- 高速で効率的な音声生成を実現するTangoFloxの開発
- オープンデータセット利用による柔軟性向上と品質改善
- モデル構築におけるフラックス変換とCLAPランク付け最適化の採用
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
この研究では、音声生成モデルに焦点を当て、特にテキストから音声を生成(Text-to-Audio Generation; TTA)する技術において、効率的かつ高品質なモデル「TangoFlox」の設計が議論されています。
テキストから音声を生成するTTA技術は、多くの分野で役立つ可能性を秘めています。特に、創造的産業やコンテンツ制作、通信、ヘルスケアでは、生成された音声を音楽、効果音、または注意喚起のアラートとして利用する需要が高まっています。しかし、これまでのモデルにはいくつかの課題がありました。
- 計算コストの高さ: TTAモデルのほとんどは、大量の計算リソースを消費します。特に生成プロセスにおいて、モデルが各ステップごとに音声信号や特徴を細かく調整するには多額のコストがかかります。
- データへの依存: 従来のモデルは専用に収集されたプロプライエタリデータに依存することが多く、利用可能性が制限され、それが結果としてモデルの汎化能力を妨げます。
- 生成品質のばらつき: 現行モデルは十分な品質の音声を生成する能力が安定しておらず、生成される音声の忠実度(入力テキストに対してどれだけ一致しているか)も課題です。
TangoFloxモデルの概要
TangoFloxは、これらの課題を解決するために設計された新しいTTAモデルで、以下の特徴を備えています。
- Flox変換を基盤とする技術: Flow Matchingという計算効率が高い手法を採用することで、従来のTTAモデルに比べて約2倍の速さで音声生成が可能になりました。これにより、計算コストを劇的に削減しています。
- CLAP-ランク付け最適化(CRPO)の導入: 音声最適化プロセスにテキスト-オーディオ対応システム「CLAP」を活用し、生成音声の品質を向上させています。この仕組みにより、ユーザーの好みに合った音声生成を実現しています。
TangoFloxでは以下の重要なコンポーネントが実装されています。
1. FluxTransformerの使用:
このモデルは、Diffusion Transformer(DT)の一形態であり、Diffusionモデルの特徴を効率的に活用します。このアプローチにより、生成プロセス中に余計な計算ステップを省略しつつ、精度の高い音声データの生成を可能にしました。
2. テキストと音声条件付け:
生成される音声が与えられたテキスト入力に適していることを保証するため、TangoFloxはテキスト条件付けと音声条件付けの両方を組み合わせています。このプロセスでは、PT-3ベースのエンコーダーが利用され、テキスト特性が音声生成過程全体に反映されるようになっています。
3. CRPO(CLAP-Ranked Preference Optimization):
TTAモデルの忠実度と音声の品質向上を目的に、CLAPベースのスコアリング手法を最適化フレームワークに統合しました。この手法では、生成音声が入力テキストにどれほど適合しているかを評価し、それに基づいてモデルを改善していきます。
実験結果
TangoFloxの性能は、複数のベンチマークを用いた実験で検証されました。以下にその具体的な成果を示します。
1. 計算リソースと生成速度:他の最先端モデル(例: Stable DiffusionやAudioLDM)と比較した場合、TangoFloxは生成速度で約2倍の効率を示し、同じ計算パフォーマンスでさらに高品質な音声生成が可能となりました。
2. 音声品質評価:CLAPスコアおよび人間評価によるリスニングテストの結果、TangoFloxは従来のモデルに比べて大幅に優れていると評価されました。特に音声の忠実度(KL分散)と質の高さにおいてこのモデルは強みを持ちます。
3. モデルの汎用性:モデルは既存オープンデータセットを用いてトレーニングされ、幅広いサウンドスケープ(自然音、人工音、音楽など)の再現に成功しました。通常、プロプライエタリデータを必要とした従来モデルに比べ大きな進展です。
図表の解説
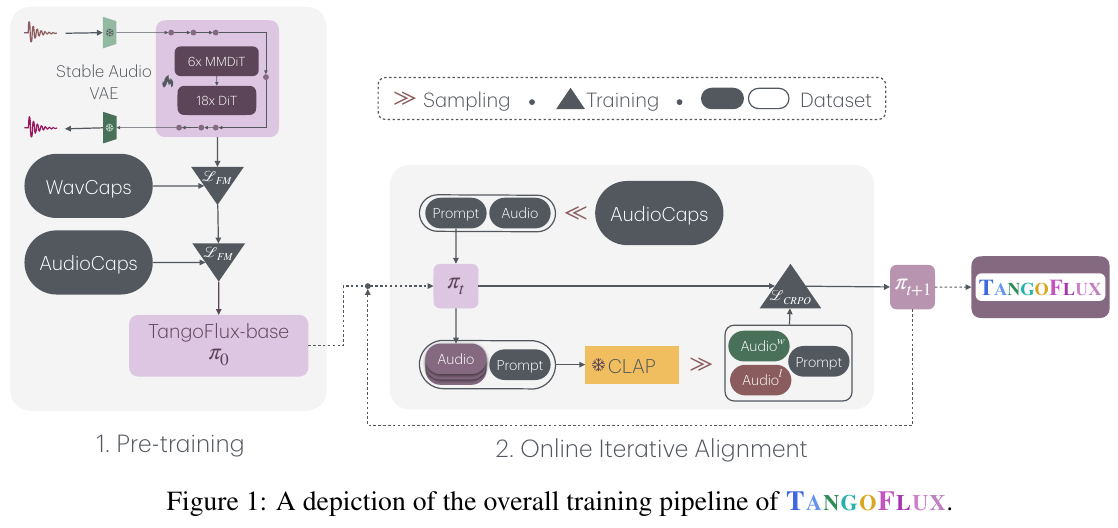
図は、テキストからオーディオへの生成モデル「TANGOFLUX」の全体的な学習パイプラインを示しています。
事前学習では、「Stable Audio VAE」を使用してオーディオを潜在的な表現に変換し、「WavCaps」と「AudioCaps」データセットを用いて、基盤となるモデル「TangoFlux-base」を学習します。
オンライン反復アライメントでは、入力テキスト(プロンプト)とオーディオデータを使い、CLAPモデルにより生成されたオーディオの品質を評価し、好みを最適化します。CLAPによるスコアに基づいてオーディオをランク付けし、最適化のフィードバックを行います。 最終的に、「TANGOFLUX」モデルは精緻なオーディオ生成を達成し、ユーザーの好みに合わせて調整されます。
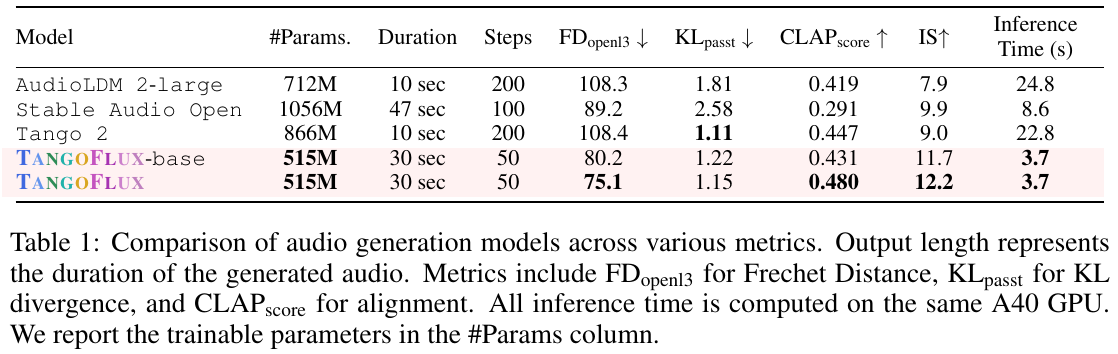
この表は、テキストから音声を生成するモデルの性能を比較しています。TANGOFLUXという新しいモデルを含むいくつかのモデルが対象です。各モデルのパラメータ数、生成する音声の長さ、ステップ数、フレシェ距離(FDopenl3)、KLダイバージェンス(KLpasst)、CLAPスコア、インセプションスコア(IS)、そして推論時間が評価されています。 TANGOFLUXは特に速く、高品質の音声を生成する能力に優れており、他のモデルと比べて半分以下のパラメータ数でも高いCLAPスコアと短い推論時間を達成しています。そのため、効率的かつ効果的な音声生成において優れた選択肢といえます。
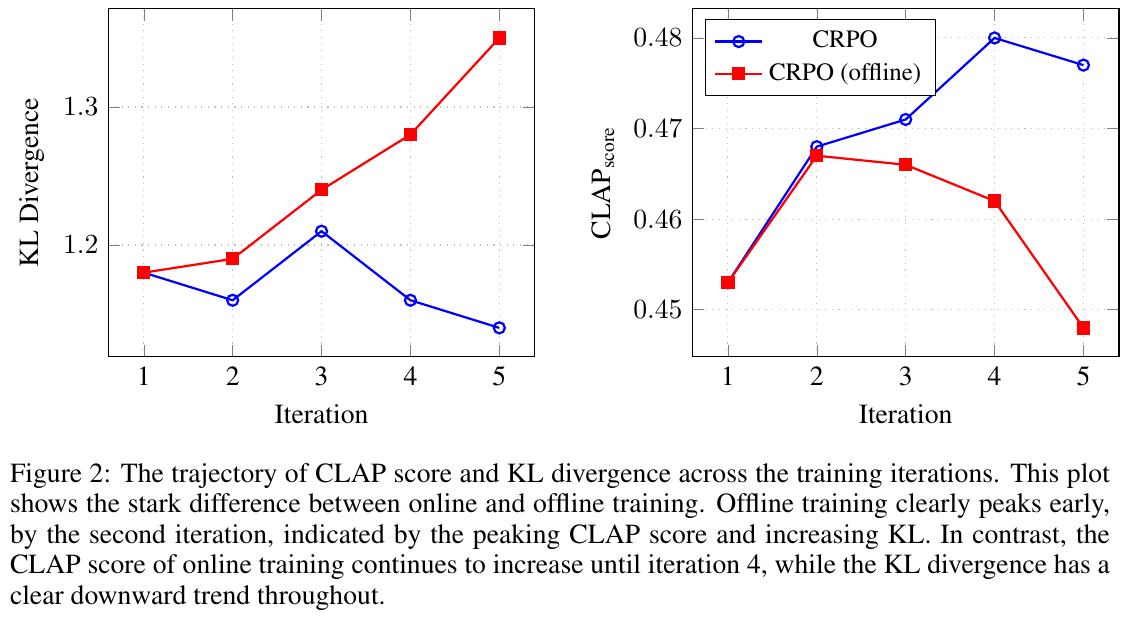
この図は、オンラインとオフラインのCRPO(CLAP-Ranked Preference Optimization)トレーニングの違いを示しています。
左側のグラフはKLダイバージェンスの変化を表し、右側のグラフはCLAPスコアの変化を表しています。 オンラインCRPOでは、トレーニングの反復ごとにCLAPスコアが向上し、1から4回目の反復にかけて上昇し続ける一方で、KLダイバージェンスは減少傾向にあります。オフラインCRPOでは、2回目の反復でCLAPスコアがピークに達した後に減少し、KLダイバージェンスが増加していることが示されています。このことから、オンラインで新しいデータを生成することが、より効果的なトレーニングにつながることが示唆されています。
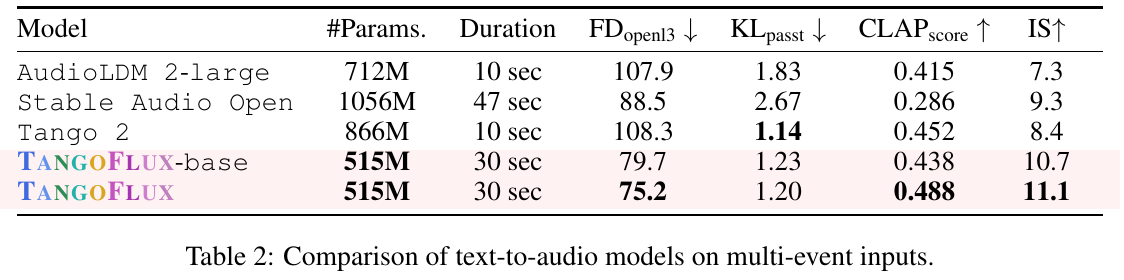
この図表は、テキストから音声への変換モデルの性能を比較したものです。モデルごとのパラメータ数、生成音声の長さ、評価指標(FDopenl3、KLpasst、CLAPscore、IS)が示されています。
TANGOFLUXモデルは、他のモデルに比べて高い性能を発揮しています。特にCLAPscoreとISの数値が高く、音声の質やテキストとの関連性が優れています。
ANGOFLUXは最大30秒の音声を生成でき、他のモデルと性能を比較した際にはバランスが良いとされています。
FDopenl3はモデルの生成音声と参照音声の類似度を測る指標で、数値が小さいほど高いリアリティを意味します。KLpasstは音声生成の語義的な整合性を示し、低いほど良いです。CLAPscoreは生成音声とテキストの一致度を測り、数値が高いほど一致度が高いことを意味します。ISは生成音声の多様性を測定し、こちらも高い方が良いです。
この表から、TANGOFLUXは特に多イベントの入力に対して優れた性能を持つことが分かります。
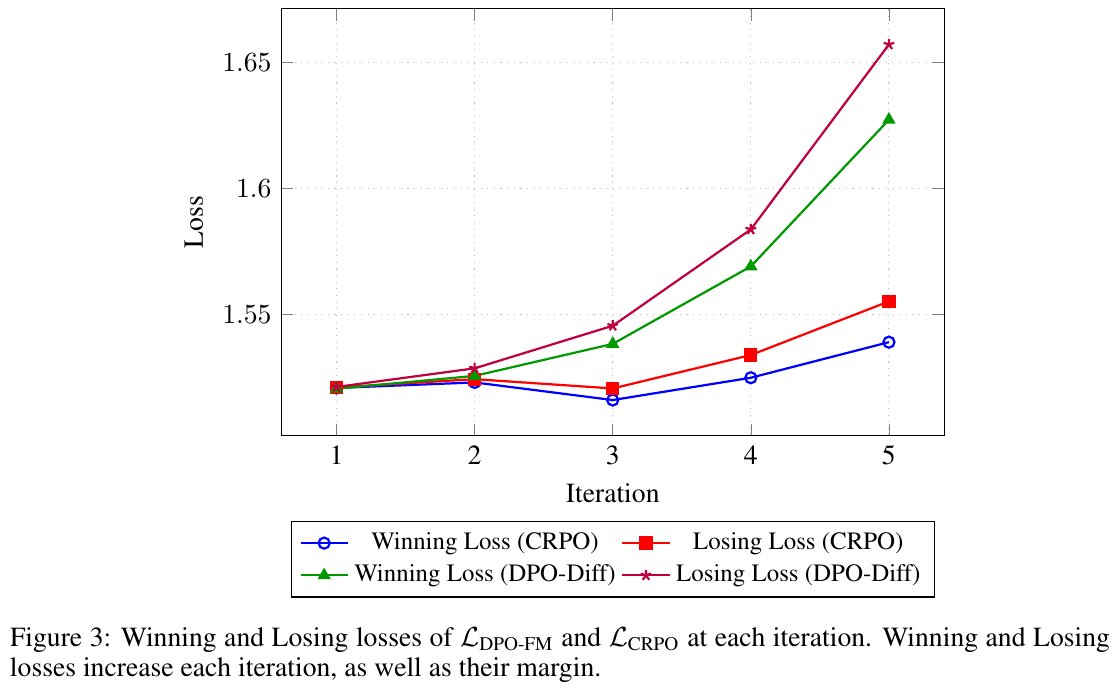
図は、5回のイテレーションにおける損失(Loss)の変化を示しています。ここで損失は機械学習モデルのパフォーマンス指標の一つで、値が低いほどモデルの予測が正確であることを意味します。この図表は、「Winning Loss」と「Losing Loss」を2つの手法(CRPOとDPO-Diff)で比較しています。 グラフを見ると、イテレーションが進むにつれて、すべての損失が増加していることがわかります。また、Winning Loss(青と緑)はLosing Loss(赤とピンク)よりも低く維持されています。これは、モデルがより良い予測を行うことを示しています。特に、DPO-Diff手法では、損失が大きく増加していることから、CRPOの方が安定したパフォーマンスを持つ可能性があります。結論として、この分析はモデルチューニングの一部として重要な洞察を提供します。