
この論文では、テキストから音声を生成する「EzAudio」という新しいモデルを提案しています。従来のモデルが抱えていた品質や計算コストの課題を克服するため、1次元の波形データを利用した効率的なTransformerモデルを開発し、計算コストを削減しながらも高品質な音声生成が可能となり、他のオープンソースモデルを上回る性能を示しています。
論文:EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
Project Page:https://haidog-yaqub.github.io/EzAudio-Page/
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
この研究のポイントは?
本論文の内容は、テキストから音声を生成する際の品質と効率を改善するために、「EzAudio」という新しいモデルを提案しています。
本研究のポイントは、以下の通りです。
つまり、EzAudioは効率的な音声生成を可能にし、他の生成モデルを超えるパフォーマンスを達成した研究です。
背景
これまでのテキストプロンプトからの音声生成において、従来のモデルでは、「2Dメルスペクトログラムを使って、音声を生成する手法」が主流でしたが、この方法は計算コストが高く、生成される音質が必ずしも良くないという問題がありました。
さらに、学習のための大規模なラベル付きデータが不足していることも、生成モデルの性能を低下させていました。
これらの問題を解決するために、EzAudioは1次元の波形データを扱うことで、より自然で高品質な音声を効率的に生成できるように設計されています。具体的には、従来の複雑な2D表現を避け、音声の生成と再構成をより簡単かつ効果的に行うDiffusion Transformerモデルを使用しています。
提案手法
EzAudioの提案手法では、まずテキスト入力をエンコーダーで処理し、その後、Latent Diffusion Modelを使って音声の潜在表現を生成します。最後に、この潜在表現をVAE(変分オートエンコーダー)デコーダーで復元し、実際の音声波形に変換します。
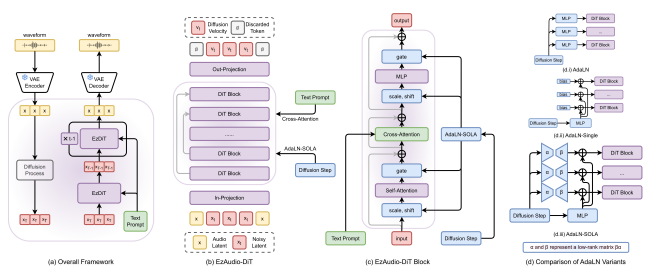
特に、Transformerモデル内におけるアーキテクチャが特徴的で、学習の安定性とメモリ使用の効率化を実現しています。具体的には、テキストエンコーダーからの出力を使って、音声の潜在表現を生成します。
特に、AdaLN-SOLA(Adaptive Layer Normalization with Single Orchestrated Low-rank Adjustment)という新しい層正規化手法が導入されており、モデルのトレーニング安定性を保ちながら、メモリ消費を抑えています。また、長スキップ接続を取り入れることで、低レベルの特徴が後続のTransformerブロックまで効率的に伝達されるようになっています
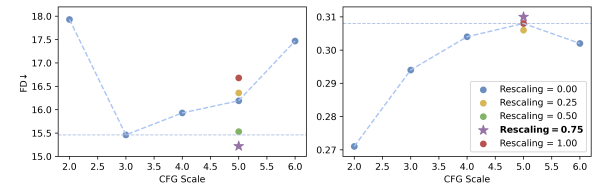
加えて、「Classifier-Free Guidance(CFG)」という手法を改良して、生成される音声とテキストの指示の一致度を向上させています。このCFGのスコアを再調整することで、音声の品質を保ちつつ、テキストとの整合性を高めることが可能となっています。
さらに、データ不足を補うため、未ラベルのデータを活用した自己教師あり学習や、人間によるラベル付けデータでのファインチューニングなど、多段階のトレーニング戦略を採用しています。このアプローチにより、少ないデータでも高い生成性能を維持し、トレーニングプロセス全体が効率的かつ簡素化されています。
実験
主な実験の目的は、従来の音声生成モデルと比較してEzAudioがどれだけ優れた性能を発揮するかを評価することです。
実験では、提案モデルのトレーニングと評価に24kHzの音声サンプルを使用し、学習にはAudioSetやAudioCapsなどのオープンソースのデータセットが利用されました。評価は、生成音声の品質やテキストと音声の一致度を測るため、Frechet Distance(FD)やKullback–Leibler(KL)ダイバージェンスなどの客観的な指標と主観的な評価を組み合わせています。
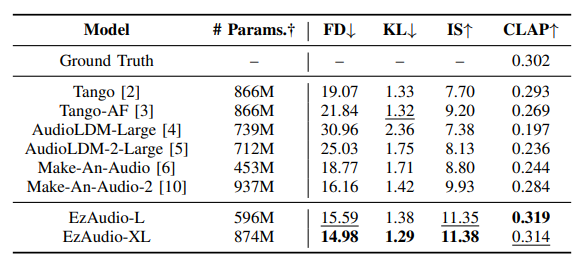
結果として、EzAudioは他の最新のテキストからの音声生成モデルと比較して、特に音声の質やテキストとの一致度で高い評価を得ました。具体的には、従来モデルよりも低いFD値と高いCLAPスコアを示し、音声のリアルさと指示との整合性が向上していることが確認されました。
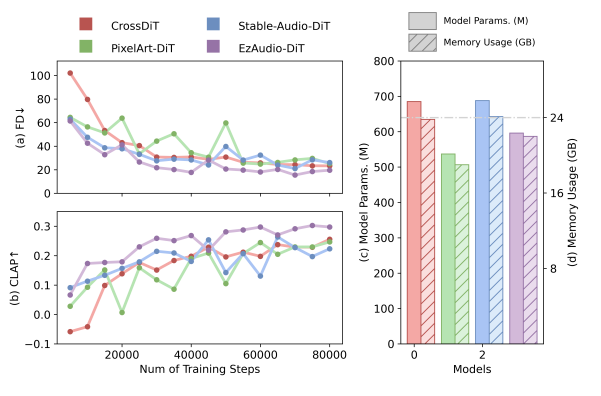
さらに、EzAudioは異なるDiffusion Transformerアーキテクチャとの比較でも、学習の安定性や収束の速さで他のモデルを上回り、少ないパラメータで効率的に動作することが実証されています。
結論
この論文の結論として、提案されたEzAudioは、テキストから高品質な音声を生成するための新しいアプローチで、これまでの手法に比べて効率的で使いやすいことが示されました。EzAudioは、1次元の波形データを活用し、計算コストを大幅に削減しながら、高い音声品質を維持しています。この技術により、従来のモデルのように複雑な処理を必要とせず、シンプルで効果的な音声生成が可能になりました。
また、実験結果から、EzAudioは他のオープンソースの音声生成モデルに対して優れた性能を示し、特にテキストとの整合性や音声のリアルさの点で顕著な改善が見られました。さらに、トレーニングの安定性や収束速度も向上しており、少ないパラメータで効率的に動作することが確認されました。このモデルは、音声生成だけでなく、将来的には動画から音声を生成するような応用分野にも展開可能性があるとされています。
EzAudioは、簡潔なトレーニングパイプラインと調整可能なガイダンス手法を組み合わせることで、高い品質の音声生成を実現しており、今後の音声生成技術の発展に大きな貢献をする可能性があります。