
この論文は、小規模データから効果的に知識を学ぶための新しい手法「合成継続事前学習」を提案しています。限られたデータでも多様な知識をモデルに学習させ、高精度な質問応答や命令追従が可能になりました。
論文:Synthetic continued pretraining
GitHub:https://github.com/zitongyang/synthetic_continued_pretraining
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
この研究のポイントは?
本論文の内容は、Stanford大学の研究で、「小規模なドメイン固有のデータから効率的に知識を学習するための新しい合成データ生成と継続事前学習の手法を提案する」というものです。
本研究のポイントは、以下の通りです。
つまり、提案された合成継続事前学習は、小規模なデータからでも効率的に知識を獲得し、さまざまなタスクで高い性能を発揮できる、新しい学習手法の可能性を開いた研究です。
背景
従来の大規模なインターネットテキストによる事前学習では、言語モデルが効率的に知識を獲得するのが難しいという問題がありました。特に、小規模なドメイン固有の文書からの学習では、各事実がほとんど出現しないため、十分な知識の獲得が困難です。
この問題を解決するため、著者らは小規模なドメイン固有のコーパスを使用して、より多様で学習しやすい合成コーパスを生成し、その合成データを用いた継続事前学習を行う手法を提案しています。
具体的には、「EntiGraph」というアルゴリズムを使用して、元の文書から重要なエンティティ(名前や場所、概念など)を抽出し、それらのエンティティ間の関係をもとに多様なテキストを生成します。この合成データによる学習により、モデルは元の文書にアクセスしなくても、その内容に基づく質問に回答したり、一般的な指示に従うことができるようになります。
また、この方法は、元の文書を参照する従来の生成手法と組み合わせると、さらなる性能向上が見込めます。
提案手法
この論文で提案されている「Synthetic Continued Pretraining(合成継続事前学習)」は、小規模なドメイン固有のコーパスから効果的に知識を獲得するための新しい手法です。従来の大規模なインターネットテキストを使った事前学習では、言語モデルが知識を獲得する際にデータ効率が悪いという問題がありました。特に、小さなドメインでは各事実がほとんど現れないため、モデルが知識を効率的に学習することが難しいです。この問題を解決するために、著者らは「EntiGraph」という手法を用いた合成データ生成を提案しています。
EntiGraphは、まず元の小規模なコーパスから重要なエンティティ(例えば、名前、場所、概念など)を抽出します。その後、これらのエンティティ間の関係をモデル化し、それに基づいて多様なテキストを生成します。この合成テキストは、元のドメインに存在する知識の多様な表現を提供し、言語モデルの学習効率を高めます。たとえば、ある数学のテキストでは「線形空間」と「ベクトル」などのエンティティが登場し、それらの関係性を様々な視点から説明する新しい文章を生成します。

この合成データを使用して、言語モデルの事前学習を継続することで、元の文書にアクセスせずとも、その内容に関連する質問に正確に回答できるようになります。また、生成された合成データを用いてモデルを調整することで、質問応答以外にも要約や命令の理解など、多様なタスクに対しても優れた性能を発揮します。
提案された手法は、特にデータが少なく限られたドメインに対して有効であり、伝統的な方法と比べて、より効率的に知識を獲得できる点が大きな利点です。加えて、この手法はRetrieval-Augmented Generation(RAG)などの非パラメトリックなアプローチと併用することで、さらに性能を向上させることが確認されています。
実験
実験では、提案手法の効果を確認するため、主に以下のステップを実施しています。
まず、QuALITYという長文読解のベンチマークデータセットを使用し、小規模なコーパス(1.3Mトークン)から始めて、EntiGraphアルゴリズムを使って600Mトークンの合成データを生成しました。次に、Llama 3 8Bというモデルを用いて、この合成データで継続的に事前学習を行いました。これにより、モデルが元のコーパスに含まれる知識を効率的に学習できるかを確認しました。
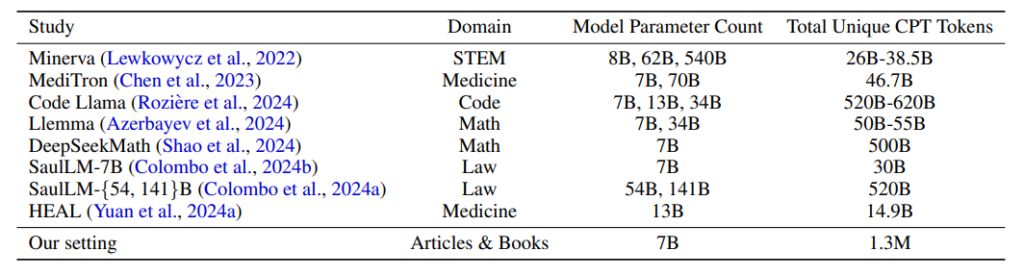
実験の結果、600Mトークンの合成データで事前学習を行ったモデルは、クローズドブック形式の質問応答タスクで精度が向上し、合成データのトークン数が増えるに従って性能が向上することが確認されました。この性能向上は、ログ線形にスケーリングする傾向が見られました。
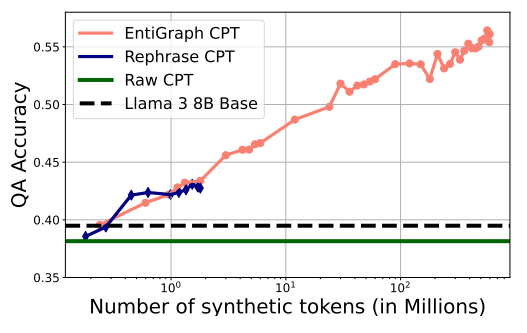
対照的に、単純なパラフレーズや元のデータでの事前学習では、効果が限定的であり、提案手法の優位性が示されました。
また、提案手法による合成データを用いた事前学習モデルは、オープンブック形式のタスクにおいてもRetrieval-Augmented Generation(RAG)と組み合わせることでさらなる精度向上が見られました。この結果から、提案手法が取得したパラメトリック知識は、非パラメトリックなリトリーバル手法とも相補的に機能することが分かりました。

さらに、合成データで事前学習を行ったモデルに命令追従の調整を施すことで、クローズドブックの要約タスクでも良好な性能を発揮しました。合成データを用いた事前学習が、合成データ自体の内容に基づいた命令の理解や遂行にも貢献していることが確認されました。
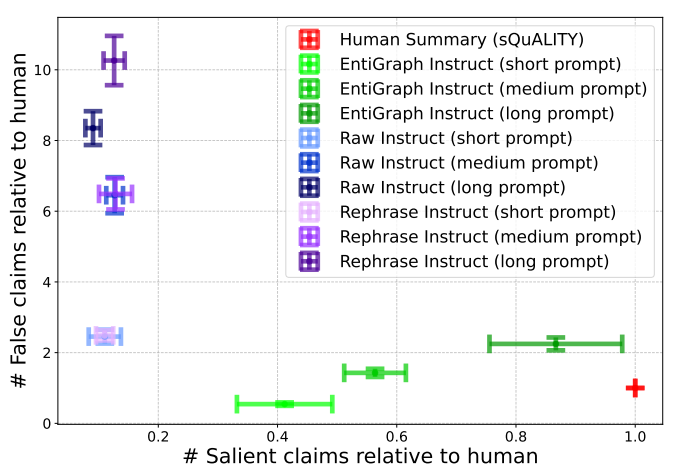
結論
この論文の結論では、提案された「Synthetic Continued Pretraining(合成継続事前学習)」が、小規模で特定のドメインに特化したデータから効率的に知識を獲得できる有効な手法であることが確認されました。
従来の大規模データによる事前学習と比べ、合成データを用いた事前学習は、少ないデータからでも豊富な知識を引き出し、モデルの性能を大幅に向上させる可能性が示されました。