- 地理空間推論能力を評価するための新しいデータセット「MapEval」の提案
- リアルな地理情報に基づいた複数カテゴリでのLLM評価方法の確立
- GPT-4など最新モデルを用いた地理情報タスクの性能検証と課題の発見
論文:MapEval: A Map-Based Evaluation of Geo-Spatial Reasoning in Foundation Models
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この論文では、地理空間推論能力を評価するための新しいベンチマークデータセット「MapEval」が提案されています。MapEvalは、テキスト、API、ビジュアルマップの3種類のデータコンテキストでLLMの性能を評価する統合的なフレームワークを提供します。これにより、地理的情報の検索や空間的な常識推論を必要とする複雑なマルチモーダルタスクへの対応力が客観的に測定できます。
提案手法では、Google Mapsから収集したリアルな地理情報を使用して、複数のカテゴリ(場所情報、最寄りの施設探し、ルート案内、旅行計画、距離計算など)の質問データを作成し、テキストベース、APIベース、視覚情報ベースでLLMを評価しました。この過程で、地図画像を使用した質問やAPIツールを用いたデータ取得の性能も幅広く検証されています。
実験では、GPT-4やClaudeなどの最新モデルを含む複数のLLMに対してテストを実施しました。その結果、GPT-4が他のモデルよりも高い性能を示しましたが、回答精度が必ずしも十分ではないことが判明しました。特に、計算が必要な直線距離や方角の推定、複数の情報源を統合した判断などでは、多くのモデルが課題に直面しています。これを補うために、計算機能を統合して改良を試みた結果、計算関連タスクでの性能向上が見られました。
図表の解説
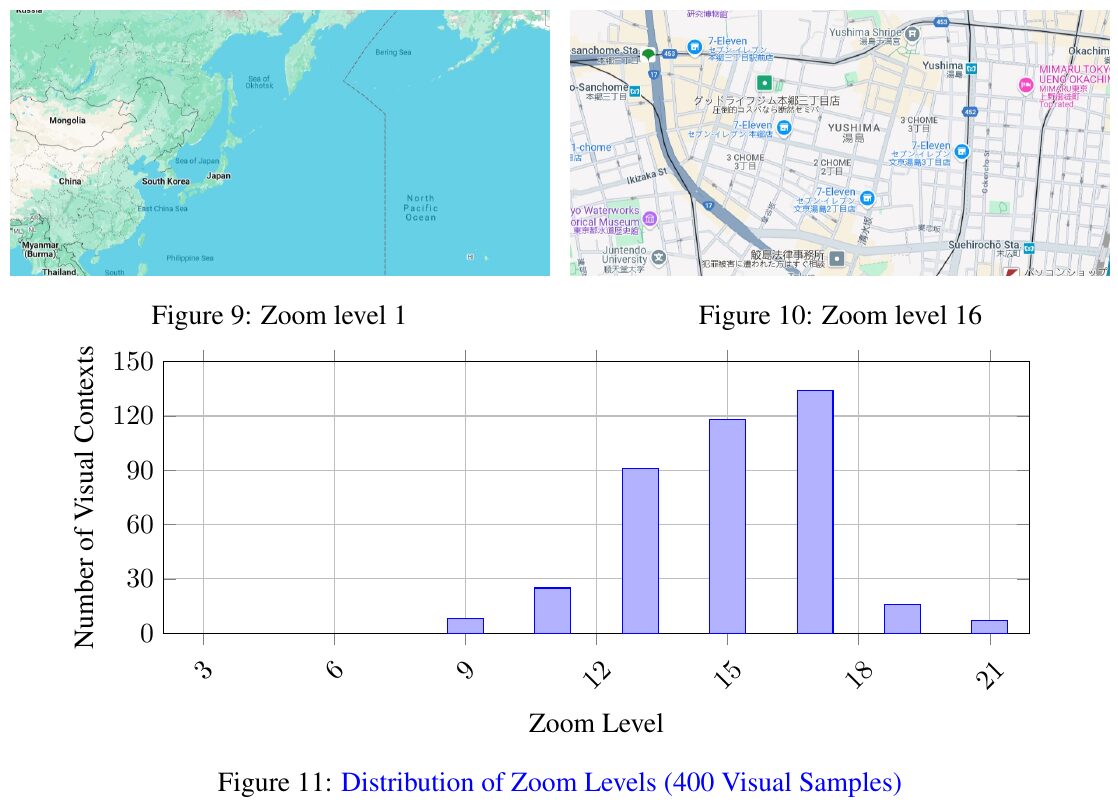
この画像は、ズームレベルに基づく視覚的なコンテキストの分布を示しています。図9は広範囲をカバーするズームレベル1の地図を、図10は詳細情報が表示されるズームレベル16の地図を示しています。図11では、これらのズームレベルが400のサンプルでどのように分布しているかをグラフ化しています。多くの視覚的なコンテキストがズームレベル15から18に集中していることが読み取れます。これは、詳細な地図情報が研究において重要であることを示しています。
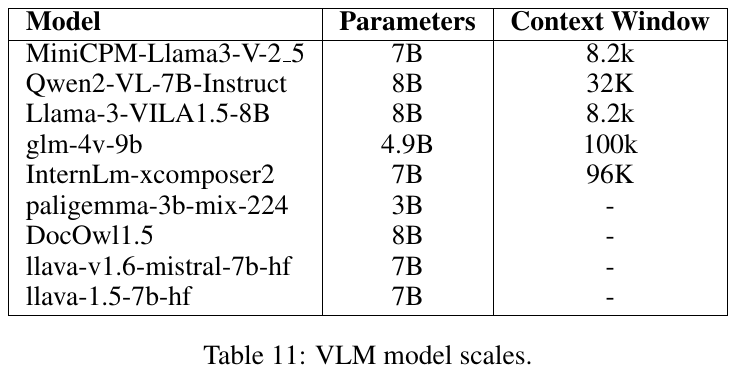
この図は、地理空間的推理を評価するためのベンチマーク「MAPEVAL」に関する統計データを示しています。700のユニークな質問があり、その中で57.14%が視覚コンテキストを利用しています。テキストコンテキストの平均長さは約436語で、最大1500語です。質問の選択肢は平均4つで、ズームレベルは平均15.26で変動します。これにより、AIモデルの地理的な推論性能が評価されます。
この画像は、視覚言語モデル(VLM)のスケールを示した表です。各モデルの名前、パラメータの数、コンテキストウィンドウのサイズが示されています。パラメータの数は、モデルの容量や複雑さを表し、コンテキストウィンドウはモデルが一度に処理できるテキストの長さを示しています。この表を通じて、各モデルの特徴や性能の違いを比較することができます。例えば、glm-4v-9bは小規模なパラメータ数ですが、非常に長いコンテキストウィンドウを持っています。

この図は、論文「MAPEVAL」におけるカテゴリ別統計を示しています。図は2つの主要なタスク、視覚タスク(赤)とテキスト/APIタスク(青)に分けられ、それぞれの割合が円グラフで表されています。具体的には、視覚タスクでは「Place Info」(17.29%)や「Nearby」(13%)などがあります。一方、テキスト/APIタスクでは「Trip」(9.57%)や「Routing」(9.43%)といったカテゴリが含まれています。この図は、各カテゴリの割合を視覚的に示し、MAPEVALの多様性とリアリズムを強調しています。
この図は、地理空間推論の能力を評価するための「MAPEVAL」を使った言語モデルの性能を示しています。表には、モデルの種類に応じた全体的な正確さやカテゴリーごとの正確さが示されています。クローズドソースのモデルがオープンソースモデルよりも全体的に優れていることがわかります。特に「場所情報」や「近く」のカテゴリーでの成績が良い一方、「旅行」や「答えられない質問」には課題が残っています。また、図では人間のパフォーマンスが全体的にモデルより優れていることが示されており、AIモデルの改善が必要とされています。
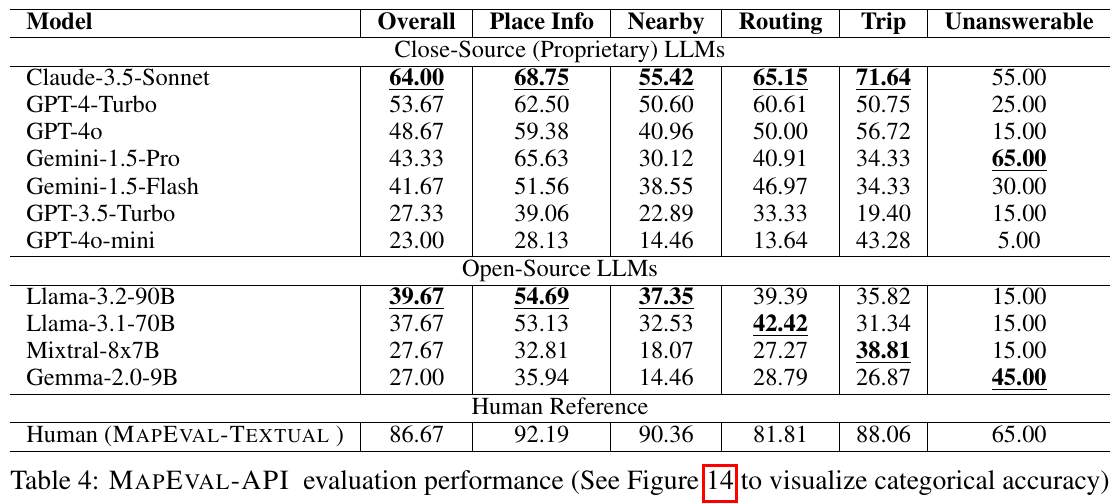
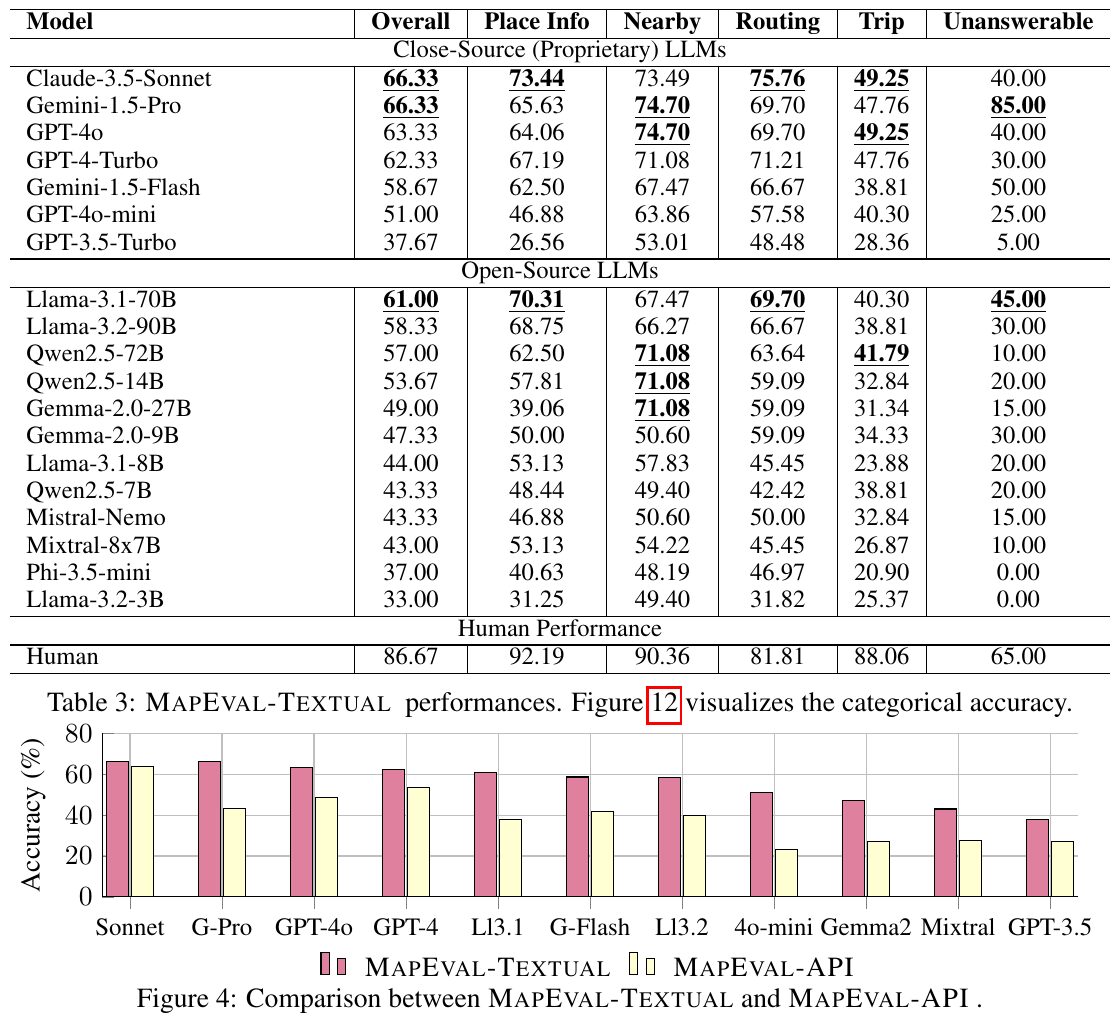
この表は、地図に基づいた評価ベンチマーク「MAPEVAL」での様々なモデルの性能を示しています。閉鎖型LLMは概して開放型よりも高い性能を示しました。特に「Claude-3.5-Sonnet」は全体的に優れた性能を達成しましたが、人間の基準にはまだ達していません。タスクごとに見ると、「Place Info」や「Routing」ではモデルの性能が良好である一方、「Trip」などの複雑なタスクでは苦戦しています。このことは、地図上の複雑な推論が現在のモデルの限界であることを示しています。
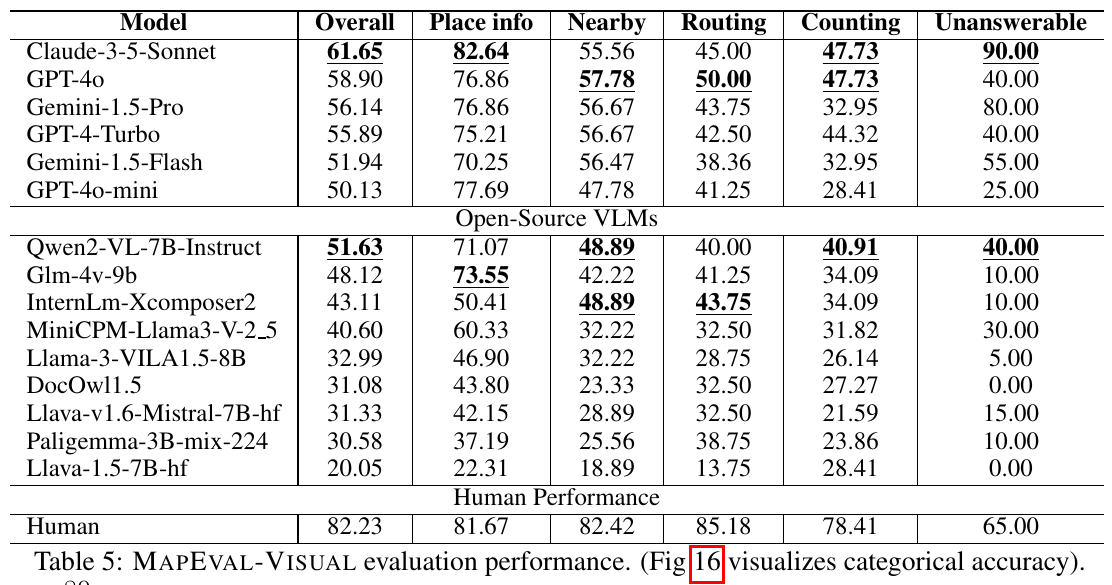
この表は論文におけるMAPEVAL-VISUAL評価の結果を示しています。表には、各モデルの地理的推論能力を評価するために「Overall/Place info/Nearby/Routing/Counting/Unanswerable」の6つのカテゴリでのスコアが記載されています。最も高いスコアは「Claude-3-5-Sonnet」の「Overall」で、61.65%です。「Human Performance」ではすべてのカテゴリで人間の方が良い成績を収めており、AIモデルと人間の性能差が明確です。この結果から地図情報の理解においてAIがまだ改善の余地があることがわかります。
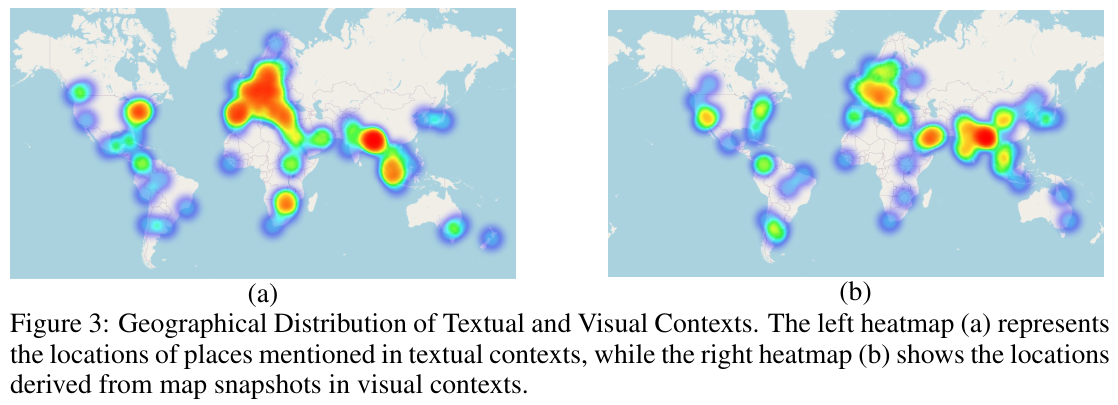
この図は、文章と視覚的なコンテキストの地理的分布を示しています。左側のヒートマップ (a) は、文章コンテキストで言及された場所の位置を示し、右側のヒートマップ (b) は、視覚的なコンテキストにおける地図のスナップショットから得られた場所を示しています。これにより、どの地域がよく言及され分析されているかが視覚的にわかります。これらは、地理的概念を理解し処理するためのモデルの能力を評価する目的で使用されます。