- ロシア語に特化した大規模言語モデルの改良方法として学習型埋め込み伝播を提案
- 埋め込み空間の整合性を高める技術で未学習領域の性能向上を実現
- 複数のロシア語ベンチマークでの実験で従来技術を上回る性能を確認
論文:Facilitating large language model Russian adaptation with Learned Embedding Propagation
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
本論文では、ロシア語への適応を目的とした大規模言語モデル(LLM)の改良方法「学習型埋め込み伝播(Learned Embedding Propagation: LEP)」が提案されています。この技術は、LLMの埋め込み空間を効率的に調整することで、特定の言語やタスクに特化したモデルを構築するアプローチです。研究者は特に、すでに存在するロシア語データとモデルを活用しつつこの適応を進めることで、計算コストを大幅に削減しています。
提案方法では、まずトークナイゼーションを調整し、次に埋め込みの初期化を行い、最後に改良された埋め込み伝播技術を用いてモデルを適応させます。ここで、埋め込みの調整には他のモデルとの埋め込み空間の整合性を高める技術が利用されます。また、語彙変換を通じて、新たな単語や特徴を学習データに効果的に統合する方法が示されました。これにより、モデルが未学習領域でも適切な回答を生成できる能力が向上します。
実験においては、複数のロシア語ベンチマークでモデル性能を評価し、LEPを適用したモデルが従来技術を上回る成果を示しました。特に、DaruSumやDaruNMTというベンチマーク指標では、生成された応答の正確性や信頼性が向上していることが確認されています。また、モデルの自己校正機能をさらに進化させる実験も行われ、最終的にLEP適用モデルは大規模最先端モデルに匹敵する性能を発揮しました。
この研究は言語適応手法の効率化を目指し、特にロシア語のLLM分野で有望な進展を提供しています。
図表の解説

図1は、提案された適応手法(LEP)をさまざまなモデルに適用し、その性能を比較しています。この結果は、Darumeruベンチマークで評価されています。LEPは、少ないデータで高性能を実現し、さらに自己校正や指示のチューニングを組み合わせることでパフォーマンスが向上しています。特にLLaMa-3-8BやOpenChat 3.5は、この手法で大幅に改善されています。
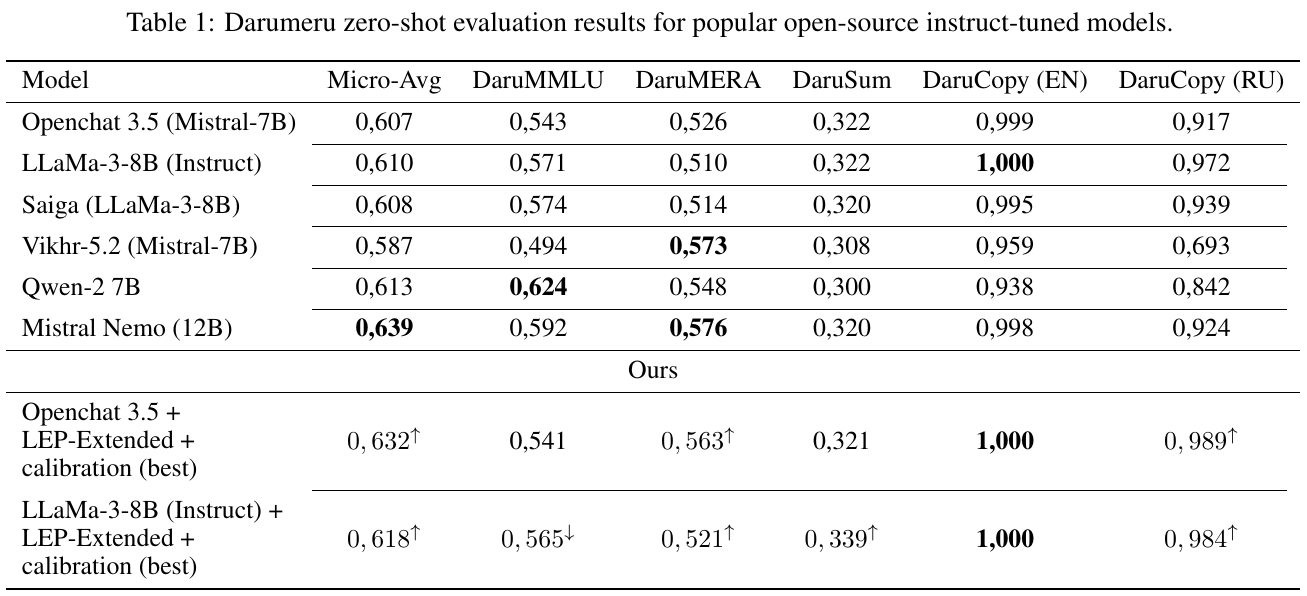
この表は、オープンソースの指示調整された言語モデルの「Darumeru」ベンチマークでのゼロショット評価結果を示しています。主なモデルとしてMistralやLLaMaが挙げられ、「Micro-Avg」や「DaruMMLU」などの指標で性能が比較されています。また、改良を施した独自モデルの結果も示されており、一部の項目で元のモデルを上回っていることが確認できます。
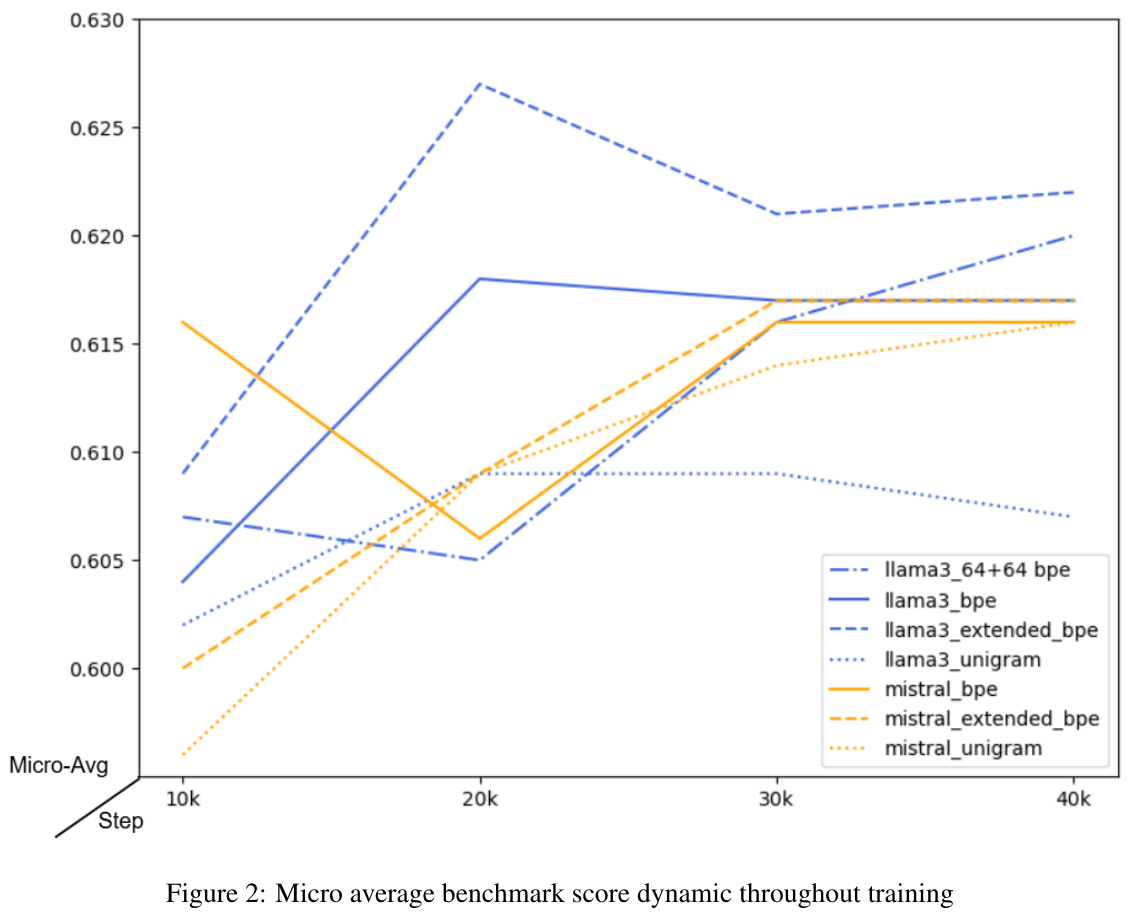
この図は、いくつかのモデル(例えば、llama3とmistral)におけるトレーニング中のマイクロ平均ベンチマークスコアの変化を示しています。トレーニングステップが進むに連れてスコアが上昇する傾向が観察されますが、モデルやトークナイゼーション方法によって進化の仕方が異なります。これは、異なる方法が言語適応にどのように影響を与えるかを評価するために使用されます。
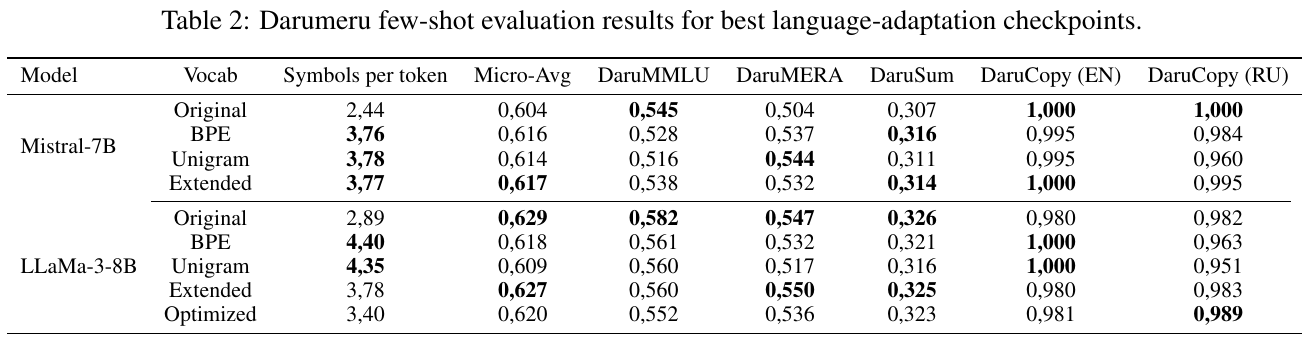
表2は、異なるボキャブラリ設定でのMistral-7BとLLaMa-3-8Bのモデル評価結果を示しています。これらのモデルは、ロシア語への適応能力を持つかどうかを見るためにテストされました。特に、元のボキャブラリと新しいボキャブラリ(BPE、Unigram、Extended、Optimized)を比較しています。各モデルの評価は、トークンあたりの記号数、Micro-Avg、さまざまなタスク(DaruMMLU、DaruMERAなど)のスコアによって行われています。結果からは、新しいボキャブラリがタスクパフォーマンスを向上させることがあるが、モデルやタスクによっては異なる影響があることがわかります。
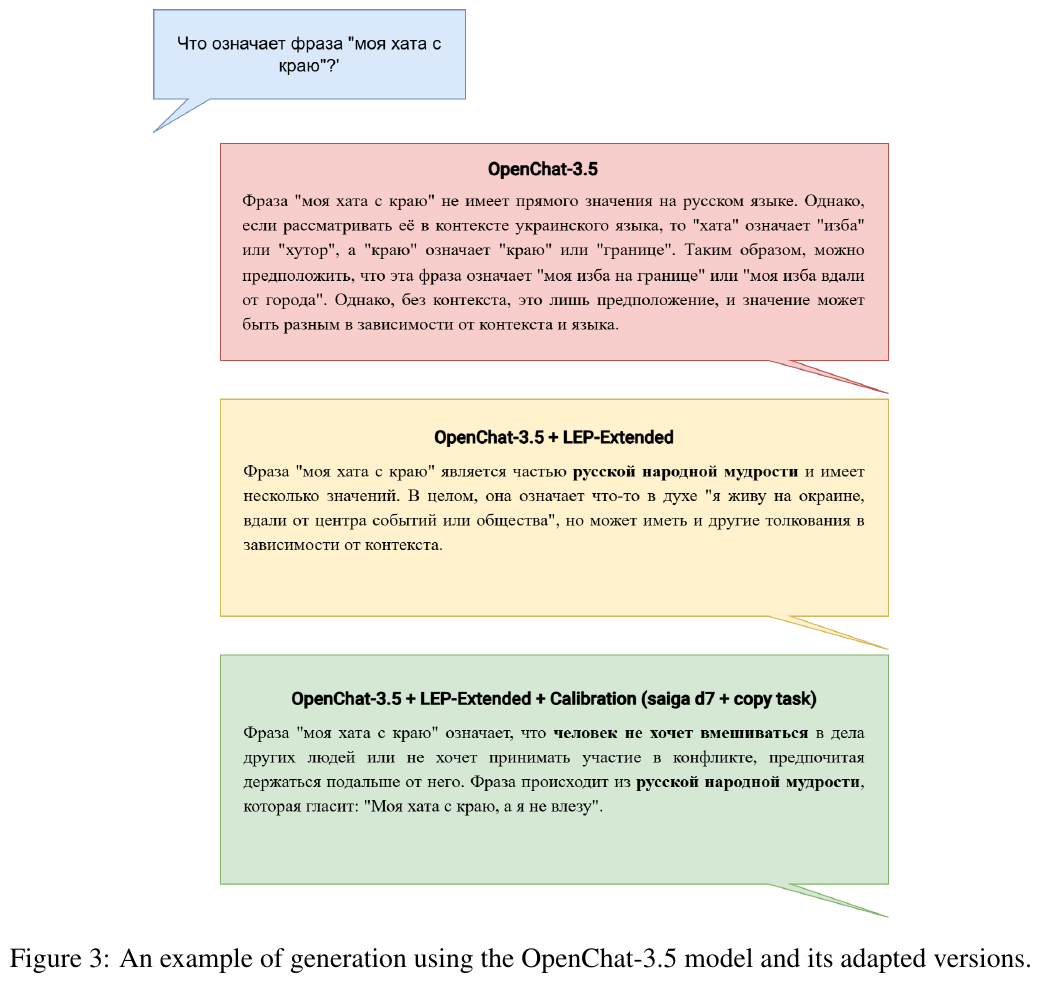
図の意味を簡潔に説明します。 図3は、OpenChat-3.5モデルとその適応バージョンの例を示しています。”моя хата с краю”(”私の家は端にある”)というフレーズの意味を各モデルが生成する方法が説明されています。最初のバージョンは字義通りに捉え、次のバージョンでは文脈的な意味を考慮し、最終的なバージョンはことわざ的な深い意味をうまく解釈しています。これは各モデルの理解力と文脈処理能力の違いを示しています。
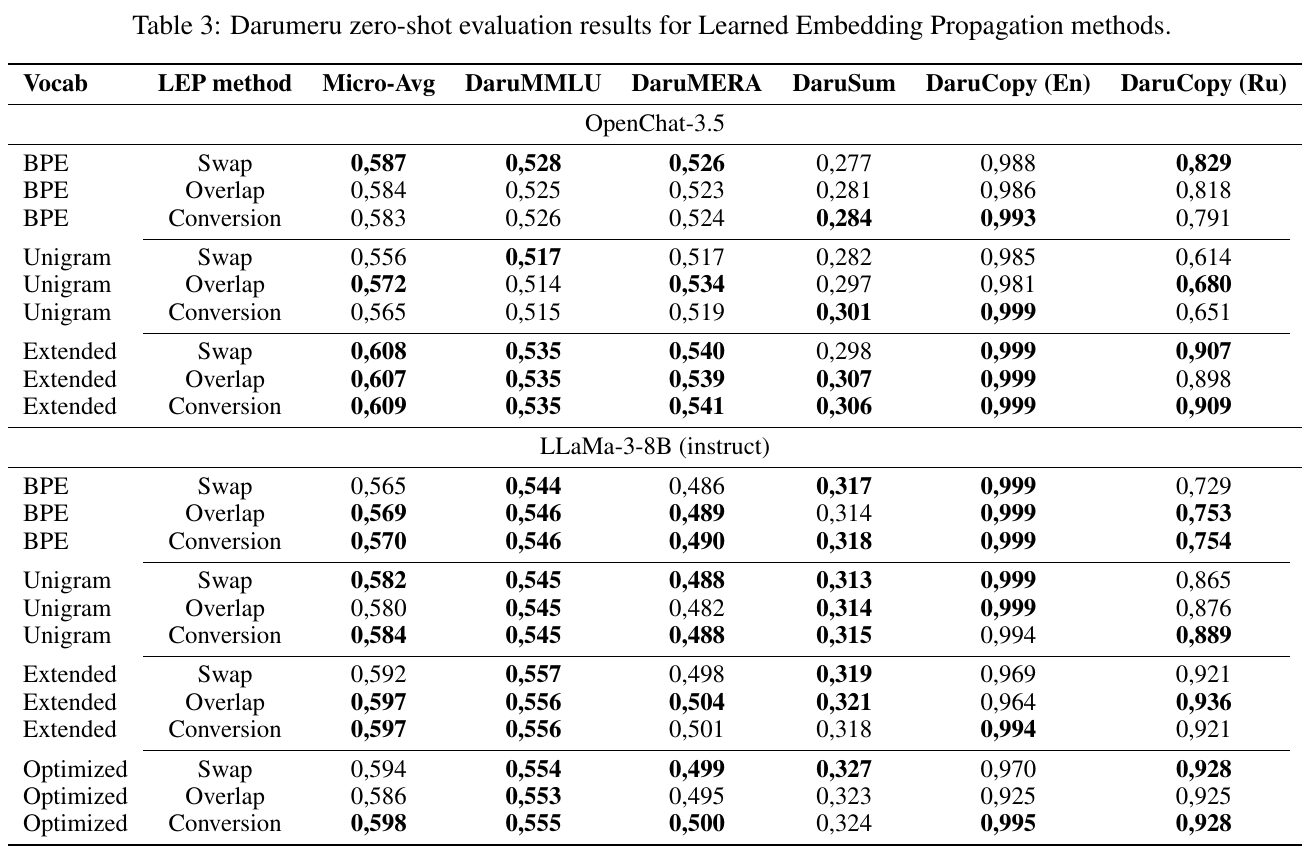
この表は、学習した埋め込み伝搬(LEP)法を用いてロシア語適応を行った際の「Darumeru」ゼロショット評価結果を示しています。使用したボキャブラリ(BPE、Unigram、Extended、Optimized)と埋め込み方法(Swap、Overlap、Conversion)が評価され、さまざまなタスク(DaruMMLU、DaruMERA、DaruSum、DaruCopyなど)でのパフォーマンスを数値化しています。高い数値が示された方法は特に有効であることを示しています。結果として、ボキャブラリ拡張(Extended)が特に優れていることがわかります。
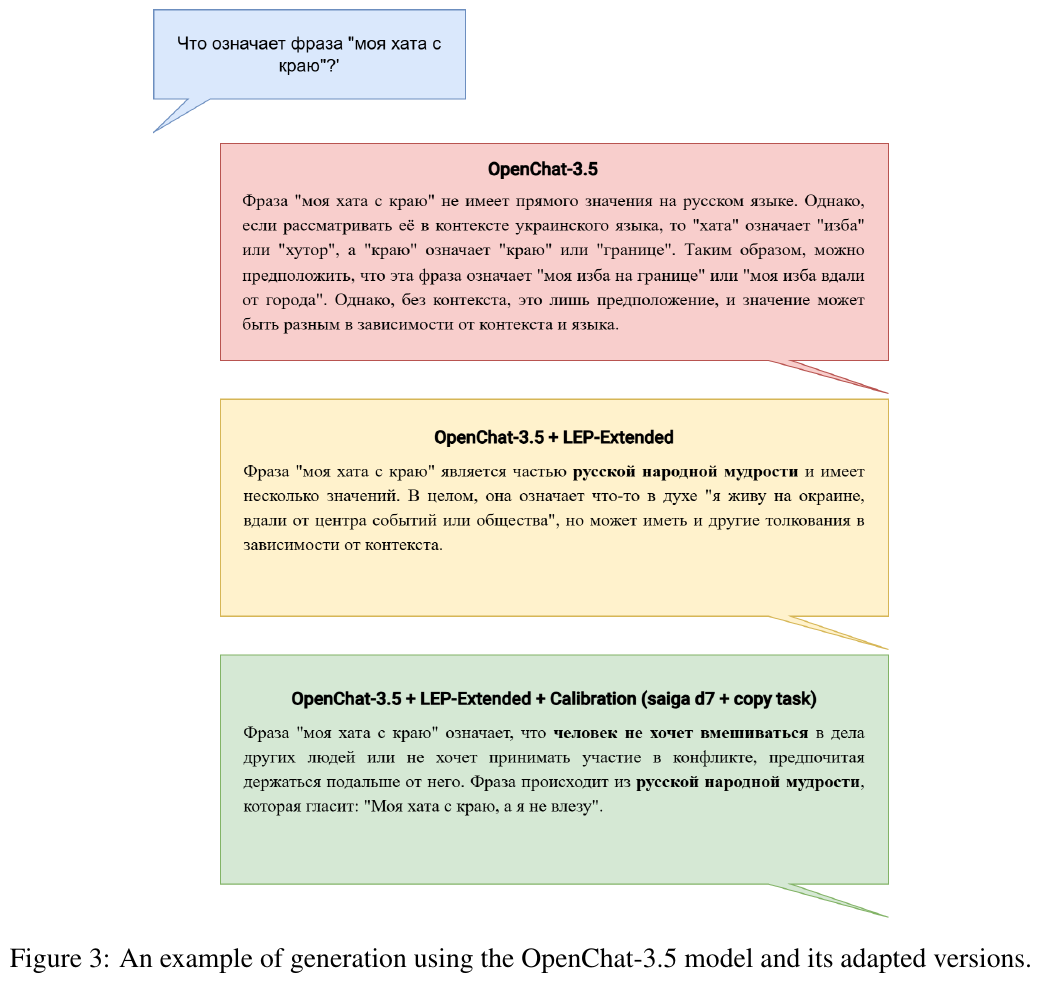
図は、「моя хата с краю」(私の家は端にある)というフレーズの異なる生成結果を示しています。
- OpenChat-3.5:直接的な意味がないとしており、文脈や言語によって解釈が変わる可能性があると述べています。
- OpenChat-3.5 + LEP-Extended:ロシアのことわざの一部であり、中心から離れているニュアンスを持つと評価しています。
- OpenChat-3.5 + LEP-Extended + Calibration:誰にも関与しないことを表しており、本来の意味に忠実であるとしています。
このように、モデルのバージョンによって解釈が微妙に異なることが示されています。
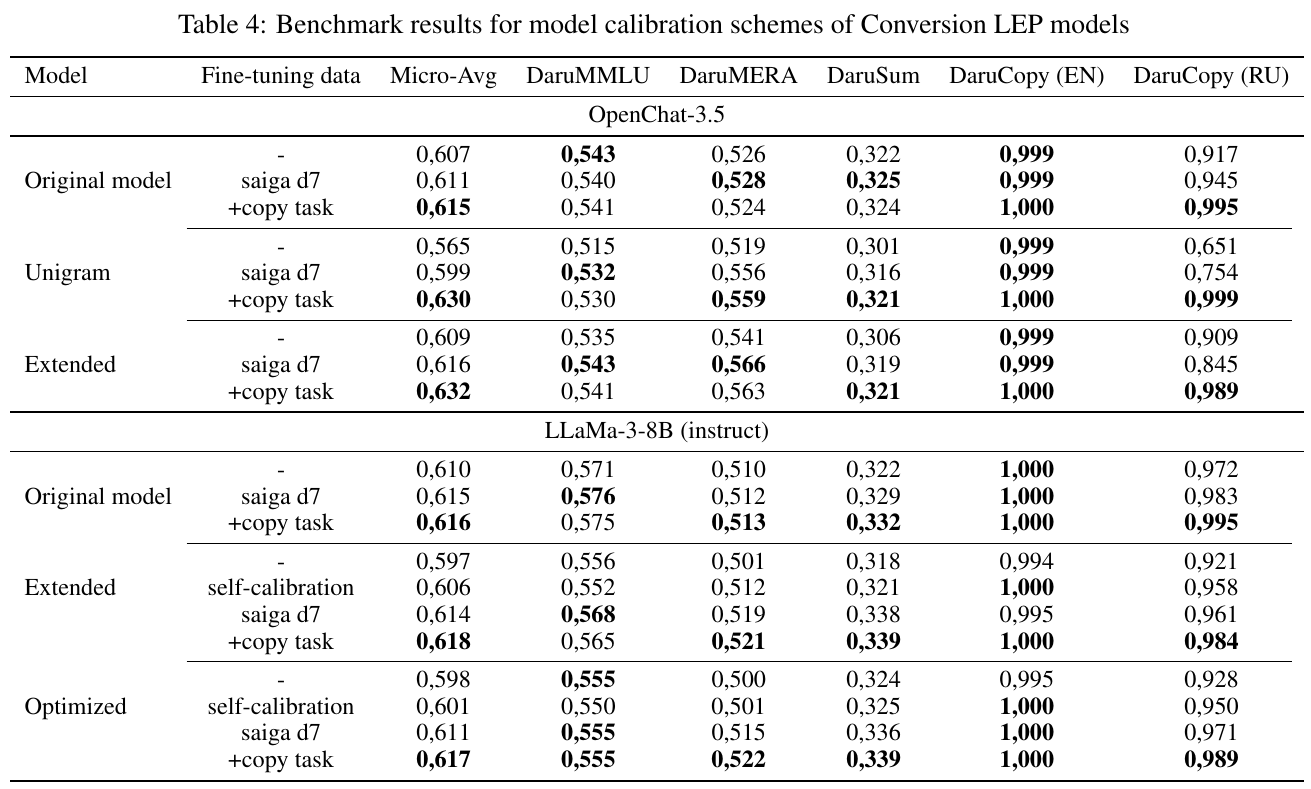
この表は、Conversion LEPモデルのさまざまなキャリブレーション方式のベンチマーク結果を示しています。OpenChat-3.5とLLaMa-3-8Bの2つのモデルについて、異なる語彙適応とファインチューニングデータの有無での性能を評価しています。
特に、コピータスクを加えることで全体的なマイクロ平均スコアが向上することが示されています。これは、与えられたデータセットと追加のタスクがモデルの性能にどのように影響するかを分析するために用いられます。