- 画像生成モデルで個性を保ちながら品質を向上させる手法「Nested Attention」を提案
- 特定部分の特徴を強調しつつ全体の一貫性を維持するために改良されたアテンションマップを使用
- ユーザー調査を含む実験で高い認識精度と主題の一貫性を示し、既存手法よりも好ましい結果を確認
論文:Nested Attention: Semantic-aware Attention Values for Concept Personalization
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この研究は、画像生成モデルにおける「個性化」を実現しつつ、元の特徴や品質を保つ新たな手法「Nested Attention」を提案しています。個性化とは、生成される画像にユニークな主題や特徴を取り入れることで、主に事前学習済みの画像生成モデル(特に拡散モデル)での応用が考えられています。既存のアプローチでは、個性化を優先すると元の画像の全体的な品質が損なわれるケースが多く、また既存の注意機構を用いるため、表現力に制約があるという課題が存在していました。
提案された方法「Nested Attention」は、既存の拡散モデルにおけるクロスアテンション機構を改良したものです。具体的には、対象となる画像や特定部分の特徴を、モデルの生成プロセス中にスムーズに注入する仕組みを採用しています。この仕組みでは、アテンションマップを改良し、より高い精度で特定部分を強調しつつ、画像全体の一貫性を維持することを可能にします。その結果、色や形状、テクスチャといった主題の細部が忠実に再現されながら、画像全体のクオリティも保たれます。
実験では、人間の顔やペットといった異なる種類の対象を用いて、この手法の有効性を検証しています。新手法は、既存の手法よりも高い認識精度と主題の一貫性を示し、多様なスタイルやポーズにおいても優れた性能を発揮しました。また、ユーザー調査では、他の主流手法に比べてこのアプローチがより好ましいとする結果も得られました。
図表の解説

この画像は、「Nested Attention」メカニズムを示しています。この手法は、特定の被写体を一つのテキスト・トークンに結びつけることで、特定の被写体のアイデンティティを保持しつつ多様なシーンやスタイルで画像を生成することを可能にしています。犬と人間を例に、異なるスタイルやシーン(雪の中、水彩画、ビーチなど)において、被写体のアイデンティティをどう表現するかが示されています。この方法により、モデルの基を維持しながら、高度なアイデンティティの保持と入力されたテキストプロンプトとの整合性を両立することが可能になります。
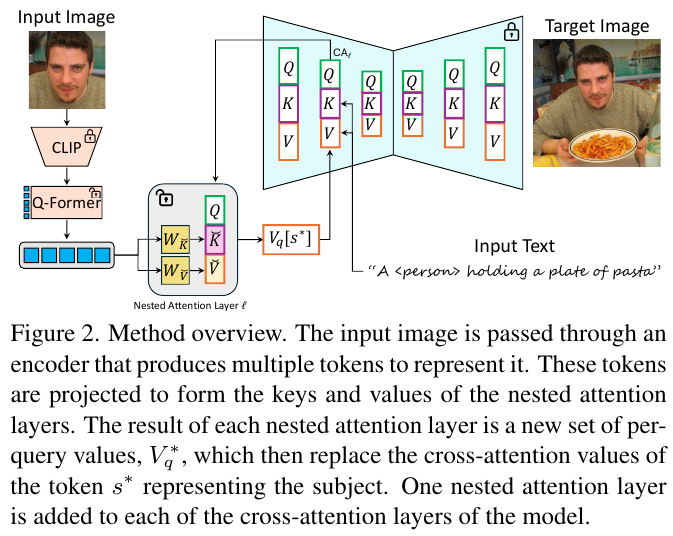
この画像は、テキストを活用して特定の被写体を新しいシーンで個別化して生成する技術の概要を示しています。入力画像はCLSIPとQ-Formerを通じてトークンに変換され、ネストされたアテンションレイヤーによって処理されます。このメカニズムにより、被写体は新しい画像で忠実に再現されます。ネストされたアテンションレイヤーは、被写体を表すトークンのクロスアテンション値を置き換えることで高精度な特定の特徴を再現します。結果として、テキストプロンプトに沿った多様で一貫性のある画像生成が可能になります。この方法は、モデルの既存のアテンションレイヤーに豊富な情報を統合しながら、被写体のアイデンティティを保持することを目的としています。
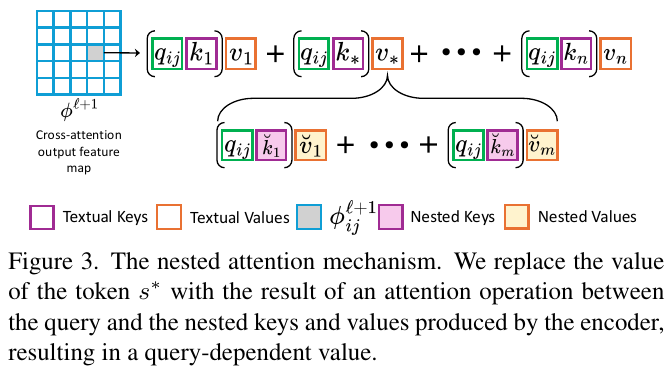
画像は、論文で説明されている「ネストされた注意メカニズム」を示しています。この手法では、トークン\(s^*\)の値を、クエリとエンコーダーによって生成されたネストされたキーと値を用いた注意操作の結果で置き換えます。これにより、クエリに依存した値が得られます。具体的には、テキストトークンをエンコーダーによって生成されたリッチで表現力豊かな画像表現に結び付け、生成された画像の各領域において、関連する主題の特徴を選択することが可能になります。このアプローチにより、高いアイデンティティの保持とテキストプロンプトへの忠実さを両立させることができます。

この画像は、論文で提示された「入れ子型アテンション」メカニズムの効果を示しています。図4では、同じ入力画像に対して生成された画像が異なる2つのアテンション層(通常のクロスアテンションと入れ子型アテンション)でどのように表現されるかを比較しています。通常のクロスアテンションでは、全体の画像で同じ値を使用して被写体を表現します。一方、入れ子型アテンションは、クエリごとに異なる被写体値を割り当て、細かい意味情報をエンコードします。これは、生成された画像で各領域に対して異なる特徴を選択することを学習し、より具体的で豊かな表現を可能にします。
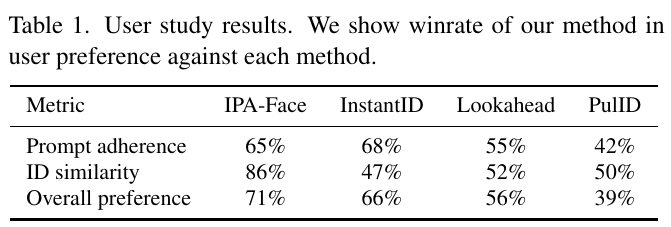
この表は、ユーザースタディの結果を示しています。研究では、ある方法のユーザーによる好みの勝率を、他の各方法と比較しています。具体的には、表で4つの異なる方法について3つの指標が示されています。 “Prompt adherence”(プロンプト順守)では、InstantIDが68%と最も高く、次いでIPA-Faceが65%です。”ID similarity”(ID類似度)では、IPA-Faceが86%で最も高いスコアを示しています。”Overall preference”(全体的な好み)では、IPA-Faceが71%で優位に立っています。 これらの結果から、IPA-FaceはID類似度で特に優れており、全体的な好みでも高いと見られますが、プロンプト順守では他の方法に劣る場合もあります。この研究は、Nested Attentionと呼ばれる新しいメカニズムによるアプローチの有効性を示すことを目的としています。
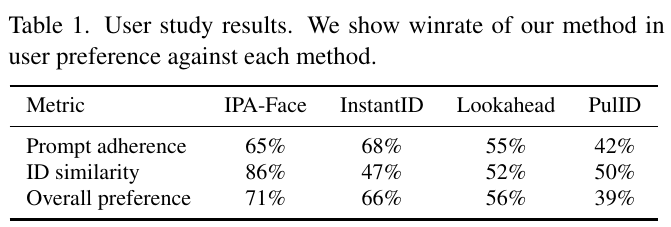
この表は、ユーザー研究の結果を示しており、「IPA-Face」、「InstantID」、「Lookahead」、「PullID」という4つの方法に対するユーザーの好みに基づいて、特定のメトリックでの勝率が比較されています。メトリックは「プロンプトの遵守」、「IDの類似性」、「全体的な好み」の3つです。 IPA-Faceは、IDの類似性で高い評価を受け、86%の勝率を示しています。一方、InstantIDはプロンプトの遵守で68%と優れた勝率を記録していますが、IDの類似性は47%と比較的低いです。Lookaheadは全体的にやや低いスコアですが、プロンプトの遵守では55%を示しています。PullIDは全体的に最も低く、特に全体的な好みで39%という結果でした。 総括すると、各方法の強みと弱みが異なることが示されており、IPA-FaceはIDの類似性で特に優れていることがわかります。
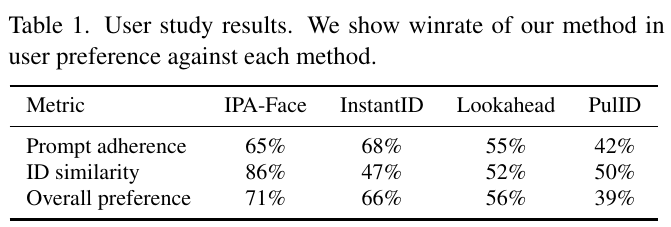
表1は、ユーザースタディの結果を示しています。この研究では、「IPA-Face」や「InstantID」などの異なる方法と比較して、提案手法のユーザープリファレンスの勝率が記録されています。 メトリクスは3つに分かれており、「プロンプト適合度」「ID類似度」「全体的な好み」です。プロンプト適合度では、InstantIDが68%で最も高いですが、全体的にはIPA-Faceが71%で最も好まれています。ID類似度においても、IPA-Faceが86%と他の方法を大きく上回っています。 この結果から、提案されたNested Attentionの手法は、多様なスタイルやシーンでのアイデンティティの保存とテキストのプロンプトとの整合性のバランスを取りつつ優れたパフォーマンスを発揮することが分かります。
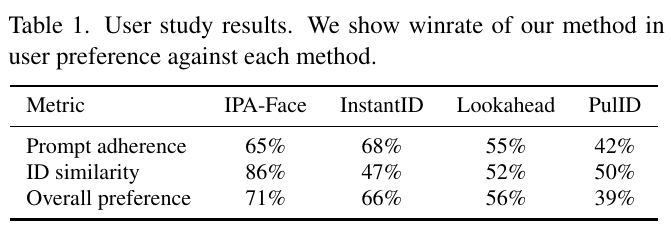
この表は、研究で提案されたNested Attentionメカニズムの他の個別化手法との比較結果を示しています。表の各行は異なる評価基準を表し、各列は異なる手法を表しています。 – 「Prompt adherence」は、入力されたテキスト指示にどれだけ忠実に画像が生成されるかを示します。IPA-Faceは65%、InstantIDは68%など、他の方法と比較されています。 – 「ID similarity」は、生成された画像が元の画像のアイデンティティをどれだけ維持しているかを示す指標です。この点では、IPA-Faceが86%と高い値を示しています。 – 「Overall preference」は、総合的な好みを示し、ユーザーがどの方法をより好んだかを示します。この欄でもIPA-Faceが71%で最も高い支持を受けました。 この結果は、提案された手法が他の方法に対してどのように優れているか、あるいは改善の余地があるかを示すものです。