- 複雑な視覚推論の能力を高めるためのMLLM「Virgo」を開発
- 2つのアプローチ、長い思考指示と知識蒸留を活用した手法の提案
- 実験での性能向上とデータの質が結果に与える影響の重要性を確認
論文:Virgo: A Preliminary Exploration on Reproducing o1-like MLLM
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
本研究では、「Virgo」というマルチモーダル大規模言語モデル(MLLM)の開発を通じて、視覚推論と呼ばれる複雑な推論能力の向上を試みています。視覚推論とは、画像やテキストなど異なる形式の情報を結びつけて深い理解を行う能力を指します。この研究では、特により長い推論のプロセスを効果的に学習させるデータと手法に着目し、その有効性を検証しています。
提案手法は2つのアプローチに基づいています。一つ目は既存のマルチモーダルデータに「長い思考指示」と呼ばれる詳細な説明付きの指示を追加し、それに基づいてMLLMをトレーニングする方法です。このアプローチは、モデルに長期的な推論能力を模倣させることを目的としています。二つ目は、すでに高い推論能力を持つモデルからの知識蒸留による手法です。具体的には、長い推論過程が記述されたデータを活用して、既存MLLMの性能を直接改善するアプローチを採用しました。
実験では、4つのベンチマーク(MathView、MathInstructions、OogwayBench、およびM3MMU)を使用し、それらにおける提案手法の有効性が検証されました。結果として、全体的に優れた性能向上が観察されましたが、長い推論が必ずしもすべての場合で有益とは限らないことも明らかになり、むしろデータの質や課題の性質が結果に大きく影響を及ぼすことが示されました。
また、ケーススタディでは、複雑な数式の計算や視覚問題の解釈において、Virgoが細かい思考を反映できている点が確認されました。しかし、一方で、自己反省の欠如が誤りの原因となったケースも観察され、さらなる改良の必要性が議論されています。
図表の解説
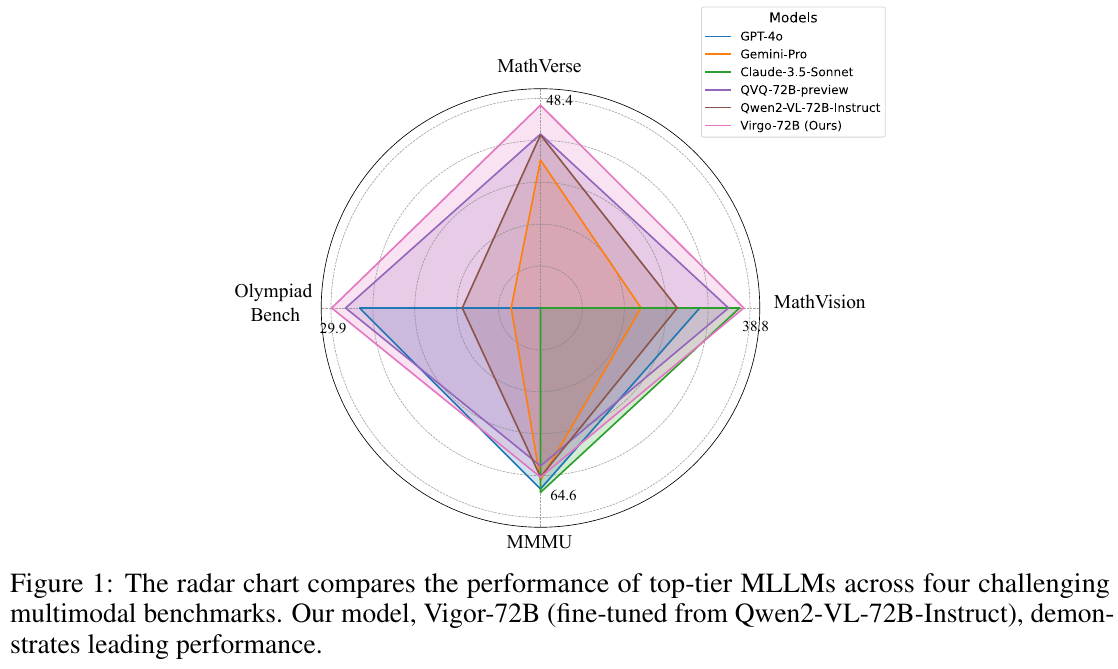
図1は、トップクラスのマルチモーダル大規模言語モデル(MLLM)が4つの難しいベンチマークでどの程度の性能を発揮するかを比較しています。このレーダーチャートでは、各モデルのパフォーマンスが視覚的に示されており、それぞれ異なる色の線で表現されています。具体的には、MathVerse、MathVision、Olympiad Bench、MMMUという4つのベンチマークが使用されており、各モデルがそれらでどれだけ良い結果を出したかが評価されています。チャートによれば、Virgo-72B(私たちのモデル)は、他のモデルよりも優れた性能を示しています。これは、特にマルチモーダルなデータを処理する能力を高めるために微調整された結果です。
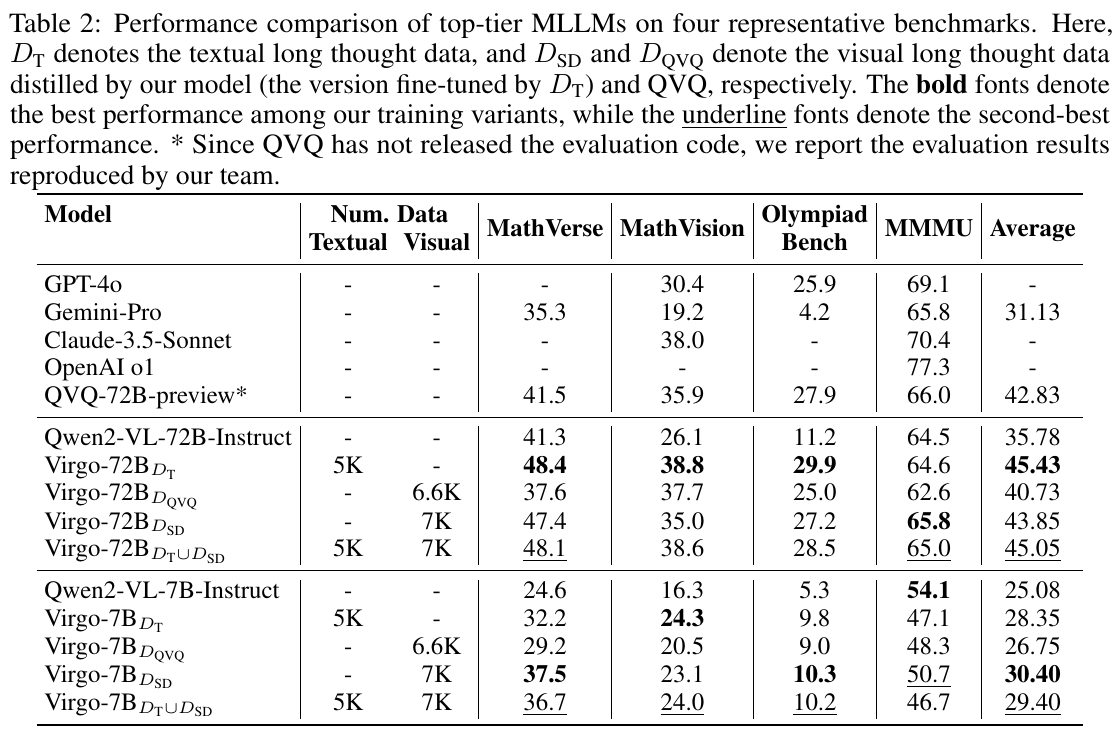
この表は、トップレベルの多モーダル大規模言語モデル(MLLM)のパフォーマンスを示しています。モデルは、数学に関連する4つのベンチマークでテストされています。それぞれのデータの列には、モデルの学習に使用したテキストデータと視覚データの量が示されています。たとえば、Virgo-72Bは、テキストデータや視覚データを異なる組み合わせでトレーニングされています。その結果、MathVerseとMathVisionベンチマークで最も高いスコアを示していますが、Olympiad Benchでは他のモデルが優れている点があります。太字は最高のパフォーマンス、下線は二番目に良い結果を示しています。これは、さまざまなデータを使用したトレーニングがモデル性能にどう影響するかを理解するために役立っています。
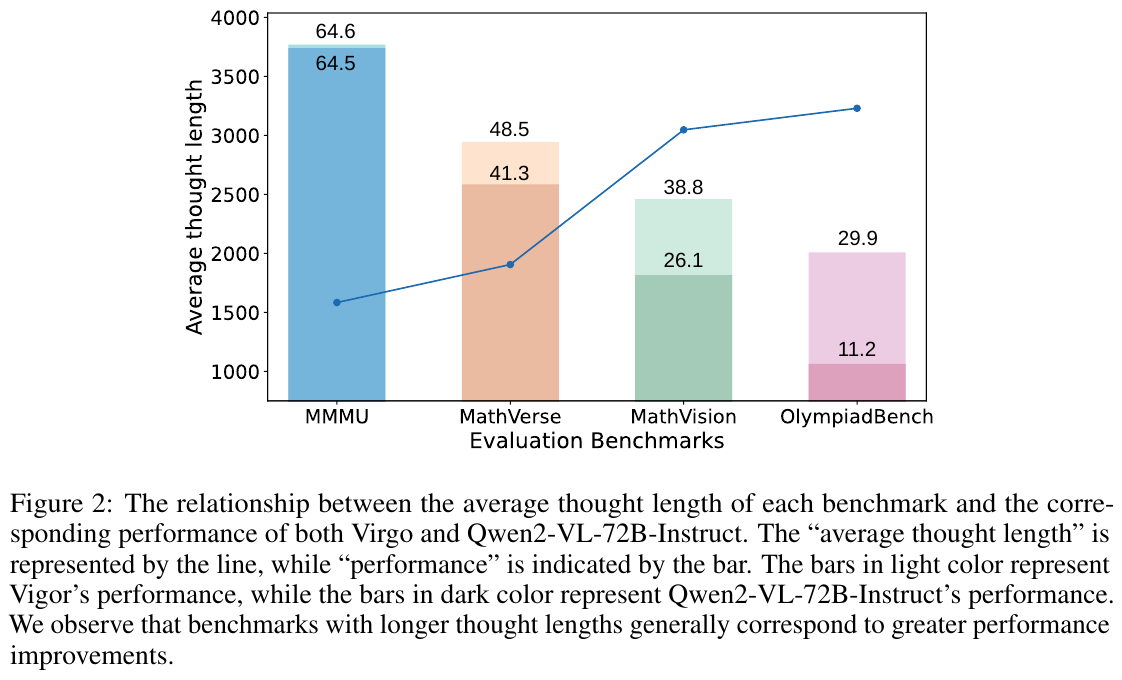
この図は、各ベンチマークにおける平均思考の長さと、それに対するVirgoとQwen2-VL-72B-Instructのパフォーマンスを示しています。グラフの線は「平均思考の長さ」を表し、バーは「パフォーマンス」を示しています。淡い色のバーはVirgoの性能を、濃い色のバーはQwen2-VL-72B-Instructの性能を表します。図からわかるように、思考の長さが長いベンチマークほど、パフォーマンスの向上が見られる傾向があります。これは、複雑な問題を考える時間と丁寧さが関係していることを示唆しています。
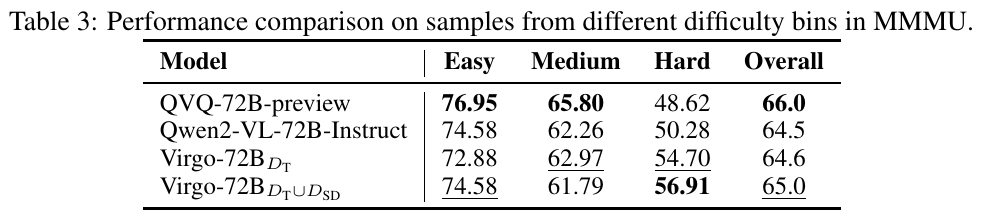
この表は、MMMUというベンチマークにおける異なる難易度のサンプルに対するモデルの性能比較を示しています。表には、4つのモデルが含まれており、それぞれ「Easy(簡単)」「Medium(中程度)」「Hard(難しい)」、および全体のスコアが記載されています。 モデル「QVQ-72B-preview」は全体で66.0のスコアを持ち、これは他のモデルと比べて良好なパフォーマンスです。難しいサンプルでは他のモデルが互角かそれ以上の性能を発揮しており、特に「Virgo-72B_{DT∪DSD}」が56.91で最高の「Hard」スコアを示しています。このデータは、モデルが異なる難易度にどう対処するかの比較に役立ちます。 このような評価は、マルチモーダル大規模言語モデル(MLLM)が複雑なタスクにどう対応できるか、特に「遅い思考」プロセスを通じて性能を向上させられるかを分析するためのものです。
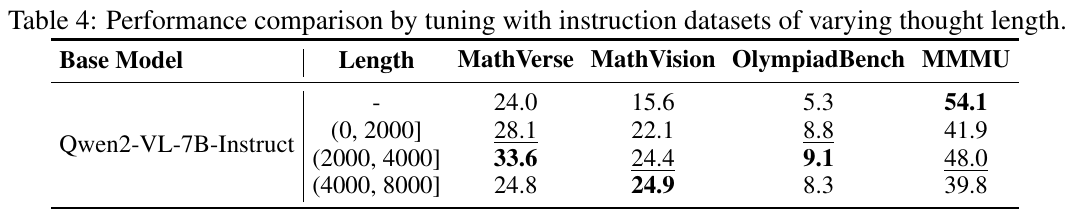
表4は、Qwen2-VL-7B-Instructモデルが指示データセットの「思考の長さ」によりどのように性能が変わるかを示しています。このモデルは、MathVerse、MathVision、OlympiadBench、MMMUの4つのベンチマークで評価されています。 まず、基準となるモデル(未調整)は、MathVerseで24.0、MathVisionで15.6、OlympiadBenchで5.3、MMMUで54.1というスコアを持っています。次に、指示データの長さを(0, 2000]に調整すると、各ベンチマークで性能が向上し、特にMathVerseで28.1、MathVisionで22.1と改善されています。(2000, 4000]の長さではさらに性能が向上し、MathVerseで33.6、MathVisionで24.4のスコアを記録しました。しかし、(4000, 8000]の長さでは、若干の性能低下が見られ、全体的に最適な結果は(2000, 4000]の範囲で得られています。
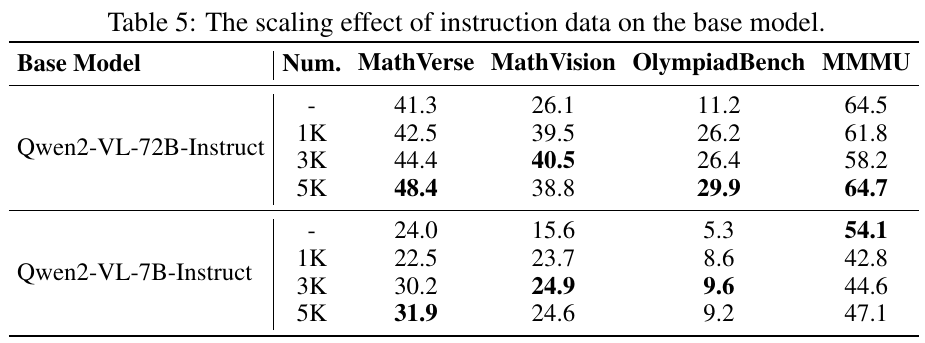
表5は、ベースモデルに対する指示データのスケーリング効果を示しています。2つの異なるモデル、「Qwen2-VL-72B-Instruct」と「Qwen2-VL-7B-Instruct」の性能が、提供された指示データの量に応じてどのように変化するかを測定しています。 具体的に言うと、「Qwen2-VL-72B-Instruct」は指示データが増加するにつれて「MathVerse」や「OlympiadBench」での性能が向上していますが、「MMMU」では大きな変化が見られません。一方、「Qwen2-VL-7B-Instruct」は全体的に性能が向上しているが、「MathVision」や「OlympiadBench」での改善はさほど顕著ではありません。 これにより、指示データの量がモデルの性能に与える影響がモデルによって異なることがわかります。

この表は、Qwen2-VL-72B-Instructモデルが異なる難易度レベルで自己蒸留した視覚指示を使用した場合のパフォーマンス比較を示しています。「難易度」欄には、-、Medium、Hard、Randomというカテゴリーがあり、それぞれが異なるデータセットの難易度を表しています。 表の結果から、難易度MediumとHardの指示がMathVisionやOlympiadBenchで特に高いスコアを達成していることがわかります。特に、MathVisionでは、Hardの指示が39.1という最高のスコアを記録しています。MMMUでは、Mediumの指示が65.0と最も高いパフォーマンスを示しています。 全体として、視覚データの難易度は特定のパフォーマンスに限定的な影響しか与えないことが示唆されており、複雑な問題に対応できる高品質な視覚指示の開発が今後の課題とされています。

この画像は、数式を用いて描かれた関数の積分を評価する過程を示しています。具体的には、半円の面積を計算しており、3つの半円のそれぞれの面積を足し合わせて最終的な面積を求める手順が説明されています。 まず、最も小さい半円の面積を求め、次に中くらいの半円、そして最も大きい半円の順に計算します。各関数の積分は、半円の面積で表される自然な解を導く様子が示されています。さらに、各半円の表現が数式として簡単に示されています。最終的な答えは、全ての半円の面積を足し合わせた7πであると結論づけています。