- ソフトウェアエンジニアリングタスクをシミュレーションする学習環境「SWE-Gym」
- Transformerを利用したモデルによる精度の高いコード修正アプローチを開発
- オープンソースとして公開され、研究者や開発者が利用可能な環境
論文:Training Software Engineering Agents and Verifiers with SWE-Gym
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この論文では、ソフトウェアエンジニアリングのタスク用に設計された新しい学習環境「SWE-Gym」を提案しています。SWE-Gymは、コードの修正やテストといった実践的なソフトウェアエンジニアリングタスクをシミュレーションし、エージェントが適切な解決策を生成できるような場を提供します。また、この環境には生成されたコードを評価するベリファイア(検証者)の育成も含まれています。
著者らは、SWE-Gymを通じてTransformerを利用したモデルを訓練し、以下のような成果を報告しています。まず、精度の高いコード修正タスクを実現する新たなアプローチを開発しました。次に、データのスケーリング戦略や特殊なプロンプト設計により、パフォーマンスをさらに向上させる手法を検討しました。これには、適切なトレーニングデータの選定と分散処理技術の活用が含まれます。
実験では、複数のベンチマークを用いて標準的な修正タスクをテストしました。特に、エラーレートの低下とタスク解決速度の向上が確認されています。また、ベリファイアについては、修正コードの品質や正確性を判定する精度が高く、従来のアプローチを上回る結果が得られました。
さらに、SWE-Gymの環境はオープンソースとして公開されており、研究者や開発者がこれを基盤にしてエージェントやベリファイアのさらなる開発を進められる設計になっています。
図表の解説
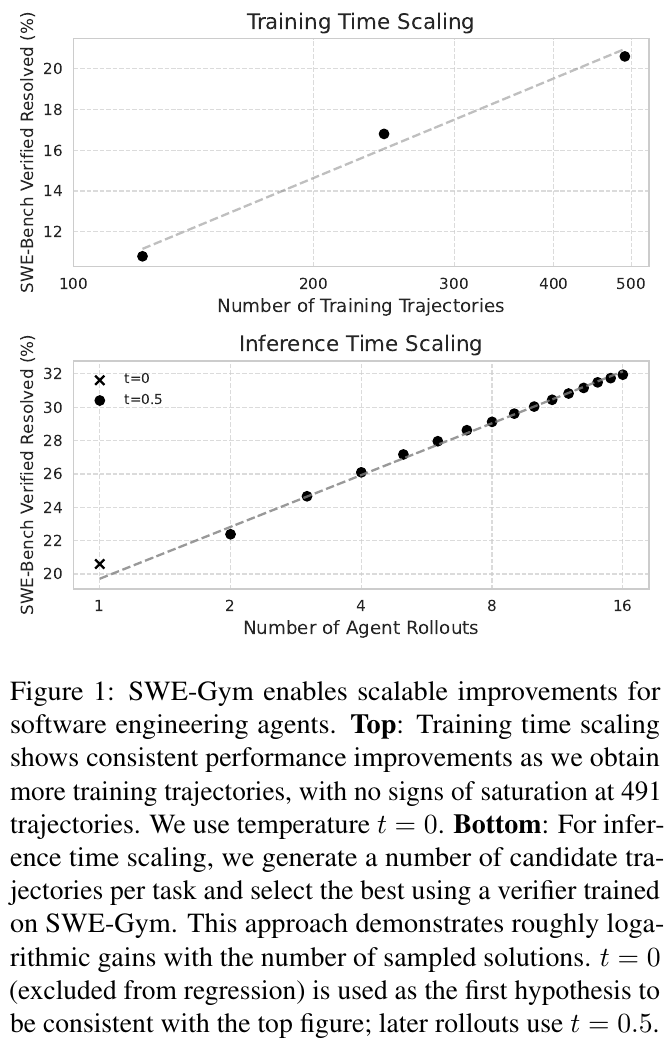
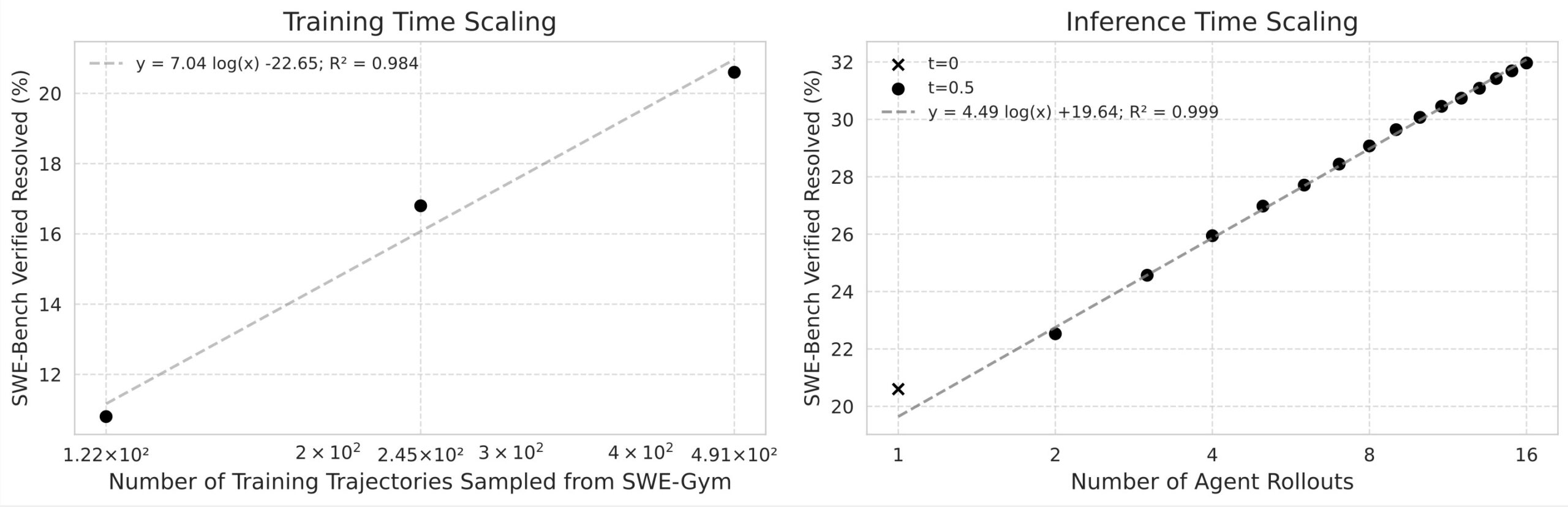
この図は、SWE-Gymの性能スケーリングに関するものです。上のグラフは、「トレーニング時間のスケーリング」で、訓練トラジェクトリーの数が増えると、解決率が向上し続けることを示しています。下のグラフは、「推論時間のスケーリング」で、エージェントのロールアウト数が増えるにつれて、約対数的に解決率が改善することを示しています。この結果は、SWE-Gymがソフトウェアエージェントの性能向上に役立つことを示しています。
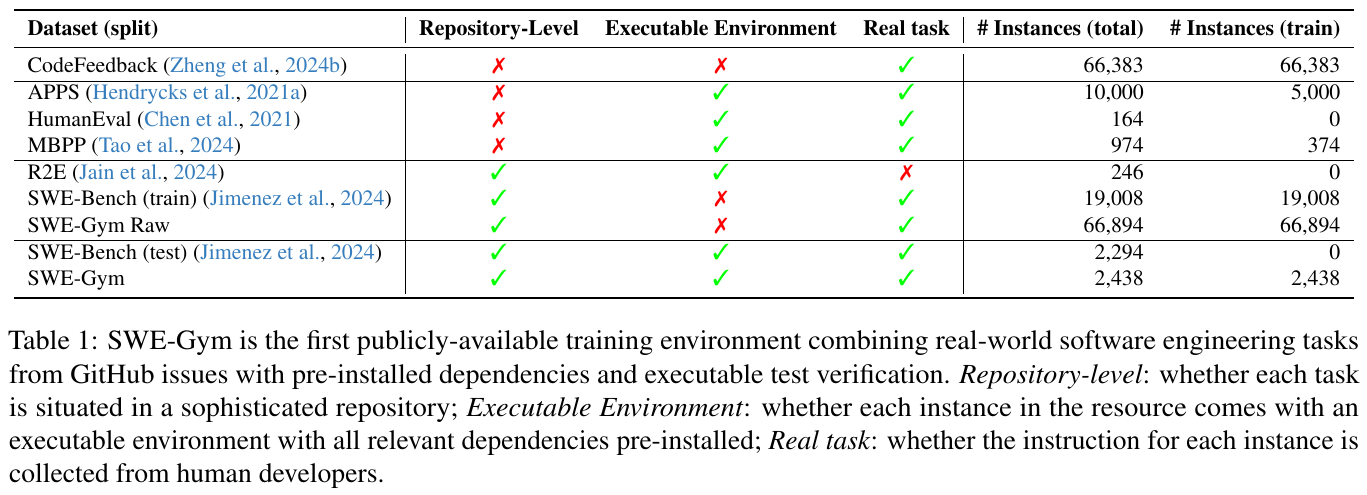
この図は、SWE-Gymの特性を他のデータセットと比較して示しています。各データセットが「リポジトリレベル」「実行可能な環境」「実際のタスク」の特徴を有するかをチェックしています。
特に、SWE-Gymは実行環境が整ったリポジトリレベルのタスクを含む初の公開データセットで、データはGitHubの人間開発者の指示から収集されています。
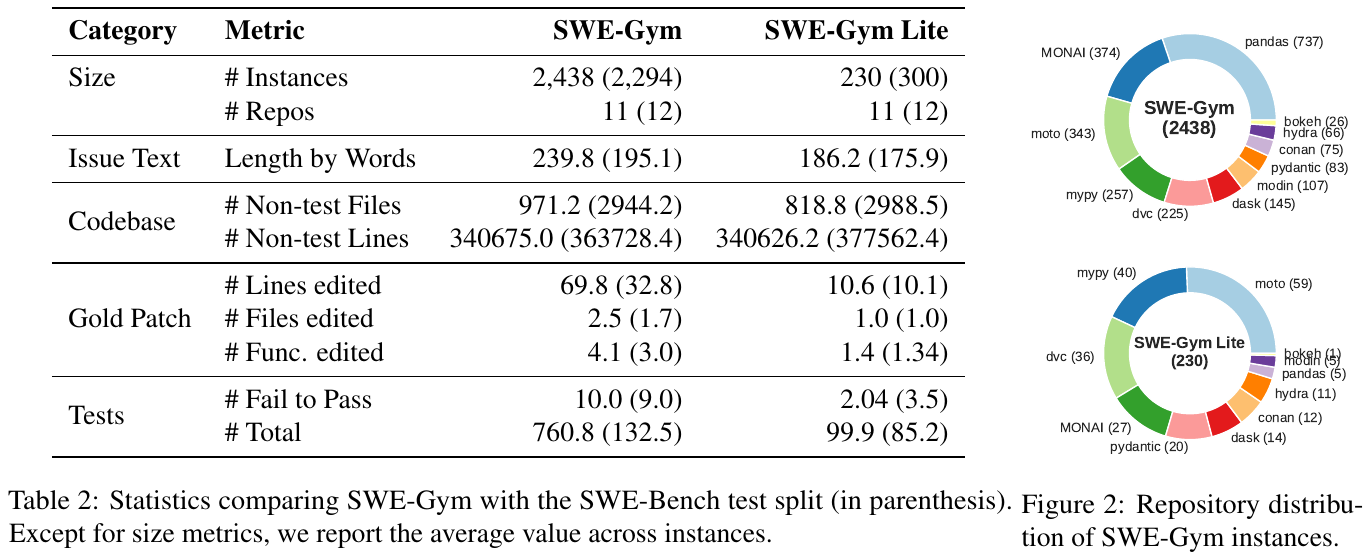
この図は「SWE-Gym」と「SWE-Gym Lite」という2つのデータセットの統計情報を示しています。
SWE-Gymは2,438のインスタンスを持ち、11のリポジトリから構成されています。
SWE-Gym Liteは230のインスタンスで構成され、同じく11のリポジトリが含まれます。表には、問題のテキストの長さやコードベースのファイル数、編集された行数やテストの数などが記載されています。右側の円グラフは、これらのインスタンスがどのリポジトリにどれだけ含まれるかを示しています。
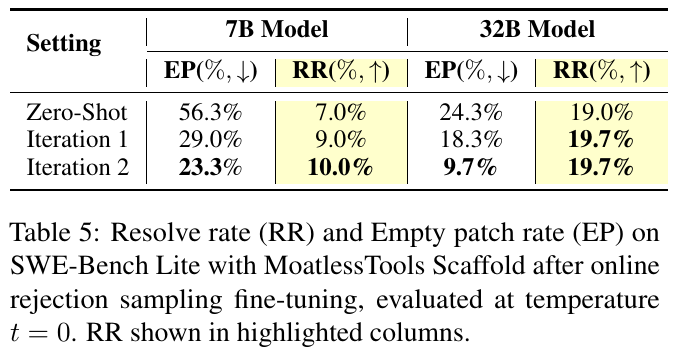
この表は、7Bと32Bモデルの2つのサイズ設定で、MoatlessTools Scaffoldを用いたSWE-Bench Liteの状況を示しています。各設定での空白パッチ率(EP)と解決率(RR)が測定されました。結果として、7Bモデルでは、空白パッチ率が減少し、解決率が7.0%から10.0%に向上しました。32Bモデルでは最初の反復後に解決率が19.7%に達し、安定しています。この表は、オンライン拒否サンプリングを用いた微調整の効果を示しています。
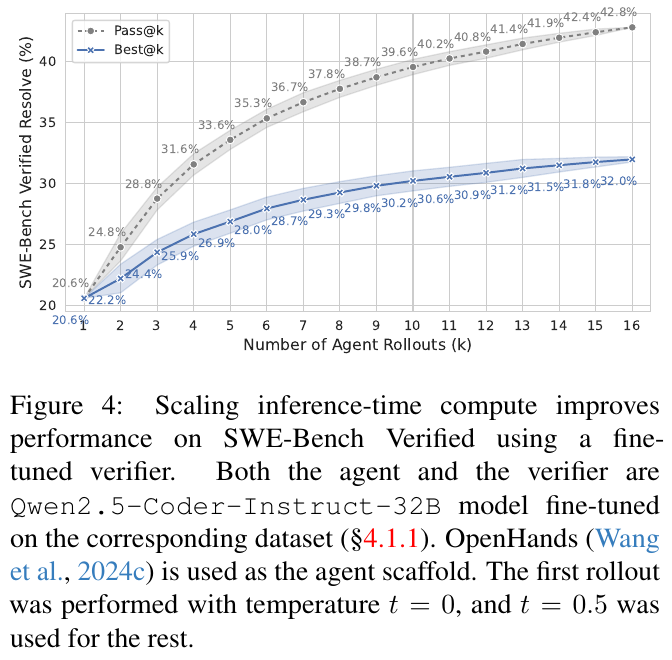
図4は、SWE-Bench Verifiedのパフォーマンス改善における推論時の計算量の拡大の効果を示しています。このグラフは、「Pass@k」(正解解のサンプリング割合)と「Best@k」(最も正しい解の割合)を、モデルが生成するエージェントロールアウトの数に応じてプロットしています。「Pass@k」は20.6%から42.8%に、「Best@k」は20.6%から32.0%に改善しています。エージェントと検証者はQwen2.5-Coder-Instruct-32Bモデルを使用しています。
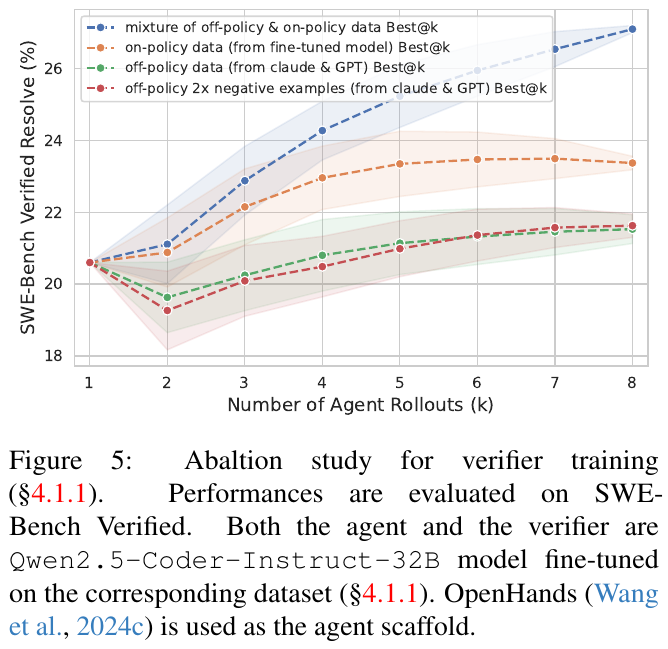
図5は、検証器の訓練方法に関するアブレーションスタディを示しています。このスタディでは、異なるデータセットを用いて訓練された検証器の性能をSWE-Bench Verifiedで評価します。結果として、オフポリシーとオンポリシーのデータ混合による訓練は最も良好な結果を示し、特にk=8までの推移で性能が向上しています。一方、他のデータセットのみを使用した場合は、性能が早期にプラトーに達する傾向が見られました。このことから、多様なデータセットを使用することで、検証器の一般化能力と成功したソリューションの識別精度が向上することが示唆されています。
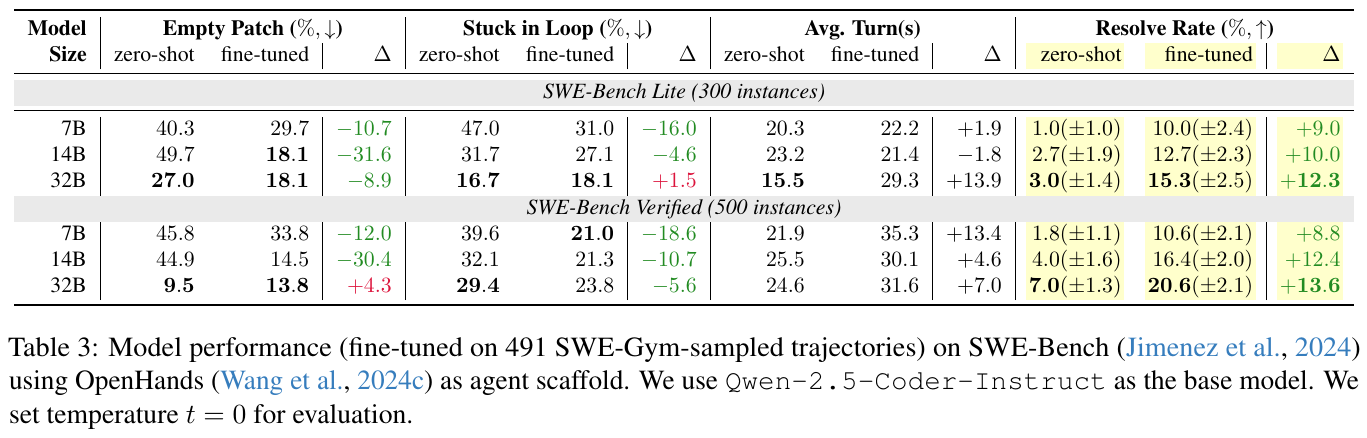
この図は、プログラムの改善において異なるモデルサイズの性能を評価した結果を示しています。SWE-Gymを用いて微調整したモデルが、タスクをどれくらい解決できたかを示しています。表は、モデルのサイズ(7B、14B、32B)が増えるにつれて性能が向上することを示しており、特に「Resolve Rate」(解決率)が顕著に改善しています。この改善は、微調整により「Empty Patch」や「Stuck in Loop」などの失敗率が減少したことに関連しています。微調整は、モデルがより多くのターンを利用して問題を解決する能力を高め、全体として解決率を向上させています。
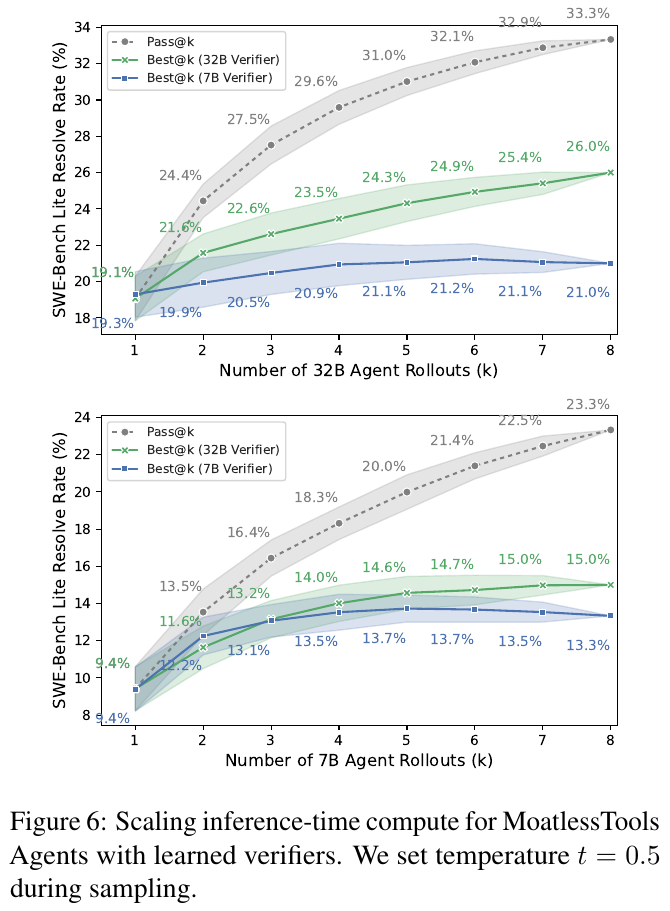
この図は、MoatlessToolsエージェントが学習した検証器と共に使用され、推論時の計算スケールアップを示しています。上のグラフは32Bエージェントによる展開の数に基づく解決率を示し、下のグラフは7Bエージェントによるものです。グラフは、増加する計算リソースに応じて、逐次増大する解決率を示しています。このことは、推論時に複数のソリューションを評価し最良のものを選択することで性能改善が可能であることを意味します。