- 再構成と生成のバランスを改善するVF Lossの提案
- LightDiffusionDTモデルによりトレーニング収束速度を約2.5倍向上
- 生成性能と計算コストのトレードオフを効果的に解消した手法
論文:Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この論文では、「Latent Diffusion Models(LDM)」における再構成と生成のトレードオフ問題を解決するための新しいアプローチが提案されています。LDMは画像生成において幅広く使用されていますが、高次元の潜在空間におけるデータ表現の最適化が難しく、再構成性能と生成性能のバランスを取ることが課題となっていました。
著者らはこの問題を解決するため、「VAEs」(Variational Autoencoders)で用いられる再構成損失を改良し、新たに「VF Loss(基礎モデルに基づく再構成損失)」を導入しました。この損失関数では、基礎モデルを活用して潜在表現を高精度に調整しつつ、計算効率を向上させます。また、提案する損失関数はトークナイザーをカスタマイズすることで、再構成と生成のバランスを劇的に改善しました。
さらに、「Diffusion Transformers(DT)」に基づいてモデルアーキテクチャを改良した「LightDiffusionDT」を提案しています。このモデルはVF Lossと組み合わせることで、生成タスクにおいて優れた性能を発揮し、トレーニング収束速度を約2.5倍向上させることに成功しました。実験では、提案モデルが従来のLDMと比較して、生成画像の品質指標「FID」や「PSNR」で大幅な性能向上を示しています。例えば、ImageNet-256データセットでは、新しいLightDiffusionDTがわずか64エポックで高い再構成性能を達成しました。
この研究の重要な成果は、提案手法が生成性能と計算コストのトレードオフを効果的に解消しつつ、短いトレーニング時間での収束を可能にした点です。これにより、幅広い応用タスクでの実用性が示されました。
図表の解説
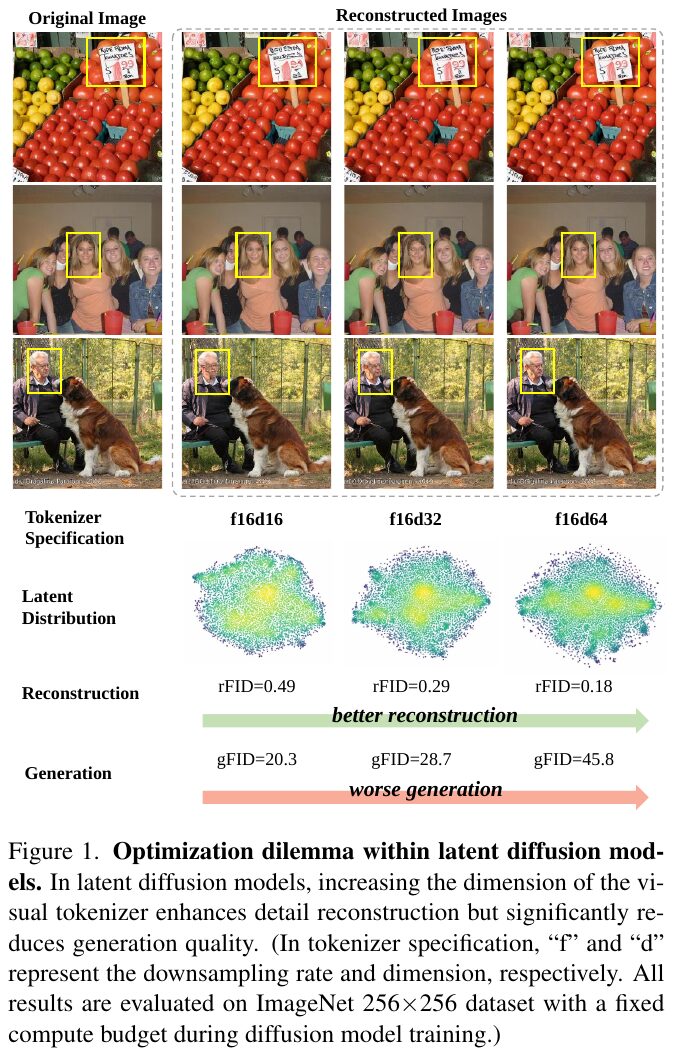
この画像は、潜在拡散モデルのトークナイザーの次元が再構築と生成にどのように影響するかを示しています。オリジナル画像からの再構築品質がトークナイザーの次元を増加させると改善されますが、生成品質は低下します。図では、異なるトークナイザー仕様(f16d16, f16d32, f16d64)について、再構築(rFID)と生成(gFID)の性能を示しています。簡単に言えば、再構築と生成のバランスを取るのが難しいという課題を表しています。
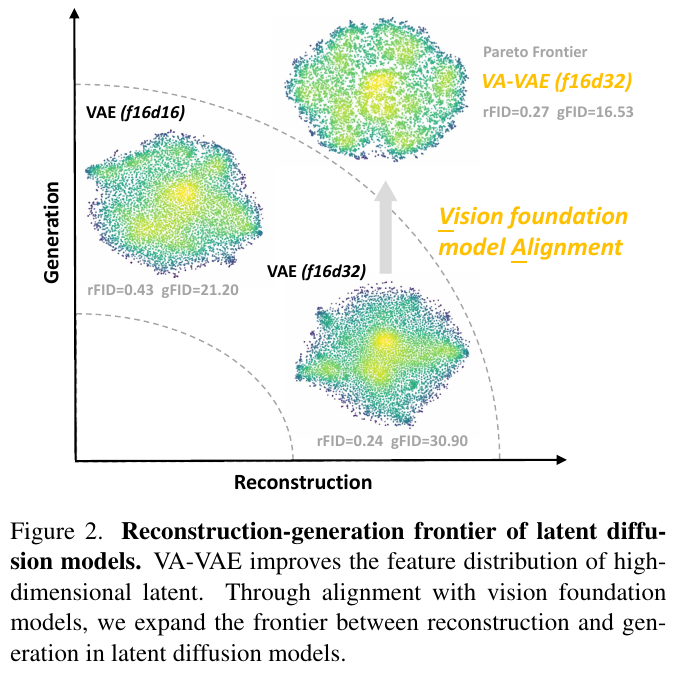
この図は、潜在拡散モデルにおける再構成と生成のバランスの概念を示しています。図中には、異なるVAEモデルが3つのグラフで描かれており、それぞれが潜在空間での機能の分布を表しています。VAE (f16d16) と VAE (f16d32) は、それぞれ異なる次元を持つトークナイザーを使用しており、その結果は生成と再構成の品質に影響を与えます。VA-VAE (f16d32) は、視覚基盤モデルと整合することによって、より優れた生成性能を達成しています。図の矢印は、視覚基盤モデルを用いて、再構成と生成の前面を拡大するプロセスを示しています。これにより、高次元潜在空間での特徴分布が改善され、モデルの生成能力が向上することが示されています。
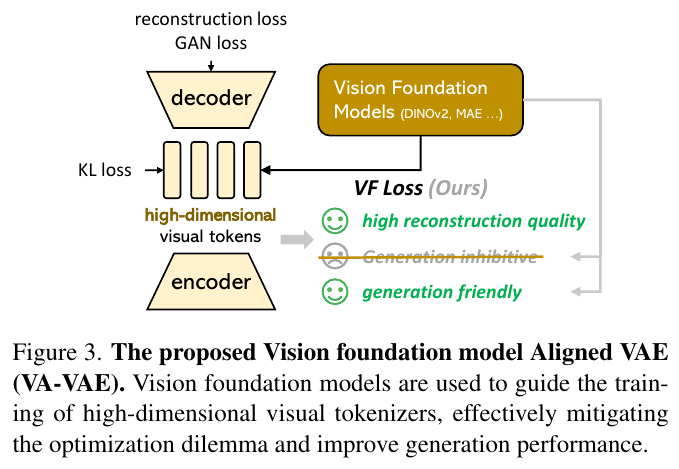
この図は、新しい視覚基盤モデルであるVA-VAEの概念を示しています。このモデルは、視覚基盤モデル(DINOv2やMAEなど)を用いて高次元ビジュアルトークナイザーの訓練をガイドすることで、最適化のジレンマを軽減し、生成性能を向上させます。具体的には、復元の質を高めつつ、生成を妨げない調整を行うことで、より良い画像生成を実現します。この手法により、復元と生成の両方の性能を改善し、効率的なトレーニングを可能にしています。
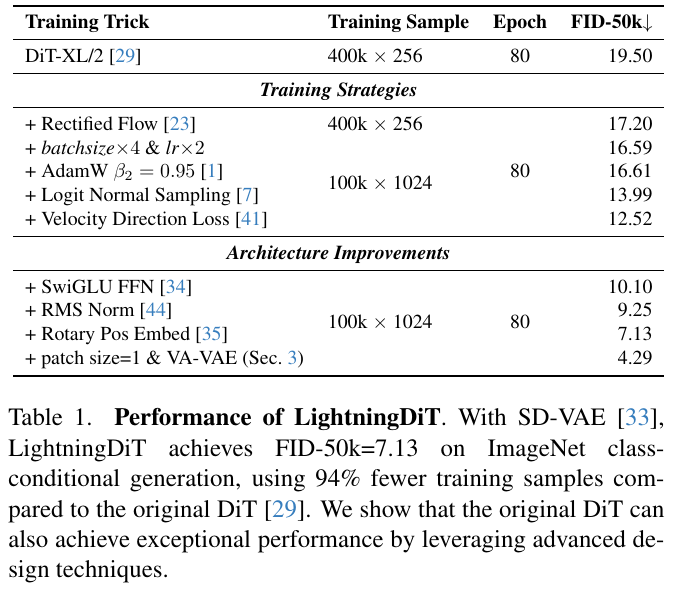
表に示されているのは、LightningDiTの性能です。SD-VAEを使用して、ImageNetクラス条件生成でFID-50k=7.13を達成しています。これは、元のDiTと比べて94%少ない学習サンプル数で済んでいます。表では、さまざまな学習戦略やアーキテクチャの改善がどのようにFIDを低下させ、生成性能を向上させたかを示しています。特に、VA-VAEの導入が大きな効果をもたらしています。
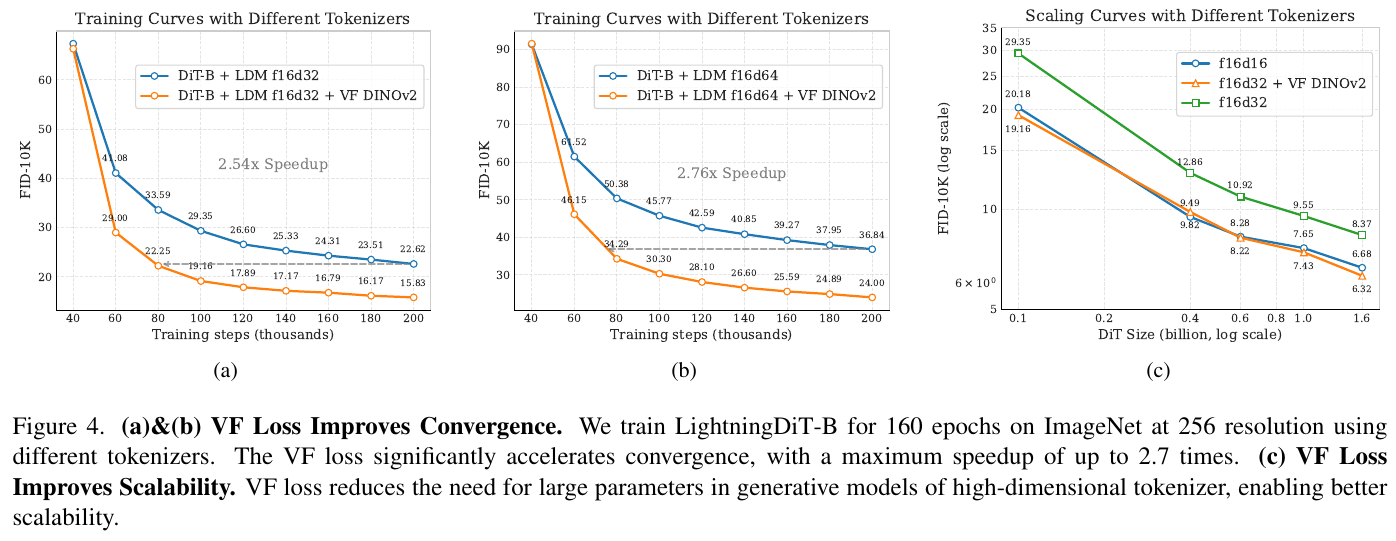
この図は、VF Lossがトークナイザの学習でどのように収束を改善するかを示しています。図の(a)と(b)では、VF Lossを使用した場合、学習の収束速度が2.54倍から2.76倍速くなることがわかります。図の(c)は、VF Lossが高次元トークナイザの生成モデルでの大規模パラメータの必要性を減らし、スケーラビリティを向上させることを示しています。全体として、VF Lossは学習の効率化とパフォーマンス向上に寄与します。
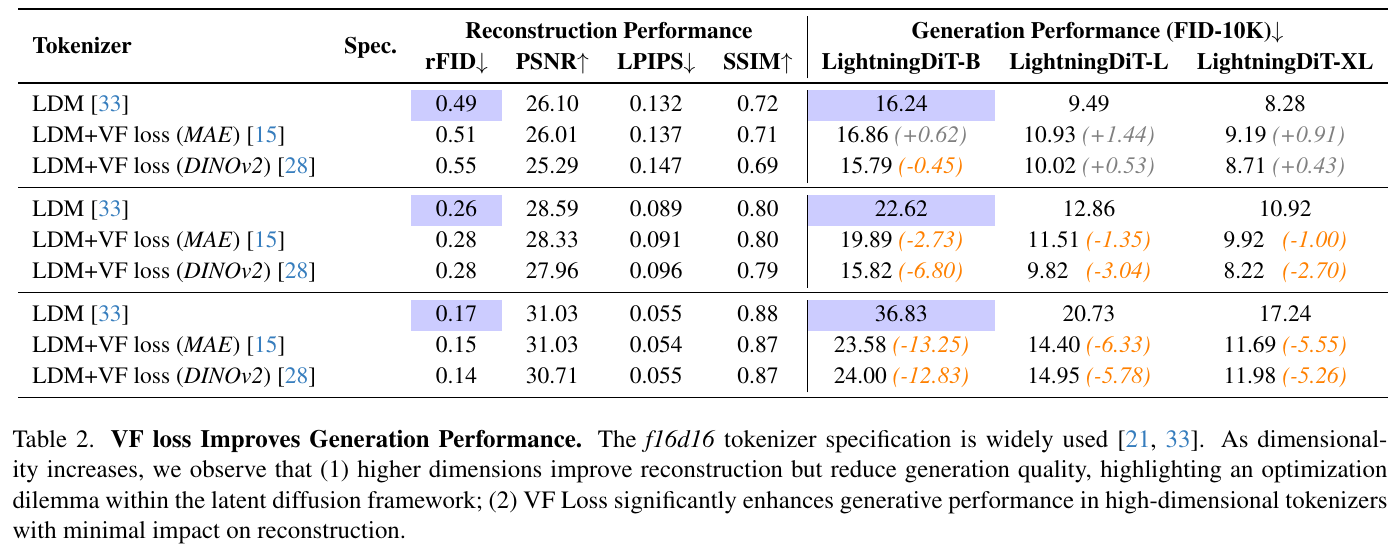
この図は、異なるトークナイザが再構築性能と生成性能にどのように影響を与えるかを示しています。トークナイザの次元を増やすと再構築性能(rFIDが低くなる)が改善されますが、生成性能(FIDが高くなる)が低下することが確認できます。しかし、「VF Loss」を導入することで、高次元トークナイザでも生成性能を大幅に向上させ、再構築性能への影響を最小限に抑えています。これにより、再構築と生成のバランスをより良く保てることが示されています。
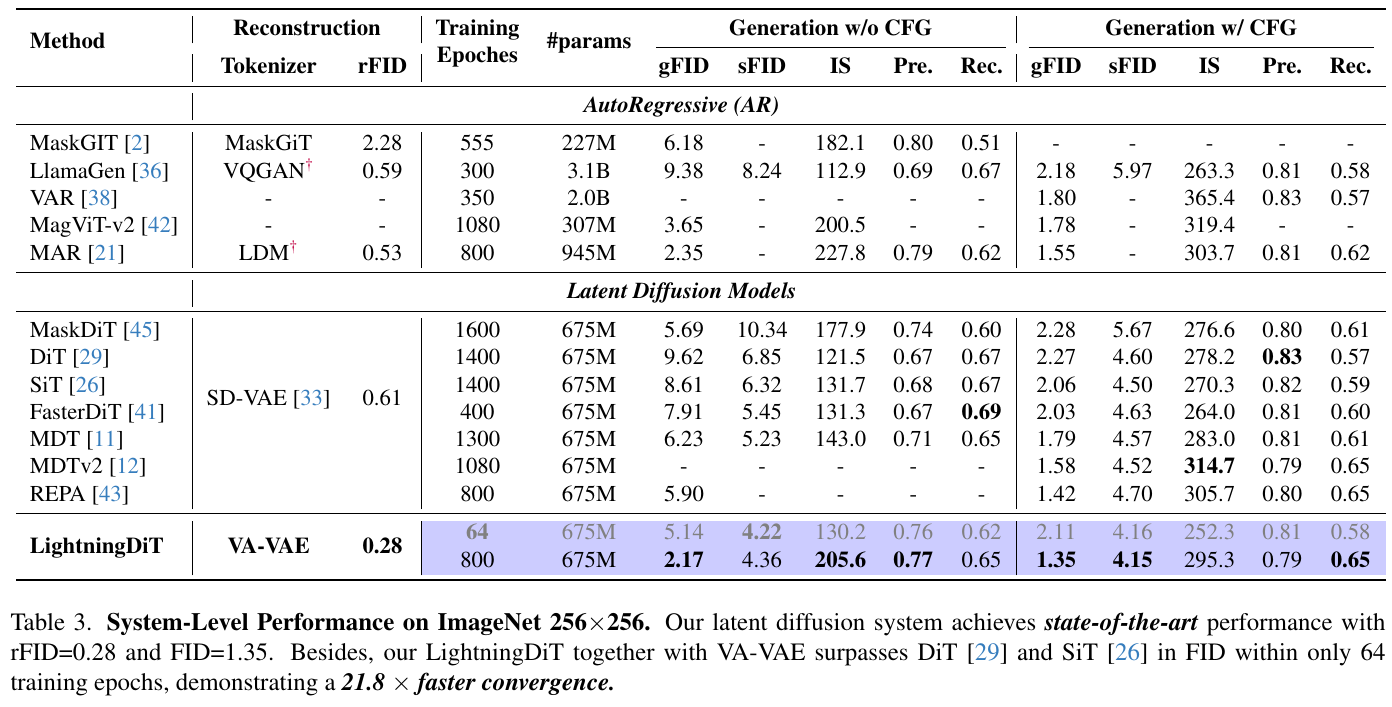
論文の図は、画像生成モデルの性能比較を示しています。表は、さまざまな手法の再構成品質(rFID)、生成品質(gFID)、および学習の効率性を比較しています。特に、LightningDiTと呼ばれる新しいモデルが注目されており、わずか64エポックで優れた性能を達成し、既存の手法よりも高速に収束しています。このモデルはVA-VAEと組み合わせて使用され、再構成と生成の両面で優れた性能を発揮しています。
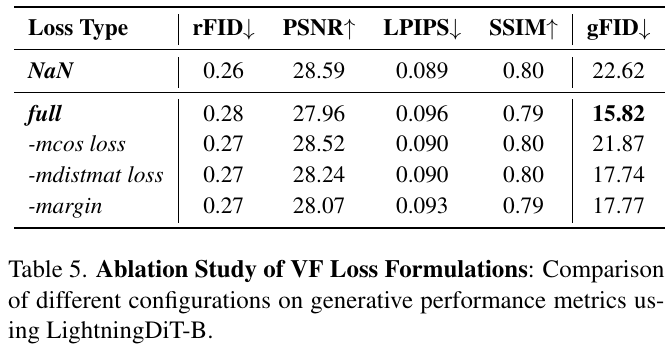
この表は、異なる損失構成が生成性能に与える影響を示しています。具体的には、VF損失の各成分を除いた場合の比較をしています。表の中で、「full」は全ての損失成分を含む構成を指し、他の行はそれぞれの成分を削除した結果を示しています。「gFID」が特に低い場合は、生成品質が優れていることを示します。この結果から、「full」構成が最も良い生成性能(最小のgFID値=15.82)を示したことが分かります。これは、全ての成分を含むVF損失が最も効果的であることを意味します。