- VITA-1.5モデルは音声と視覚情報を統合し、人と機械の自然なコミュニケーションを強化する技術
- 視覚と言語の結びつきを学習した後に音声情報を統合する段階的な訓練手法を採用
- リアルタイム性を考慮した設計により動的な処理と瞬時の出力生成が可能な機能
論文:VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
VITA-1.5は、音声と視覚のマルチモーダルなリアルタイムインタラクションを目指したモデルとして提案されました。この研究では、音声認識(ASR)や音声合成(TTS)などの音声関連タスクと、視覚的入力を統合的に処理することで、人間と機械の自然なコミュニケーションを強化することを目的としています。
このモデルの設計では、既存の大規模言語モデル(LLM)の強みを活かしつつ、新たに音声と視覚情報の統合を実現するための工夫が導入されています。VITA-1.5では、視覚言語データと音声データをステージ別に学習させる段階的な訓練手法を採用しています。最初の段階では視覚と言語の結びつきを学習し、その後の段階で音声データを統合することで、LLMにマルチモーダルな処理能力を付加します。また、音声データの処理にはウェーブトゥテキスト技術が活用され、音声信号を離散トークンに変換し、LLMに直接組み込む形式を取っています。
評価実験においては、視覚-言語理解、動画理解、音声認識などの代表的なベンチマークで高いパフォーマンスを示しました。特に、音声認識タスクでは英語および中国語のデータセットで他のオープンソースモデルと比較して優位性が確認されています。一方、動画理解タスクではまだ課題が残るものの、一定水準以上の性能を維持しています。
図表の解説

この画像は、VITA-1.5がリアルタイムで視覚と音声のインタラクションを可能にする様子を示しています。画像の中では、スマートフォンが映っており、「VITA-1.5 デモ」と記された画面が表示されています。このデモは、カメラをオンにしてスムーズな音声対話を実現する様子を説明しています。VITA-1.5は、視覚と言語の統合を強化し、端から端までのフレームワークを通じてリアルタイムに近いインタラクションを提供します。このシステムは、ユーザーの利便性を向上させるために、音声認識とテキスト生成を効率的に行うことができ、画像や音声のタスクにおいて優れた性能を発揮します。

画像は、VITA-1.5の全体的なアーキテクチャを示しています。このモデルは、視覚情報と音声情報を扱えるように設計されています。入力側には、視覚と音声のエンコーダーがあり、それぞれにアダプターが付いていて、これらが大規模言語モデル(LLM)と連携しています。出力側では、VITA-1.5には独自の音声生成モジュールがあり、以前のバージョンVITA-1.0のように外部の音声合成(TTS)モデルを使用することなく、音声を生成できます。この設計により、リアルタイムでの視覚と言語の統合的な理解と、スムーズな音声対話が可能になります。
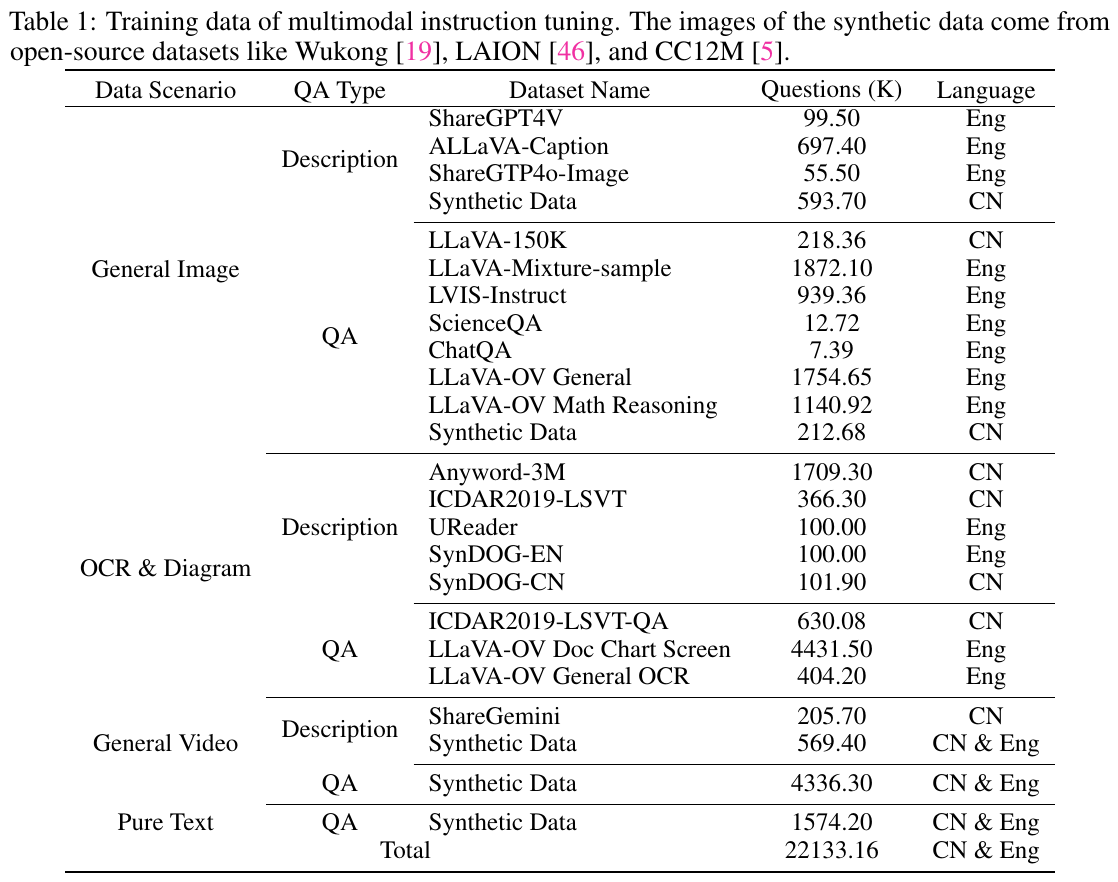
この画像は、論文で使用されたマルチモーダル指示調整のためのトレーニングデータを示しています。データは「一般画像」「OCRと図」「一般動画」「純粋テキスト」などのシナリオに分けられ、それぞれに「説明」と「QA(質問応答)」のタイプがあります。各データセットの名前、質問数(K、千単位)、言語が示されており、英語と中国語のデータセットが含まれています。合計で約22,133.16Kの質問が用意され、画像データの一部はWukongやLAIONなどのオープンソースから取得されています。この表は、VITA-1.5のマルチモーダルな学習プロセスにおけるデータの多様性とボリュームを示しています。
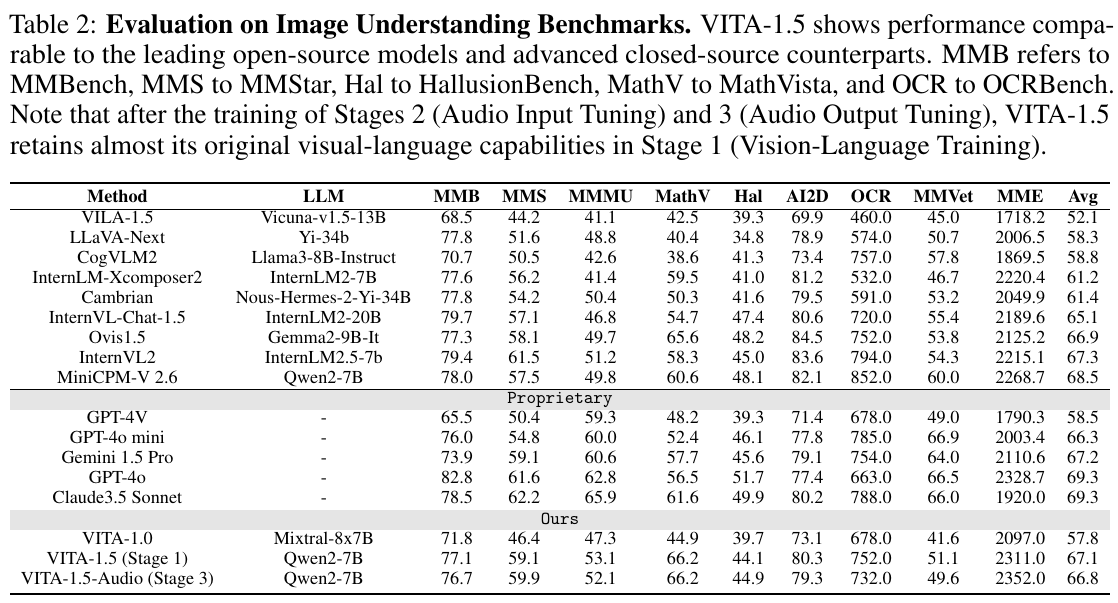
この表は、画像認識ベンチマークでのVITA-1.5の性能を示しています。VITA-1.5は、最新のオープンソースモデルや高度なクローズドソースモデルと比較して、優れたパフォーマンスを発揮しています。各列は異なる評価基準を表しており、「MMB」から「MMVet」までのそれぞれの指標でのモデルのスコアが載っています。表内では、VITA-1.5がビジュアルと言語の訓練段階後も、視覚と言語の能力をほぼ維持していることが示されています。全体的な平均スコアの欄では、VITA-1.5の平均点が示され、多くのモデルと互角か、それ以上の成果を上げていることがわかります。
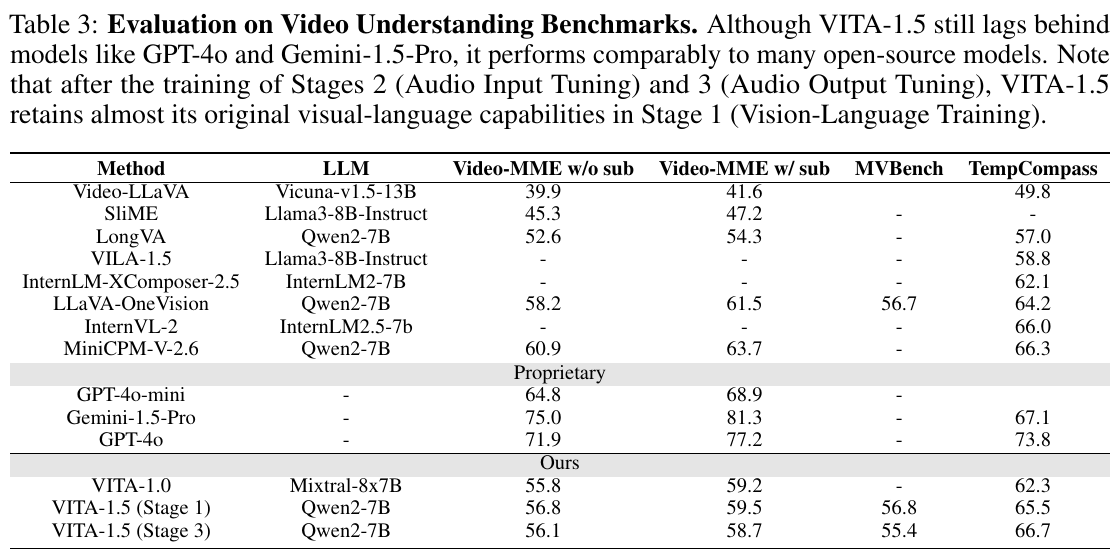
この表は、ビデオ理解ベンチマークにおけるモデルの性能を評価しています。主な焦点は、VITA-1.5がオープンソースモデルと比較してどの程度の性能を持つかです。表では「Video-MME」「MVBench」「TempCompass」などの指標で評価されており、VITA-1.5は「Video-MME」で55.8点から59.5点を獲得していることが示されています。これは、オープンソースモデルとほぼ同程度の性能ですが、プロプライエタリモデル(GPT-4oやGemini 1.5 Pro)にはまだ及ばないことが分かります。また、ステージ2とステージ3のトレーニング後でも、ビジュアル・ランゲージの能力をほぼ維持していることが強調されています。
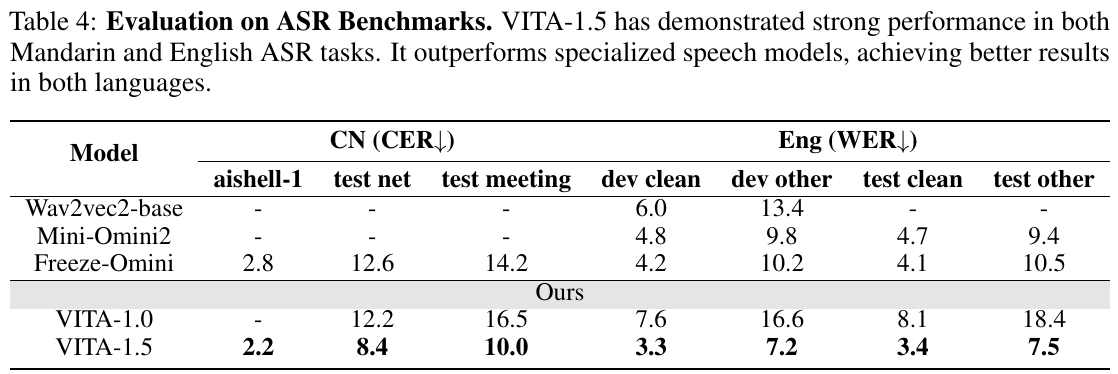
この表は、音声認識(ASR)のベンチマークにおけるVITA-1.5の評価結果を示しています。中国語(CN: CER)と英語(Eng: WER)の両方で性能が測られています。表には、競合するモデルと比較したキャラクターエラー率(CER)と単語エラー率(WER)が示されています。VITA-1.5は、特に標準的な音声モデルと比べて優れた結果を示しています。中国語のデータセット「aishell-1」や「test net」などでは、CERが他のモデルよりも低く、英語のデータセットでもWERが低くなっています。この結果から、VITA-1.5は多言語対応の音声認識において強い能力を持っていることがわかります。
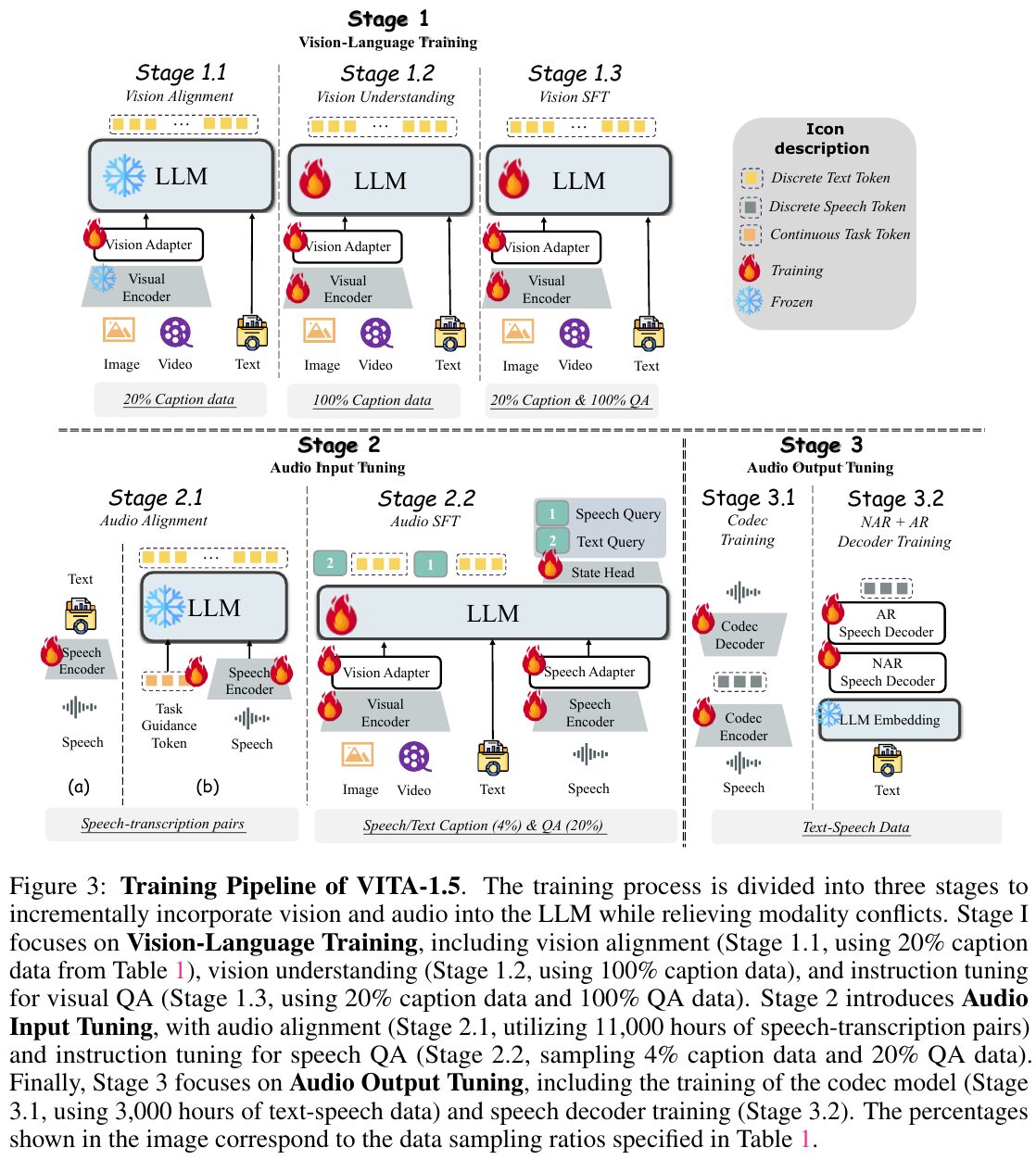
画像は、VITA-1.5のトレーニングパイプラインを示しています。トレーニングは3つの段階に分かれており、視覚と音声を段階的に大規模言語モデル(LLM)に統合する方法を解説しています。 最初の段階は「視覚-言語のトレーニング」で、視覚アライメント、視覚理解、視覚指示チューニングを行います。次に、「音声入力のチューニング」で音声のアライメントと音声QAの指示チューニングを実施。最後に「音声出力のチューニング」では、コーデックとデコーダーのトレーニングを行います。 各段階で異なるデータセットを使用し、視覚と音声のモダリティの整合性を確保しつつ、多様なタスクの能力を向上させることを目指しています。
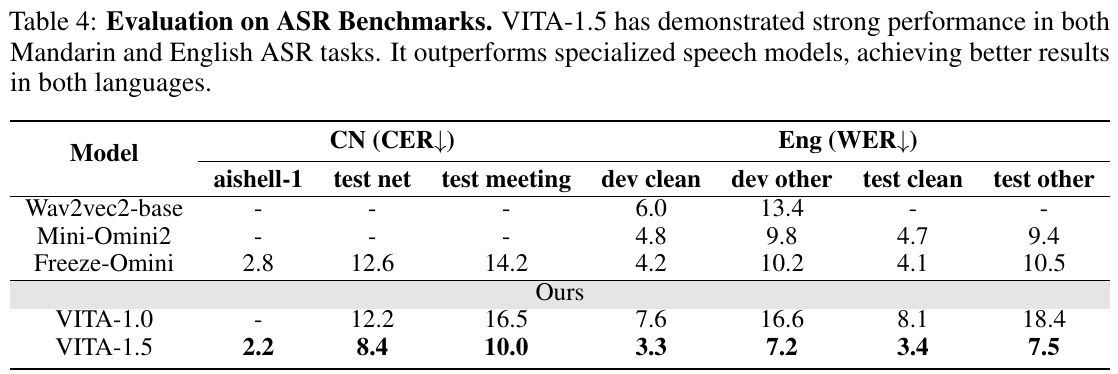
この図は、ASR(自動音声認識)のベンチマークテストにおけるモデルの性能を示しています。表には「CN(CER)」と「Eng(WER)」の2つの言語での結果が表示されています。CERは文字誤り率、WERは単語誤り率を表します。 「VITA-1.5」は、Mandarin(中国語)と英語の両方で高い性能を示しており、特化型スピーチモデルを上回る結果を達成しています。特に、VITA-1.5は他のモデルと比較して低い誤り率を記録しています。例えば、Mandarinのaishell-1でのCERは2.2であり、英語のdev cleanでのWERは3.3と、かなりの低値を示しています。この結果は、VITA-1.5の音声認識能力の高さを証明しています。