- 動画データに基づく細粒度動作認識のための新しい半教師あり学習フレームワーク「SeFAR」を提案
- ラベル付きデータとラベルなしデータを組み合わせ、高精度な擬似ラベル生成による性能向上を実現
- 実験で最先端手法を上回る性能を示し、計算コストやモデルサイズも低く抑えた実用的な手法
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この論文では、動画データに基づいた細粒度動作認識を対象として、新しい半教師あり学習フレームワーク「SeFAR」を提案しています。動作認識は、スポーツや医療分野などに応用される重要な課題ですが、細粒度の動作認識では、ラベル付きデータの収集が難しく、その結果高精度なモデルを構築する際の障壁となっています。この課題を解決するために、提案手法はラベル付きデータとラベルなしデータを組み合わせて活用する点が特徴です。
SeFARの主な構成要素は以下の通りです。まず、「教師―生徒モデル構造」を採用しており、一般的な半教師ありのアプローチに基づいています。この仕組みでは、教師モデルがラベル付きデータを用いた初期学習によって強い基盤を持ち、これを用いてラベルなしデータに対して擬似ラベルを生成します。その後、これらの擬似ラベルを用いて生徒モデルを訓練し、性能を段階的に向上させます。
さらに、提案手法では「時間的拡張技術(Temporal Perturbations)」が導入されており、動作認識の細粒度タスクにおいて重要な時間的情報を積極的に活用する工夫が見られます。同時に、「最適化の安定化」アプローチも施行され、多様なデータバリエーションに対してもモデルが強固な性能を発揮する点が確認されています。
実験の結果、SeFARは複数の細粒度および粗粒度データセット(例: Something-Something V2, UCF101など)において、現状の最先端手法を上回る性能を示しました。特に、擬似ラベル生成の精度を向上させるための工夫と、時間的情報の効果的な利用が、モデルの優位性につながっています。また、提案手法は計算コストやモデルサイズが比較的低く抑えられており、実用性の高さも評価されています。
図表の解説
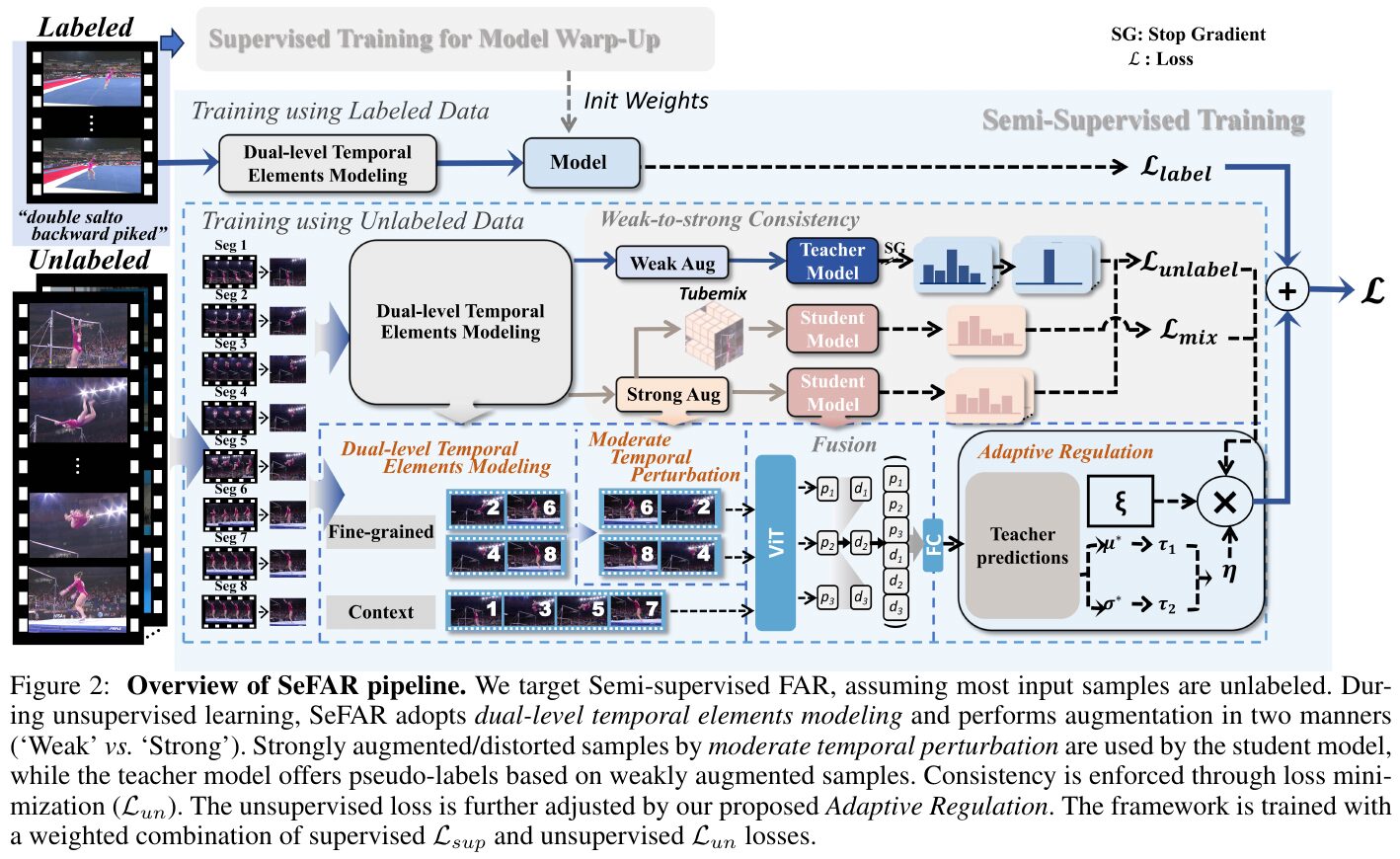
この図は、SeFAR(Semi-supervised Fine-grained Action Recognition)フレームワークの概要を示しています。SeFARは、ラベル付きとラベルなしのデータを用いて、細かなアクションの認識を行います。教師モデルと生徒モデルを使用し、弱い拡張(Weak Augmentation)を基にした擬似ラベルでモデルを指導します。強い拡張(Strong Augmentation)を生徒モデルに適用し、一貫性を損失最小化で保ちます。Adaptive Regulationを導入して不安定な学習を安定化し、最終的な損失はラベル付きデータとラベルなしデータの損失の組み合わせで計算されます。
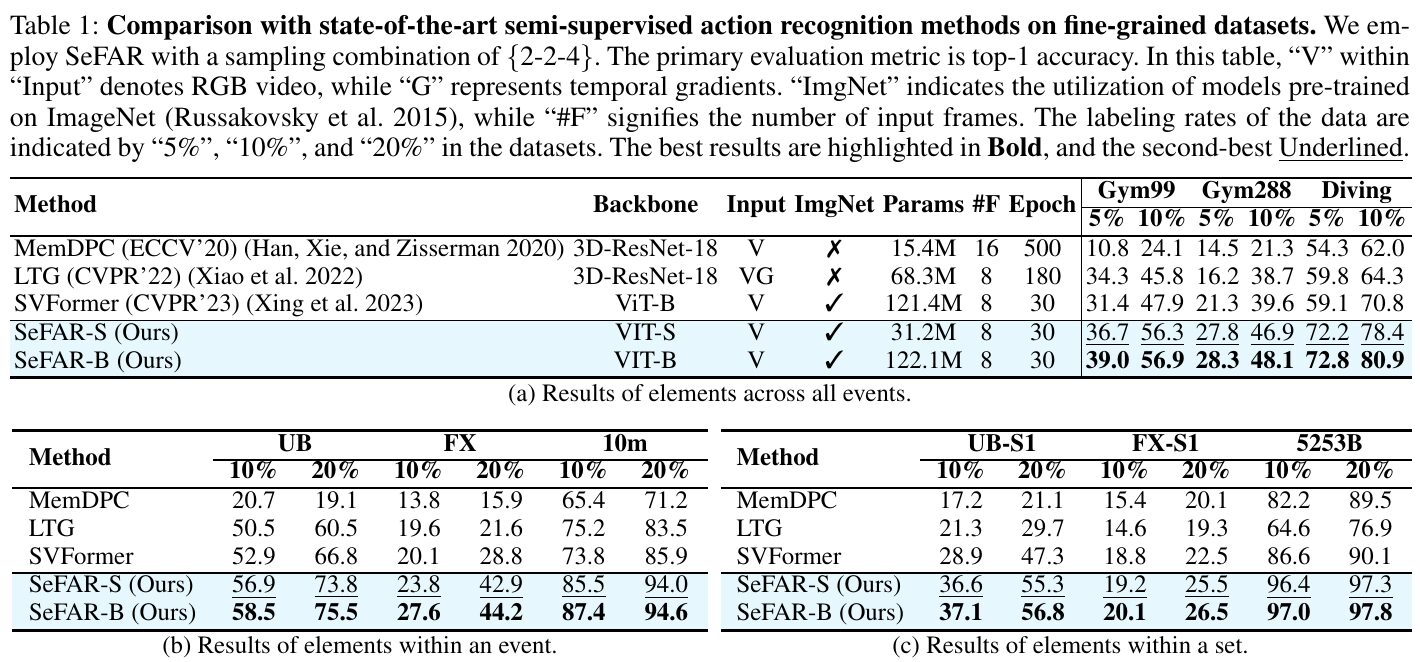
この表は、微細動作認識のための最先端の半教師付きモデルを比較した結果を示しています。SeFARモデルは、少数のラベル付きデータを使用して、高精度を達成しています。表の3つのデータセット(Gym99、Gym288、Diving)でトップ1の精度を競いました。特に、SeFAR-B(大規模版)が最も優れた性能を示しており、特定のイベントや要素内でも高い精度を発揮しています。これは、半教師付き学習の新しいアプローチとして、動作の微細な違いを正確に捉える能力が向上した結果です。

この図は、FineGymデータセットから抽出された映像の例を示しています。上部には「pike sole circle backward with 0.5 turn to handstand」という行動が示され、下部には「… 1 turn …」といった詳細な動作が含まれています。図の中で、さまざまな多言語大規模モデル(MLLM)がこれらの動作を認識するテストが行われていますが、いずれも正確に識別できていません。これにより、Fine-grained Action Recognition(FAR)の課題の難しさが示されています。FARは、映像内の細かな動作を正確に捉える技術を強化するために重要です。
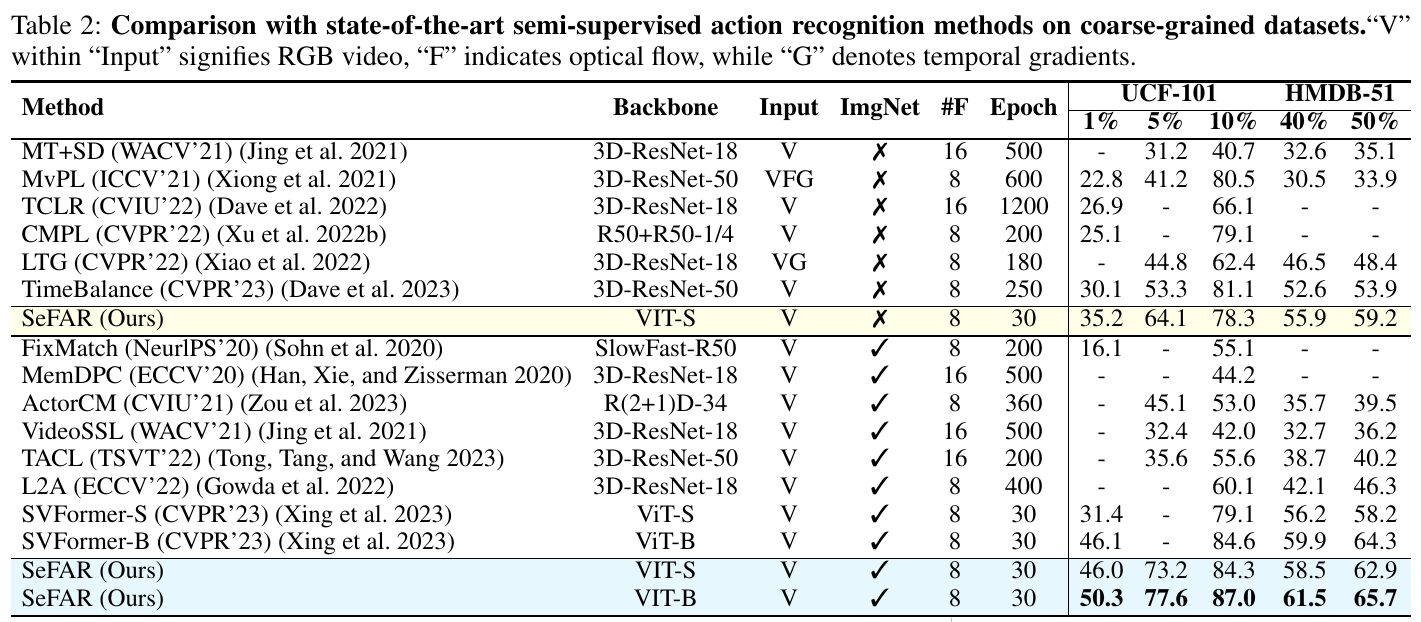
この画像は、最新の半教師付き行動認識手法を粗粒度データセットで比較した表です。各手法のバックボーンや使用する入力の種類(RGB動画や光フローなど)、ImageNetの使用有無、訓練に使ったエポック数などの情報が記載されています。表の右側には「UCF-101」と「HMDB-51」データセットの異なるラベル割合における識別精度が示されており、SeFAR(提案手法)が多くの項目で高い性能を達成していることが強調されています。
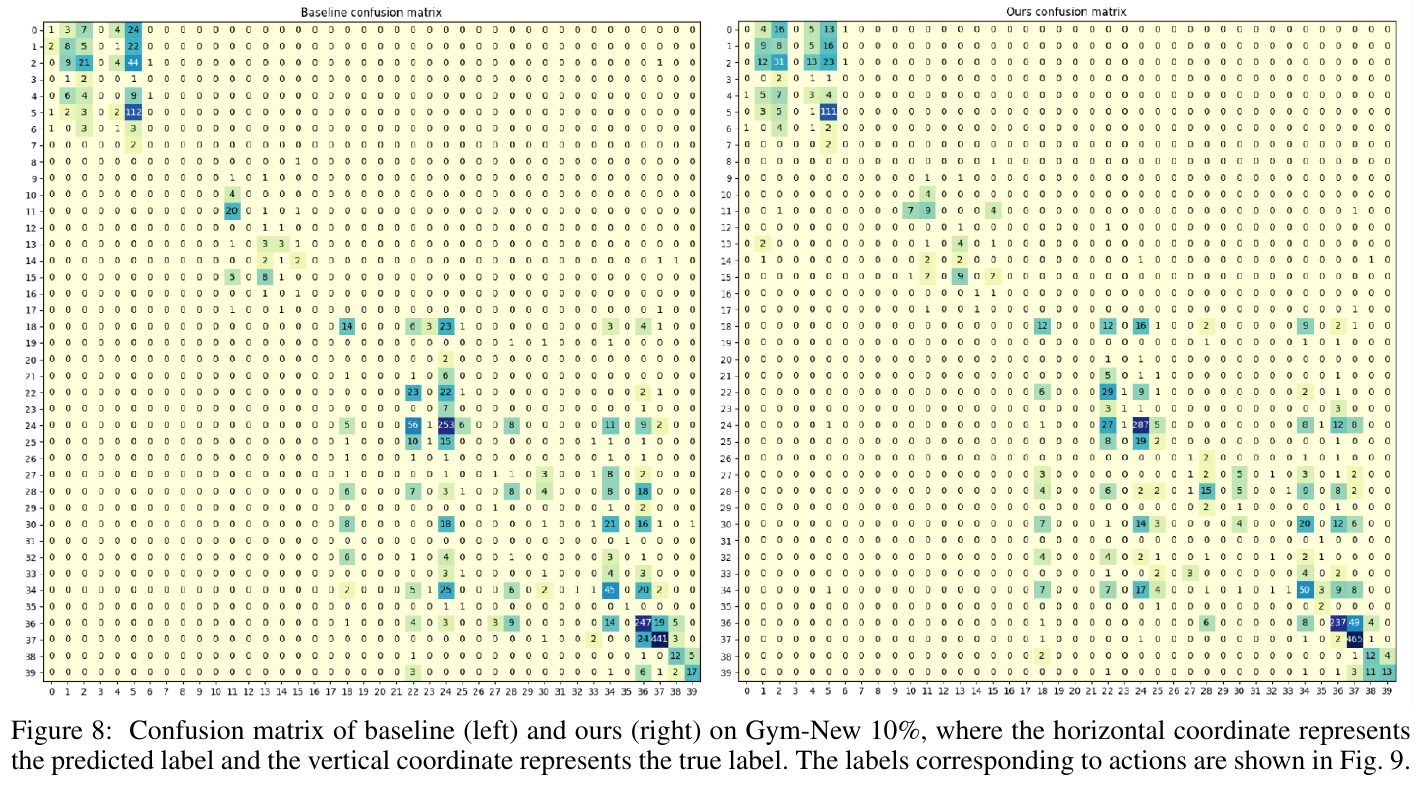
この画像は論文内のFigure 8で、ベースライン(左)と提案手法(右)の混同行列を示しています。Gym-New 10%における行動認識の性能を比較しており、行は実際のラベル、列は予測されたラベルを表しています。提案手法では、主要目標である誤分類の減少が見られ、特に反対の方向性を持つ行動(例:前方対後方)間の混同が減少しています。これにより、全体的な認識精度が向上しています。
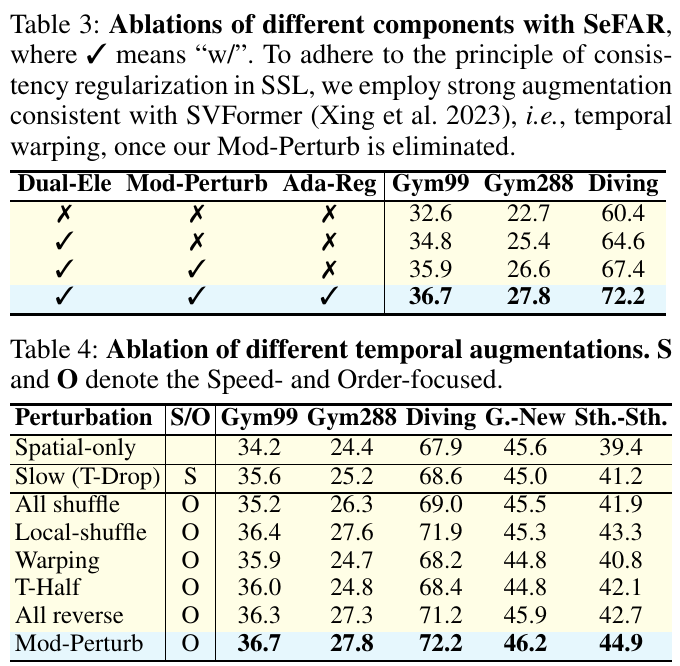
テーブル3は、SeFARフレームワークの各コンポーネントの性能に関する比較を示しています。Dual-LevelやMod-Perturb、Adaptive Regulationの有無がGym99やGym288、Divingデータセットでの結果にどのように影響するかを見ることができます。結果として、すべての技術を組み合わせたときが最も高いパフォーマンスを示しています。 テーブル4は、さまざまな時間的拡張方法の影響を比較しています。「S/O」は速度または順序に焦点を当てた拡張を示します。ここで、Mod-Perturbが他の拡張手法よりも一貫して優れた結果をもたらしていることがわかります。
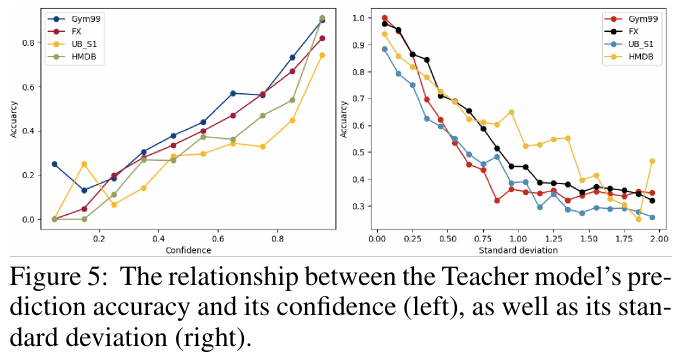
画像では、「Confidence」と「Standard deviation」に対する教師モデルの予測精度が示されています。「Confidence」(左グラフ)では、予測の自信度が高まるにつれて精度が上昇する傾向が見られます。「Standard deviation」(右グラフ)では、予測の標準偏差が小さいほどモデルの精度が高くなる関係が示されています。このように、安定かつ高信頼の予測が重要であることを示しており、これは半教師付き学習戦略の効果を裏付けています。
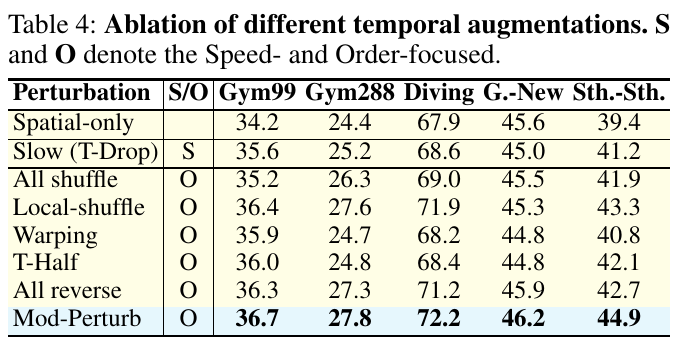
表4は、異なる時間的拡張手法のアブレーション(影響の分解)を示しています。この表では、Sがスピード重視、Oが順序重視の手法を示しています。代表的なデータセット(Gym99、Gym288、Diving、G.-New、Sth.-Sth.)で、各手法のパフォーマンスを比較しています。結果からは、Mod-Perturbという順序重視の方法が多くのデータセットで最高の性能を示していることがわかります。これにより、モデルの時間的順序の扱いが強化され、細かな動作認識が向上することが示されています。