- モバイルアプリのGUI上でのエージェント評価と改善のためのA3フレームワークを提案
- タスク進行評価にOCRやLLMプログラム生成を活用した評価関数を導入
- AppAgentが複雑なタスクでLLMの限界を超える可能性を示唆
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
本論文では、モバイルアプリのGUI(グラフィカルユーザインタフェース)上で動作するエージェントを評価・改善するための新たな枠組み「Android Agent Arena(A3)」を提案しています。この枠組みは、AIモデルを用いてタスクを実行する能力を測定し、その限界を明らかにすることを目的としています。
まず、A3は、モバイルアプリケーション操作に関連する21種類のアプリからなるデータセットと、3つのカテゴリー(操作タスク、単一クエリ、マルチフレームクエリ)に分類されたタスク群を提供します。これらのタスクはさらに容易、中程度、困難という難易度に分けられ、現実の問題解決に必要なスキルを包括的に評価できる設計となっています。タスクの進行状況や結果を正確かつ効率的に判定するため、OCR(光学文字認識)や事前学習されたLLMのプログラム生成を活用した評価関数を導入しています。
提案されたA3フレームワークに基づく実験では、LLMであるGPT-4と独自開発のエージェント「AppAgent」の性能を比較しました。結果として、GPT-4は簡単なタスクには一定の成功率を示しましたが、複雑な操作や動的コンテンツを含むシナリオにおいては多くの失敗が見られました。一方で、AppAgentはタスク成功率が向上し、特に操作型タスクでの強みが確認されました。
研究の結論として、現行のLLMはモバイルGUIタスクにおいて依然として複雑なシナリオに弱く、特化したエージェントの必要性が示されています。
図表の解説
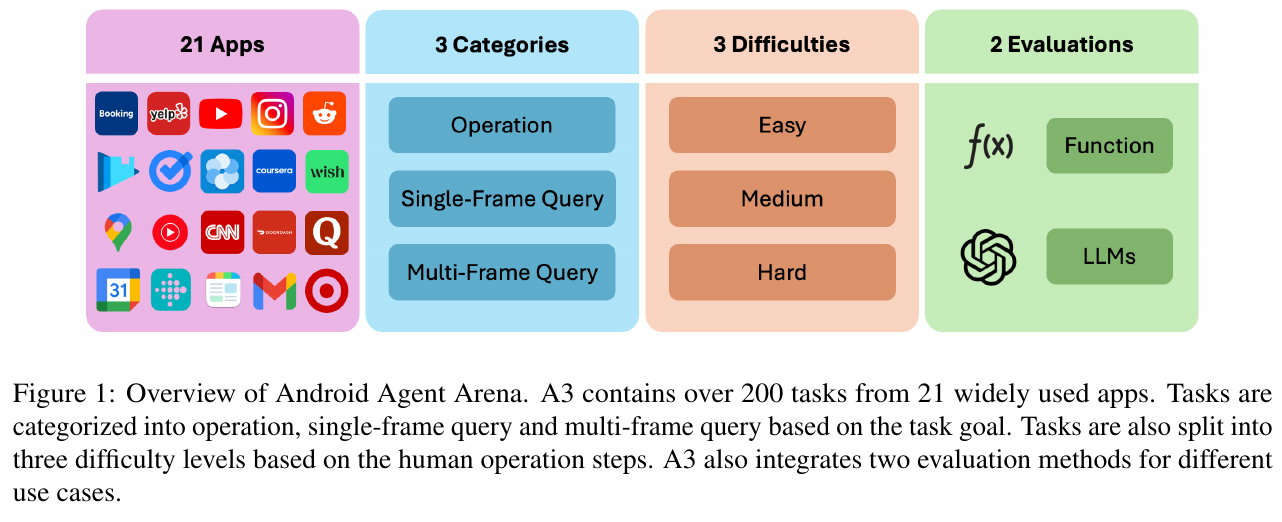
画像は、Android Agent Arena(A3)の概要を示しています。A3は21のよく使われるアプリから200を超えるタスクを含んでおり、それを操作、シングルフレームクエリ、マルチフレームクエリの3つのカテゴリに分類しています。さらに、タスクは難易度別に簡単、中程度、難しいの3段階に分けられています。評価方法は関数評価と大規模言語モデル(LLMs)を用いた2種類があります。これは、異なるユースケースに対応した評価を可能にするためのものです。
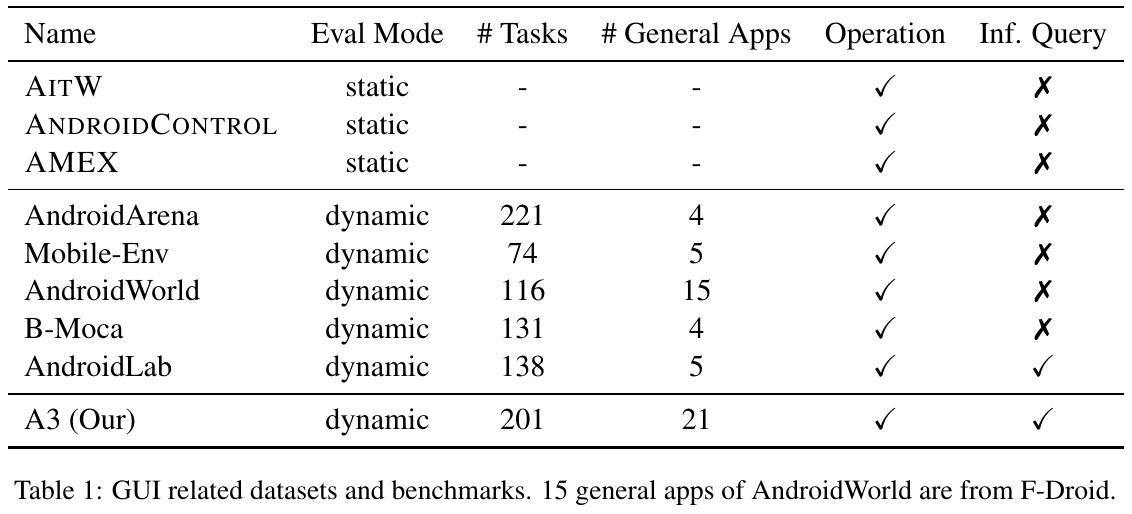
この画像は、Android GUI エージェントに関連するデータセットとベンチマークを示しています。表は、評価モードやタスク数、一般アプリ数など、各データセットの特徴を比較しています。静的評価とは異なり、ほとんどのデータセットは動的評価を採用しており、操作や問合せが可能なことが示されています。A3は、特に実世界のタスクに対応できるように設計されており、21のアプリと201のタスクを提供しています。
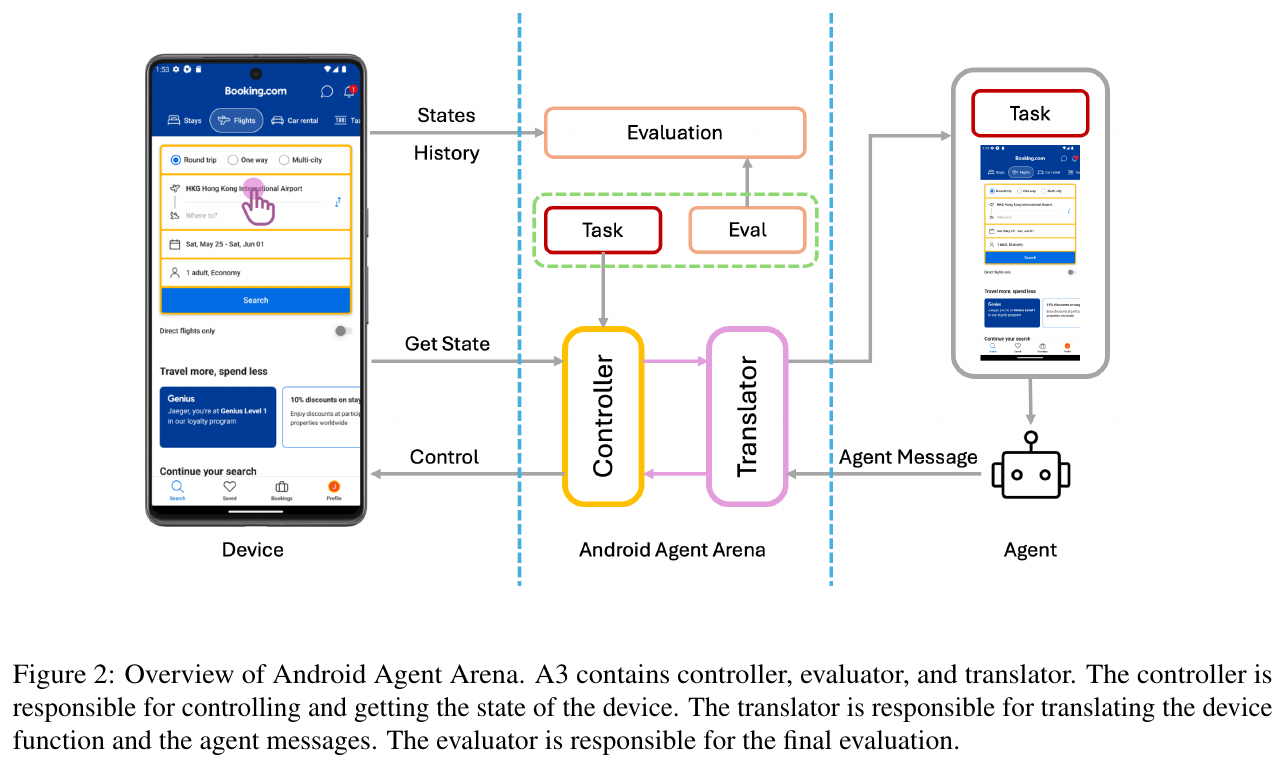
画像は、Android Agent Arena (A3)の概要を示しています。A3は、モバイルデバイス上でタスクを自動的に実行するためのプラットフォームで、コントローラー、トランスレーター、エバリュエーターの3つのコンポーネントで構成されています。コントローラーがデバイスの状態を取得し、トランスレーターがそれをエージェントメッセージに変換します。エバリュエーターは、タスクが正しく完了したかどうかを評価する役割を担っています。このシステムは、リアルワールドのシナリオに基づいて、さまざまなアプリケーションから多様なタスクを評価することが可能です。
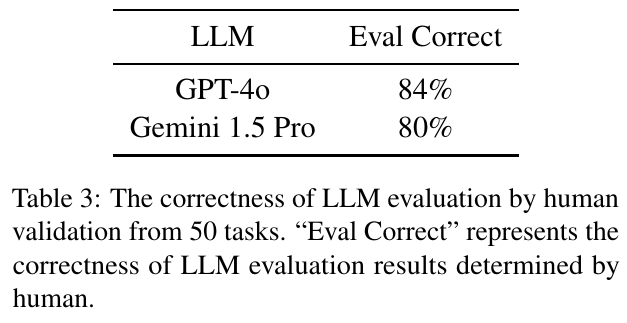
この図は、「GPT-4o」と「Gemini 1.5 Pro」という2つの大規模言語モデル(LLM)の評価結果を示しています。表には、これらのモデルが全体の50のタスクで正しく評価できた割合が示されています。具体的には、GPT-4oが84%、Gemini 1.5 Proが80%の正答率を持っています。この結果は人間による評価で確認されており、LLMがどの程度正確にタスクを評価できるかを示しています。
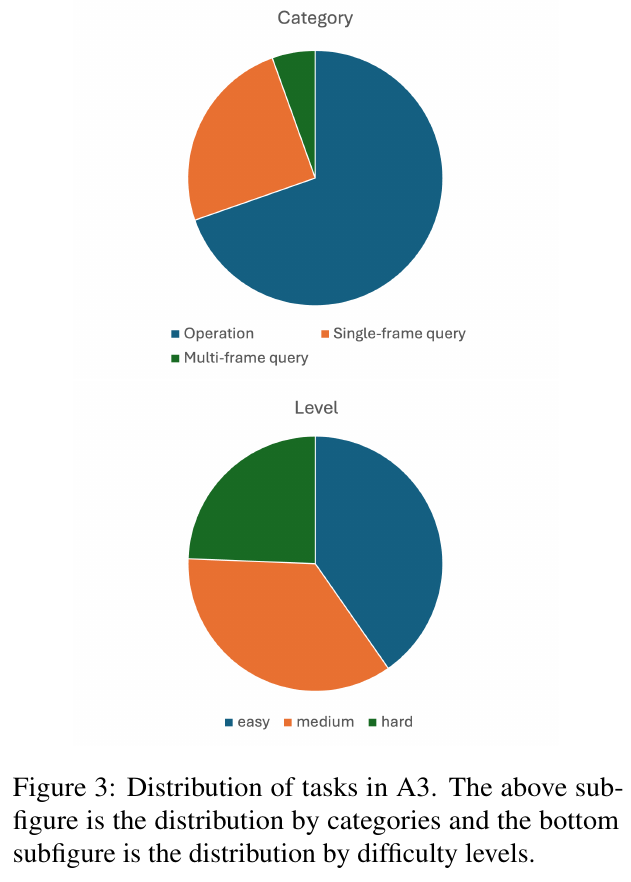
図3は、A3でのタスクの分布を示しています。上の円グラフはタスクを3つのカテゴリー(操作、シングルフレームクエリ、マルチフレームクエリ)に分けた割合を示しており、操作が最も多くの割合を占めています。下の円グラフはタスクを難易度で分けたもので、簡単、中程度、難しいに分かれています。これにより、タスクの種類と難易度の比率を視覚的に理解できます。
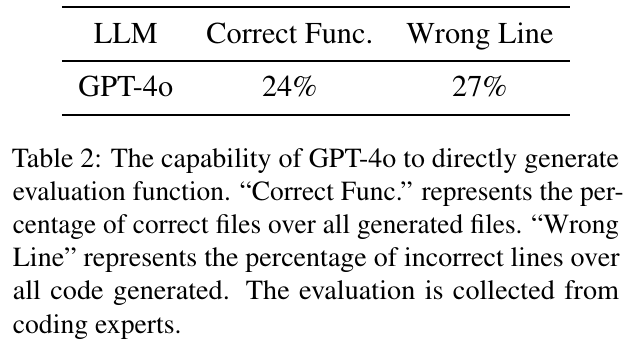
この図は、GPT-4oが評価関数を直接生成する能力を示しています。「Correct Func.」は生成されたコードのうち正しい評価関数の割合を示し、「Wrong Line」は全生成コードの中で間違った行の割合を示しています。GPT-4oは24%の正しい評価関数を生成できる一方で、27%は何らかの誤りを含んでいることを意味します。専門家によるコード評価の結果に基づいています。
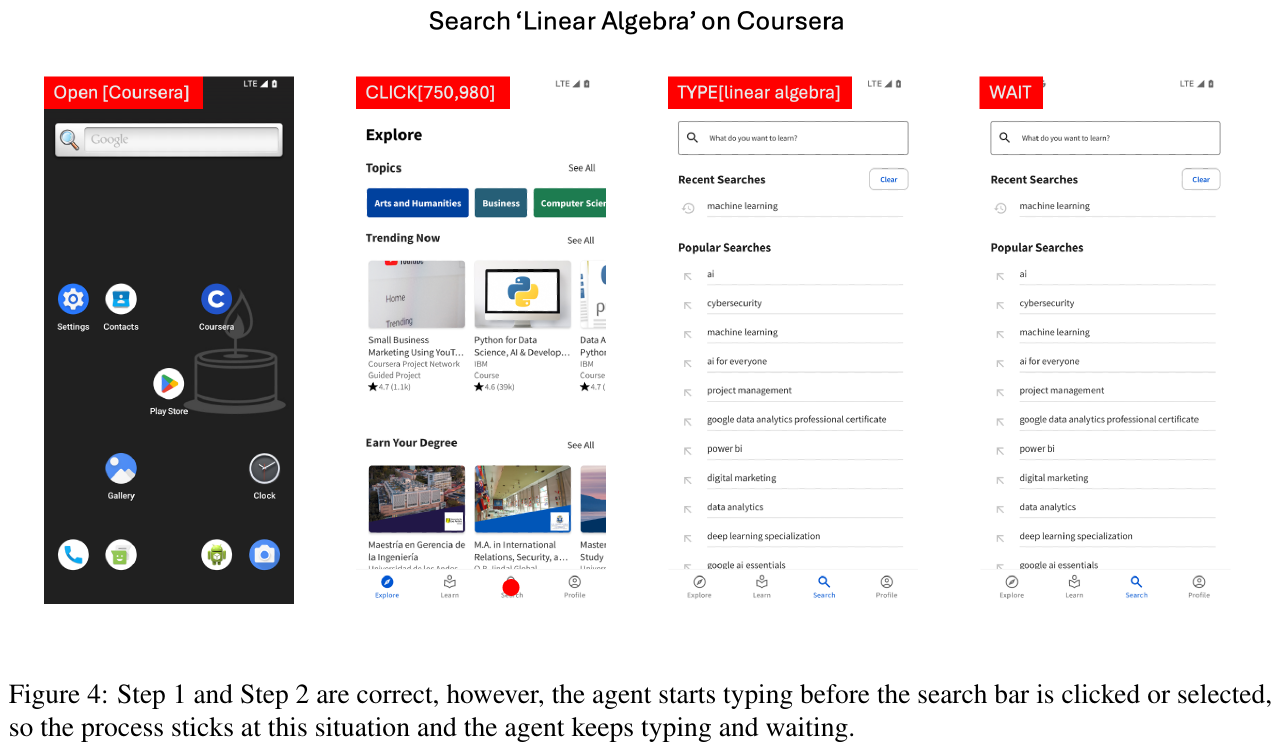
この図は、モバイルアプリ「Coursera」で「Linear Algebra」を検索する過程を示しています。最初のステップでは、アプリが正しく開かれ、ホーム画面が表示されます。その後、検索バーにアクセスせずに検索用語を打ち始めます。この結果、予期したプロセスが進まなくなり、AIエージェントが入力し続けたり、待機し続けたりする状況が生まれてしまいます。これは、ユーザーインターフェース(UI)操作の自律性を評価する試みの一部です。

表5は、AIエージェントのA3プラットフォームにおける動的評価結果を示しています。これは、難易度別に操作、シングルフレームクエリ、マルチフレームクエリのカテゴリーで評価されています。InternVL2、GPT-4o、AppAgentの3つのエージェントが評価され、AppAgentが全体的に最も高い成功率を示していますが、特に操作タスクで強い傾向があります。一方で、マルチフレームクエリはどのエージェントでも成功率が低いことが確認できます。これは、現実の状況におけるマルチステップの過程を把握することの難しさを示しています。