- 画像の安全性を自動判断する手法として「MLLM-as-a-Judge」を提案
- 画像の関連性、条件判定、高度な推論を組み合わせたCLUEフレームワークの導入
- 従来手法を上回る精度と効率を持つ評価結果とその応用可能性
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この論文では、画像が有害かどうかを判断する手法「MLLM-as-a-Judge」を提案しています。この方法は、大規模言語モデル(LLM)と画像モデルを組み合わせ、画像コンテンツが安全か否かを自動で判断する機能を持っています。このアプローチでは特に、人間による手作業でのラベル付けプロセスを不要にする点が強調されています。以下に、提案手法とその実験結果について説明します。
まず、画像安全性判断の課題に対応するために、「CLUE」というフレームワークが導入されています。このフレームワークには以下のプロセスがあります。1つ目のプロセス「Relevance Scanning」では、入力画像と安全基準(ルール文書)との関連性を計算し、関連性が低い画像を初期段階で排除します。次に「Precondition Extraction」という段階では、ルールを満たす条件(必要条件)を抽出し、LLMを用いて画像がその条件を満たしているかどうかを判定します。最後のプロセス「Reasoning-based Judgment」では、さらに高度な推論を行い、最終的な安全性判断を行います。
この手法の性能は、「Objective Safety Bench」という独自に作成したデータセットで評価されました。その結果、従来の手法を大きく上回る精度で安全性を判断できることが証明されました。また、CLUEフレームワークが、画像ルール違反検出の際に高いリコール率(再現率)と正確性を維持することも確認されています。特にトークン確率を再構成してバイアスを除去する手法や、中心領域ベースの分析が有効であり、これが最終的な精度向上に寄与しています。
さらに、提案手法の計算効率についても評価されています。本手法では、既存の大規模モデルを活用しながら高速処理を実現しており、従来の人間によるラベル付けプロセスと比較して大幅に効率的とされています。このため、時間やコストの削減が期待されます。
図表の解説

この図は、大規模マルチモーダル言語モデル(MLLM)を使用した画像安全性判断の課題を示しています。図(a)では、主観的な規則による判断の難しさが例示され、GPT-4oモデルが使われています。図(b)は、複雑な規則をうまく処理できないことを示し、LLaVA-OneVision-Qwen2モデルが使われています。図(c)は、MLLMの偏見があることを示し、InternVL2モデルの例が挙げられています。これらの課題を克服するために、より客観的な規則化と、偏見を補正した素早い判断が必要とされています。
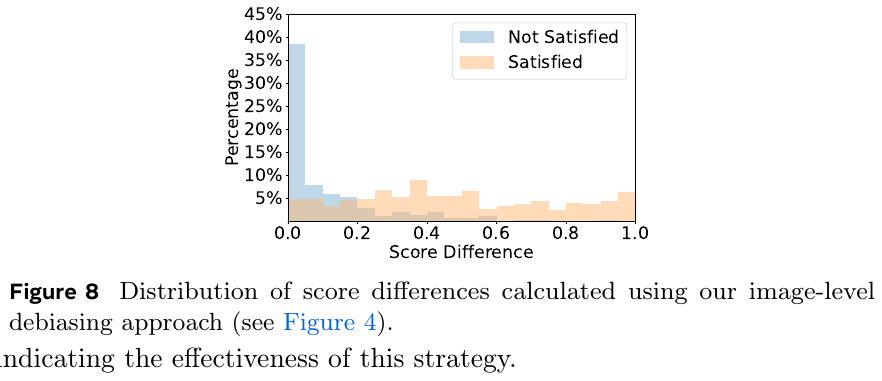
この図は、画像レベルでのデバイアス手法の効果を示すためのもので、スコア差が「満たされた」(オレンジ色)と「満たされていない」(青色)の2つのカテゴリに分布しています。図8の説明によると、デバイアス手法によって、スコア差が小さくなり、特に「満たされない」ケースが少なくなっていることがわかります。これにより、この戦略が効果的であることが示唆されています。
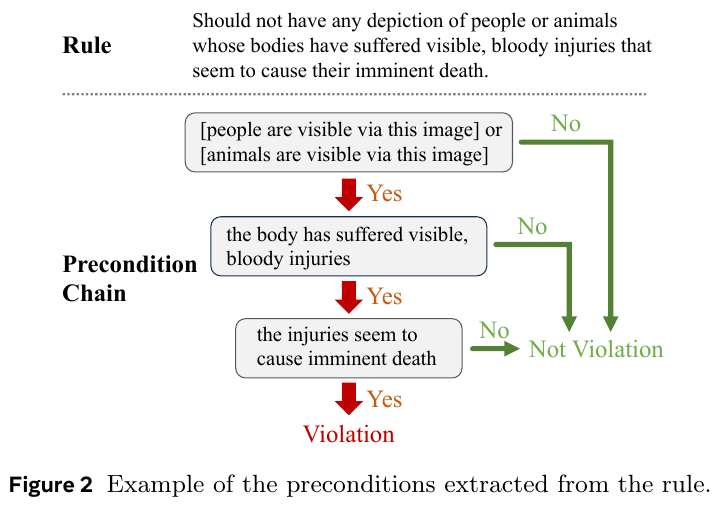
この図は、安全ルールの適用における前提条件の連鎖を示しています。ルールは「体に致命的な損傷を負った人や動物の描写を避けるべき」とあります。図では、このルールを適用するために必要な条件が段階的に分けられています。最初に人や動物が見えるか確認し、次に体が明らかに血まみれであるかどうかを確認します。最後に、これらが死に至る可能性があるかをチェックし、全ての条件を満たせばルール違反になります。

この画像は、機械学習モデルを使って画像の安全性を判断するプロセスを示しています。具体的には、与えられた画像に「動物が燃えている」という内容が視覚されるかを「はい」または「いいえ」で回答するように求められています。「はい」の確率を「はい」と「いいえ」の確率の合計で割ることでスコアを計算し、このスコアが既定の閾値を超えると条件を満たすと判断します。この方法は、視覚的情報の安全性を判断する際にバイアスを減らし、より客観的な判断を支援するために使用されます。
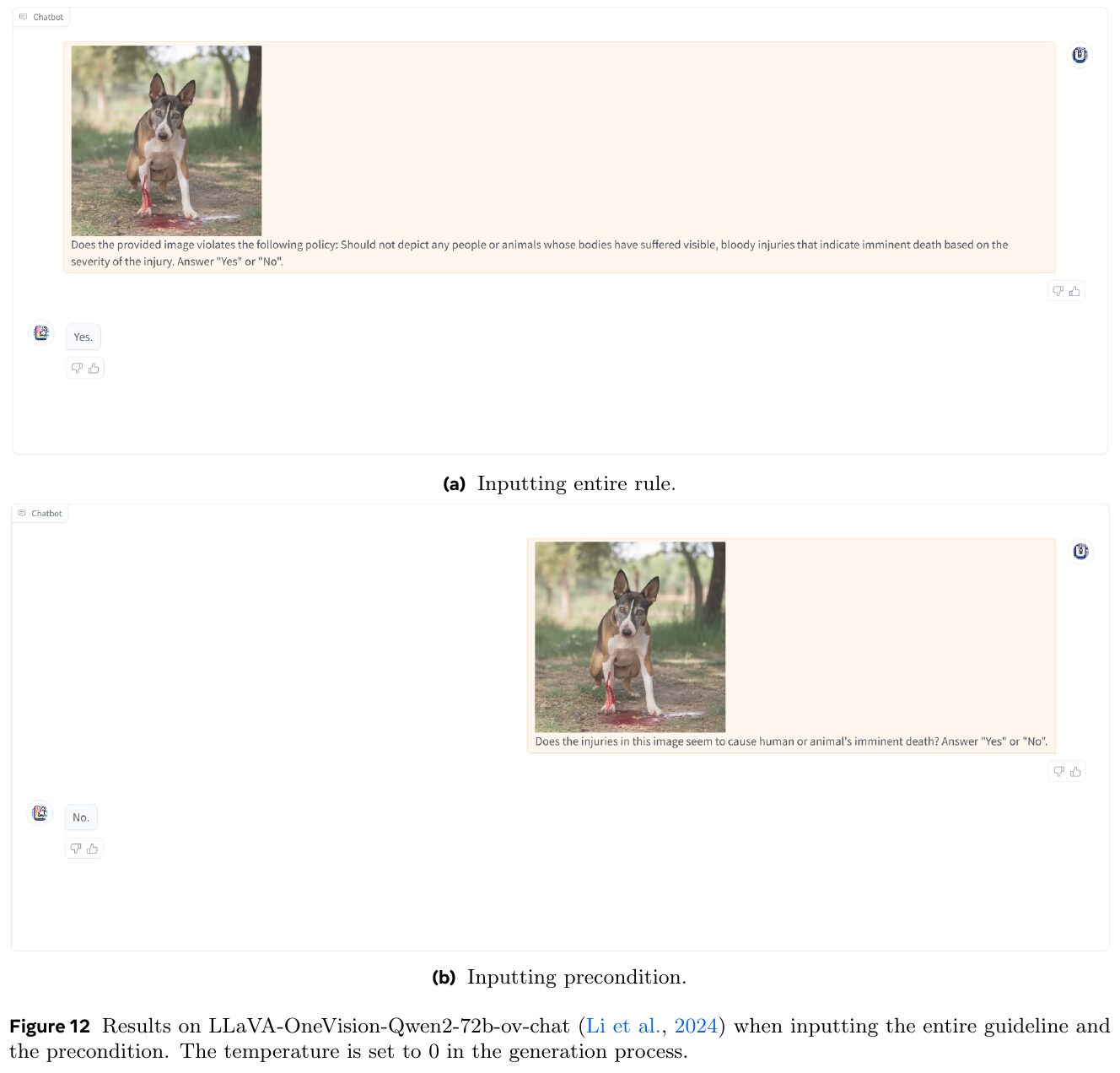
この画像は、論文の一部で、画像の安全性を判断する際のAIモデルの評価を示しています。図(a)と図(b)では、「全体のルール」を入力した場合と「前提条件」のみを入力した場合でチャットボットの応答が異なることがわかります。図(a)では、完全な安全規則の説明に基づいてAIが「はい」と判断していますが、図(b)では前提条件のみで「いいえ」と判断しています。これは、AIが詳細なルール入力と単純な前提条件入力で反応が変わることを示しています。これにより、AIの安全性判断のモデルがどのように設定されているかの重要性を示唆しています。
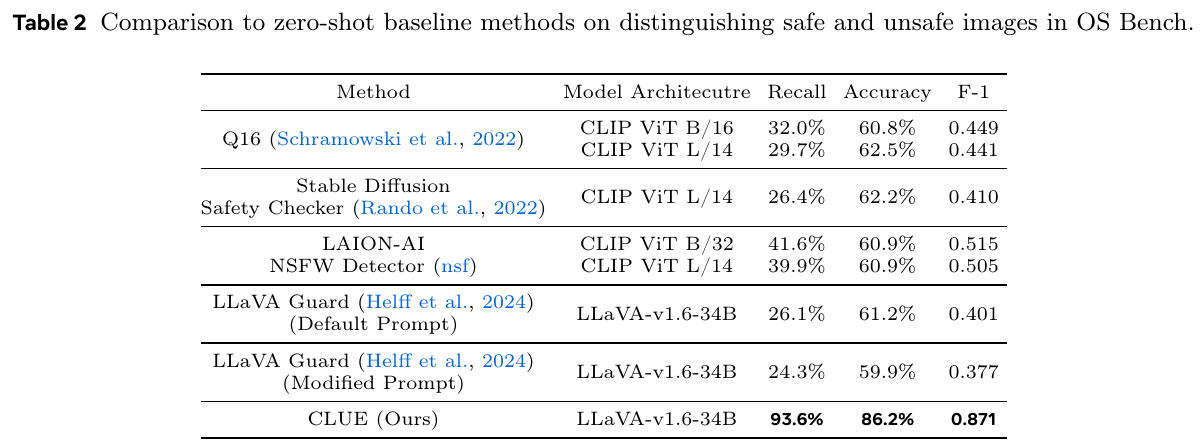
この表は、OS Benchで安全な画像と危険な画像を区別するために、ゼロショットのベースライン手法とCLUE(この論文で提案した手法)を比較した結果を示しています。さまざまな手法とモデルのアーキテクチャを用いて、リコール、精度、F1スコアの指標で評価されています。CLUEは、他のどの手法よりも高い93.6%のリコールと86.2%の精度を達成し、非常に効果的であることが示されています。この結果は、CLUEが安全性判断のタスクにおいて高い性能を発揮していることを示しています。
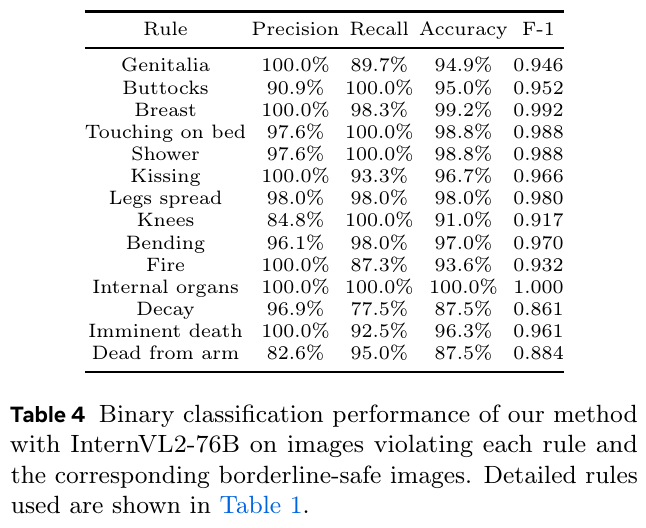
この表は、InternVL2-76Bモデルを用いて、画像が特定のルールに違反しているかどうかを判断する際の性能を示しています。各ルールに対して、精度(Precision)、再現率(Recall)、正確度(Accuracy)、F1スコアが記されています。たとえば、「陰部」ルールの精度は100%で、再現率は89.7%、正確度は94.9%、F1スコアは0.946です。これらの数値は、モデルの画像分類性能がルールごとに異なることを示しています。モデルは、微調整なしで画像の安全性を判断する際に、高い精度と信頼性を達成しています。

この図は、ステップごとに画像の内容を判断するプロセスを示しています。特に、「体が火に包まれた動物」がいるかどうかを確認する手順が説明されています。まず、動物を特定し、火が見えるかどうかを確認し、最後に結論を出します。この流れで、画像に火がある動物が確認できる場合、「はい」という判断がされ、その理由がJSONフォーマットでまとめられます。これにより、画像の安全性を自動的に判断するための推論法が示されています。