モデルが貢献していることを示唆しています。

この画像は、低解像度の動画を高解像度に変換する技術の効果を比較したものです。画像上部の例では、人の顔や手の細部とテキスト「Dr. Phil」の再現状況が示されています。下部の例は、地面の模様の精度を比較しています。各列は異なる技術の出力を示しており、「Ours」と表記された列は、本研究「STAR」の結果を示しています。結果として、STARは他の方法と比較して、より自然で詳細な再現を実現し、元の高解像度画像に近い結果を提供しています。このことから、STARがリアルな空間的ディテールと強固な時間的一貫性を達成していることがわかります。

この図は、論文「STAR: 空間-時間の強化による現実世界のビデオ超解像」において、REDS30とOpenVidデータセットでの時間的一貫性の質的比較を示しています。左側の画像は、ビデオフレームの時間差を示し、様々な手法が時間的一貫性をどのように処理しているかを視覚的に比較しています。右側の画像も同様に、異なる方法で処理されたビデオフレームの時間軸と空間軸での変化を示しています。 STARは、他の手法と比較して、より自然な空間的詳細と強固な時間的一貫性を実現しています。この図は、時間的一貫性を重視して詳細な比較が行われており、特にSTARの手法が複雑な動画シチュエーションで優れた結果を示すことを可視化しています。動画の品質評価をするために、さまざまな手法の比較が行われています。