- 競技プログラミング用の新しいベンチマーク「CodeELO」の提案
- Eloレーティングを用いたモデルと人間のパフォーマンスの比較
- 言語理解能力や推論能力の詳細な評価が可能な点
論文:CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
本論文では、競技プログラミングにおけるコード生成の能力を評価する新しいベンチマーク「CodeELO」を提案しています。これは、既存の言語モデル(LLM)が高い推理能力を必要とする問題にどこまで対応できるのかを測定するためのツールです。「CodeELO」の最大の特徴は、競技的な場面において人間と比較可能なEloレーティングを用いる点で、モデルの性能を公平に評価することを目指しています。
ベンチマークは、Codeforcesと呼ばれる実際の競技プログラミングプラットフォームから問題を抽出し、それらを細かく分類し標準化しています。問題には詳細なテストケースが用意され、モデルはコードを生成し、それを直接Codeforces上で評価することで正確なスコアリングが可能です。また、Eloレーティングの導入により、モデルのパフォーマンスがどの程度の熟練した人間参加者に匹敵するのかを直感的に理解することができます。
実験では、複数のオープンソースとプロプライエタリなモデルを評価しました。その結果、高度な問題ではモデルは依然として困難を抱えており、多くの場合成功率は低いものの、比較的簡単な問題では一定以上の性能を示しました。さらに、C++とPythonという異なるコーディング言語における性能差を調査したところ、特にC++でのアウトプットが精度を向上させる可能性が示唆されました。この点は競技プログラミングにおける実用性を高める重要な知見です。
本ベンチマークの利点として、従来のコード生成ベンチマークでは見えづらかったモデルの言語理解能力や推論能力を詳しく測ることができる点があります。一方、制限としては、各問題につき1回の提出しか許可しない設計と、現在利用できる問題の範囲に制約があることが挙げられます。
図表の解説
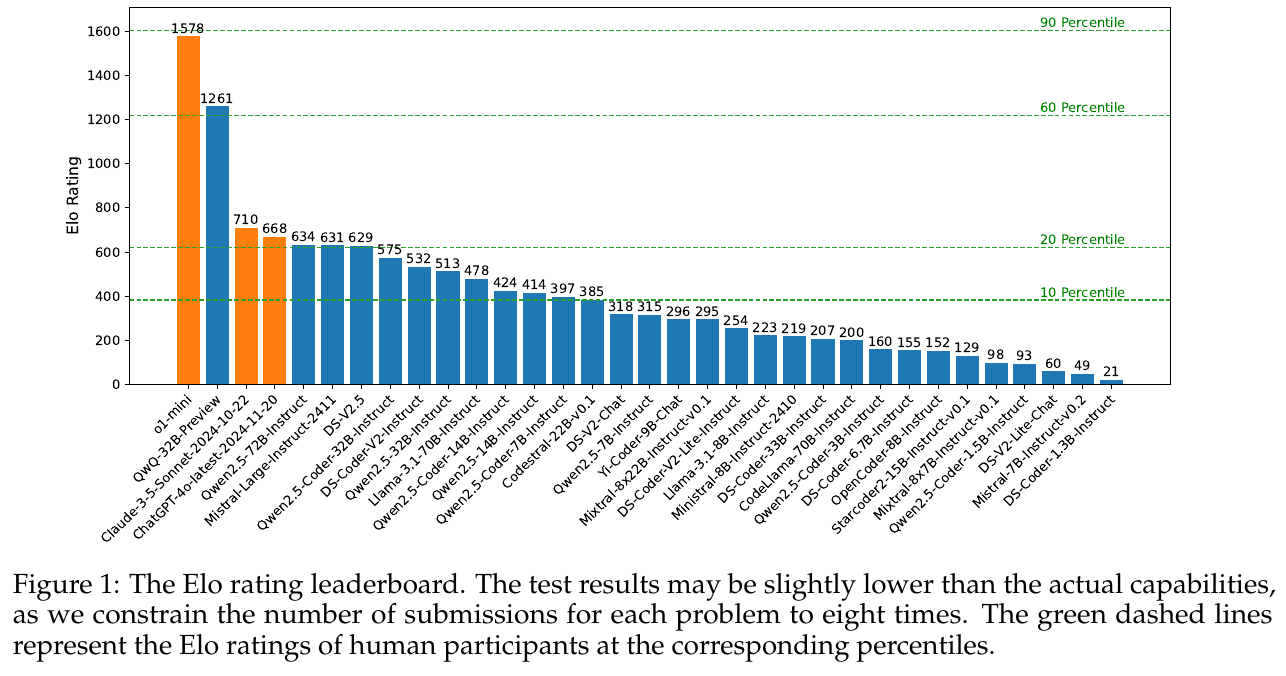
この図は、CODEELOというベンチマークに基づくモデルのEloレーティングランキングを示しています。Eloレーティングは、競技プログラミングの能力を評価するための指標で、人間の参加者とモデルを比較する際に用いられます。オレンジのバーはトップ2のモデルで、他の青いバーは残りのモデルを示します。緑色の点線は、10パーセンタイルから90パーセンタイルまでの人間参加者のEloレーティングを示しており、これらの線とモデルのレーティングを比較することで、モデルの性能を人間と相対的に評価できます。上位モデルは1578や1261などの高レーティングを持ち、他の多くのモデルは比較的低い位置にあります。
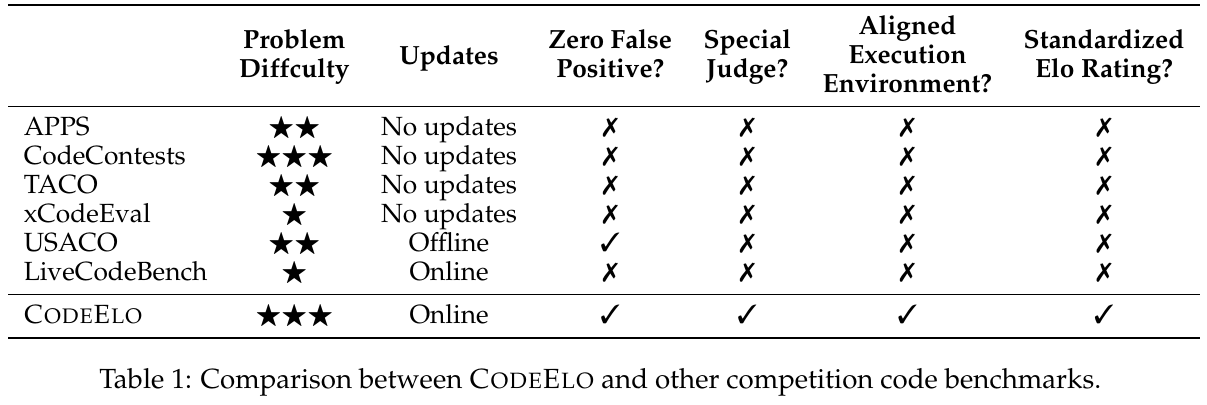
画像の表は、CODEELOというベンチマークと他の競技プログラム用ベンチマークを比較したものです。表では、問題の難易度から更新頻度、誤判定の有無、特別なジャッジのサポート、実行環境の整合性、標準化されたEloレーティングの有無を評価しています。CODEELOはオンラインで更新され、ゼロ誤判定と特別なジャッジをサポートし、整合性のある実行環境と標準化されたEloレーティングを提供します。これは、CODEELOが他のベンチマークに比べて、より競技レベルのコード生成能力を効果的に評価できることを示しています。
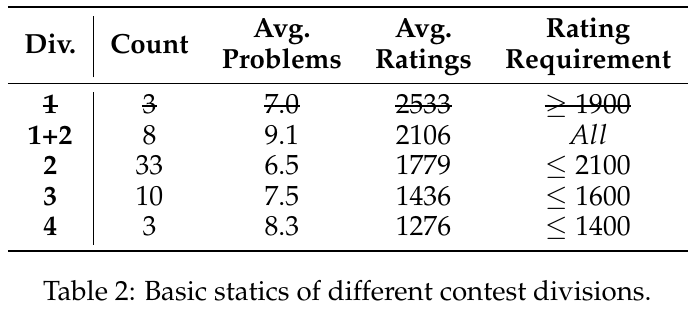
この表は、さまざまなコンテストのカテゴリーに関する基本的な統計を示しています。ここでは、「Div.」はコンテストのディビジョンを示し、それに応じた「Count」は過去6ヶ月間に開催されたコンテストの数を表します。「Avg. Problems」は各コンテストの平均問題数を示し、「Avg. Ratings」は参加者の平均レーティングを示します。また、「Rating Requirement」は必要とされる参加者のレーティング範囲を示しています。たとえば、Div. 1 はレーティングが1900以上の参加者を対象としており、より難易度の高い問題が含まれています。これに対して、Div. 4 ではレーティングが1400以下の参加者が対象となるため、比較的簡単な問題が出題されることが多いです。
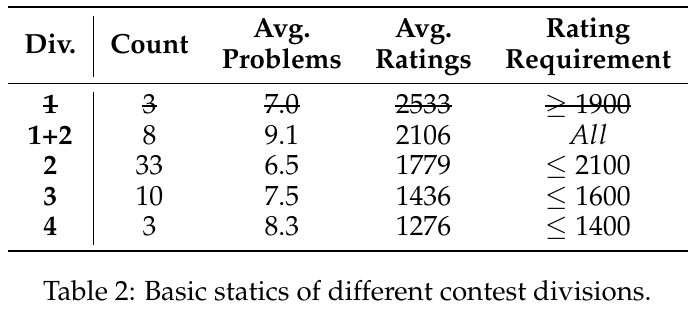
この表は、異なるコンテスト部門の基本的な統計情報を示しています。「Div.」は部門で、「Count」はコンテストの数、「Avg. Problems」は平均問題数、「Avg. Ratings」は平均レーティング、「Rating Requirement」は参加者に必要なレーティングを示しています。例えば、Div. 1の平均レーティングは2533で、参加者は1900以上のレーティングが必要です。Div. 2は平均レーティング1779で、参加資格は2100以下です。このように、部門ごとの難易度と参加条件が明確化されています。
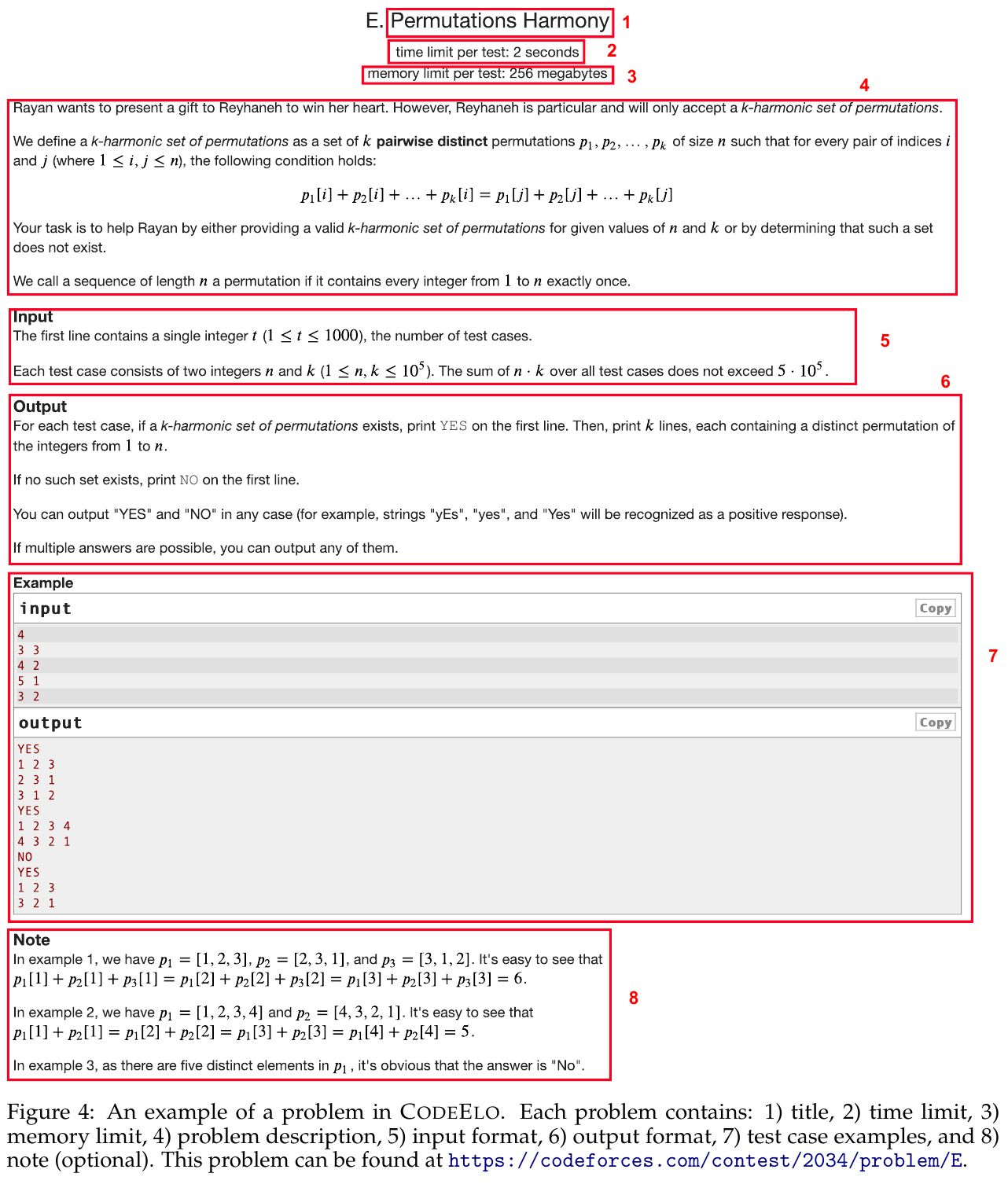
この画像は、CODEELOのコードコンペティション問題の例を示しています。タイトルは「Permutations Harmony」で、与えられたnとkに対して「k-harmonic」な順列集合を探す問題です。 最初の部分には、そのテストに関する時間制限(2秒)とメモリ制限(256MB)が記されています。問題の説明では、n個の数字とk個の順列に関する条件が述べられ、その中で条件を満たす順列が存在するかを判定することが課題とされています。 入力フォーマットではテストケースの数、各テストケースにおけるnとkが与えられ、出力フォーマットでは条件を満たす場合にはYESと順列を、満たさない場合にはNOを出力することが要求されます。 例として、4つのテストケースの入力とその出力例が示されており、最後には例に関する注釈があり、具体的な順列とその和がどのように計算されるかが説明されています。これにより、問題の要件を具体的に理解しやすくしています。
この表は、さまざまな言語モデル(LLMs)の情報をまとめたモデルカードです。表には、モデルの略称、引用情報、そしてHuggingFaceでのエンドポイントが記されています。これらの情報は、モデルの提供元やバージョン、モデルの利用方法を把握するのに役立ちます。たとえば、「Claude-3-5-Sonnet-2024-10-22」や「ChatGPT-4o-latest-2024-11-20」などが含まれていますが、これらにはHuggingFaceのエンドポイントは定義されていません。一方、他のモデルはHuggingFace経由で利用可能で、具体的なエンドポイントが記されています。これは、研究者や開発者がこれらのモデルを簡単に探し、活用するのに便利です。

この表は、CodeForcesプラットフォームの参加者の評価をパーセンタイルにしたものを示しています。各評価は、特定の参加者グループ内での相対的な位置を示しており、上位のパーセンタイルに位置するほど高い能力を持つことを意味します。評価は2024年11月に収集されたデータに基づいています。 例えば、パーセンタイル1に位置する参加者の評価は348で、これはその評価が全体の1%の参加者よりも上だということを示しています。逆に、評価4009はトップの1%(パーセンタイル100)に位置します。これにより、参加者のプログラミングスキルを比較したり、特定のモデルが人間の参加者とどの程度競えるかを評価する基準になります。 このデータは、研究でのモデルの能力評価に使われ、人間の競技プログラマーとの比較を可能にします。
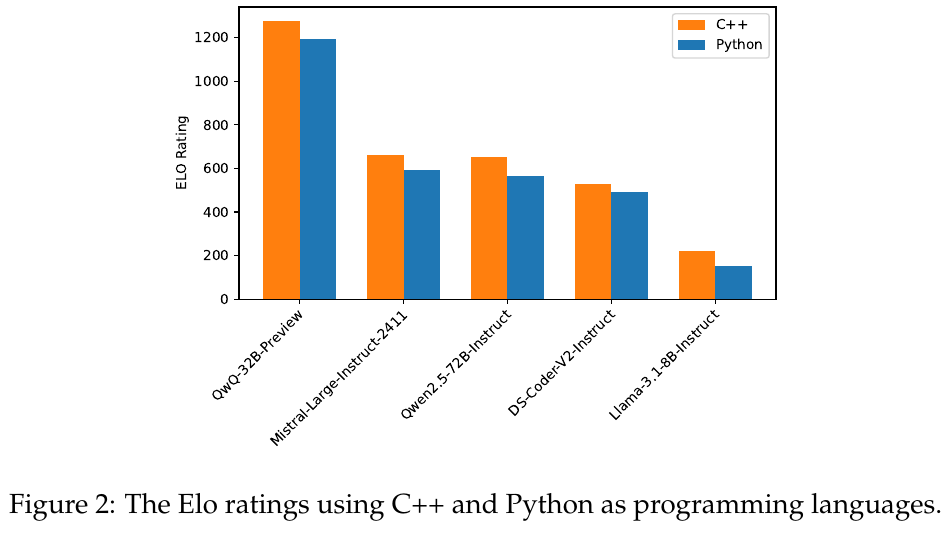
この図は、C++とPythonを用いたプログラミング言語でのEloレーティングを比較したものです。図には異なるモデルのEloレーティングが示されており、オレンジがC++、青がPythonを表しています。各モデルについて、C++のほうがPythonよりも高いEloレーティングを示しており、特にQwQ-32B-Previewモデルではその差が顕著です。これは、競技プログラミングにおける実行効率がC++でより達成しやすいため、現行のベンチマークでPythonのみを用いると正確な評価を得られない場合があることを示しています。この結果から、モデルがC++を選択することが効率面で有利であることが示唆されます。